 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSybil-based Virtual Data Poisoning Attacks in Federated Learning
May 15, 2025



Federated learning is vulnerable to poisoning attacks by malicious adversaries. Existing methods often involve high costs to achieve effective attacks. To address this challenge, we propose a sybil-based virtual data poisoning attack, where a malicious client generates sybil nodes to amplify the poisoning model's impact. To reduce neural network computational complexity, we develop a virtual data generation method based on gradient matching. We also design three schemes for target model acquisition, applicable to online local, online global, and offline scenarios. In simulation, our method outperforms other attack algorithms since our method can obtain a global target model under non-independent uniformly distributed data.
GMFlow: Global Motion-Guided Recurrent Flow for 6D Object Pose Estimation
Nov 26, 2024



6D object pose estimation is crucial for robotic perception and precise manipulation. Occlusion and incomplete object visibility are common challenges in this task, but existing pose refinement methods often struggle to handle these issues effectively. To tackle this problem, we propose a global motion-guided recurrent flow estimation method called GMFlow for pose estimation. GMFlow overcomes local ambiguities caused by occlusion or missing parts by seeking global explanations. We leverage the object's structural information to extend the motion of visible parts of the rigid body to its invisible regions. Specifically, we capture global contextual information through a linear attention mechanism and guide local motion information to generate global motion estimates. Furthermore, we introduce object shape constraints in the flow iteration process, making flow estimation suitable for pose estimation scenarios. Experiments on the LM-O and YCB-V datasets demonstrate that our method outperforms existing techniques in accuracy while maintaining competitive computational efficiency.
SEMPose: A Single End-to-end Network for Multi-object Pose Estimation
Nov 21, 2024



In computer vision, estimating the six-degree-of-freedom pose from an RGB image is a fundamental task. However, this task becomes highly challenging in multi-object scenes. Currently, the best methods typically employ an indirect strategy, which identifies 2D and 3D correspondences, and then solves with the Perspective-n-Points method. Yet, this approach cannot be trained end-to-end. Direct methods, on the other hand, suffer from lower accuracy due to challenges such as varying object sizes and occlusions. To address these issues, we propose SEMPose, an end-to-end multi-object pose estimation network. SEMPose utilizes a well-designed texture-shape guided feature pyramid network, effectively tackling the challenge of object size variations. Additionally, it employs an iterative refinement head structure, progressively regressing rotation and translation separately to enhance estimation accuracy. During training, we alleviate the impact of occlusion by selecting positive samples from visible parts. Experimental results demonstrate that SEMPose can perform inference at 32 FPS without requiring inputs other than the RGB image. It can accurately estimate the poses of multiple objects in real time, with inference time unaffected by the number of target objects. On the LM-O and YCB-V datasets, our method outperforms other RGB-based single-model methods, achieving higher accuracy. Even when compared with multi-model methods and approaches that use additional refinement, our results remain competitive.
HRPose: Real-Time High-Resolution 6D Pose Estimation Network Using Knowledge Distillation
Apr 20, 2022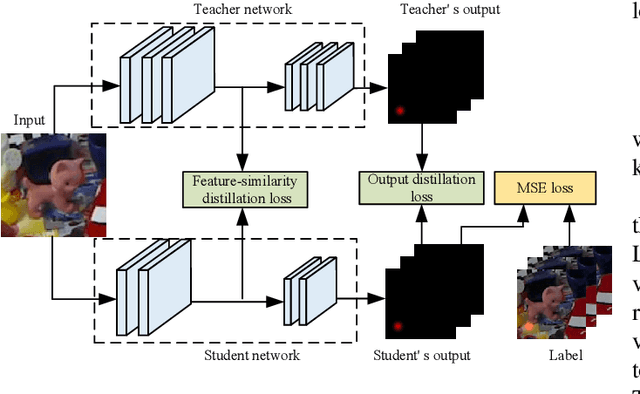
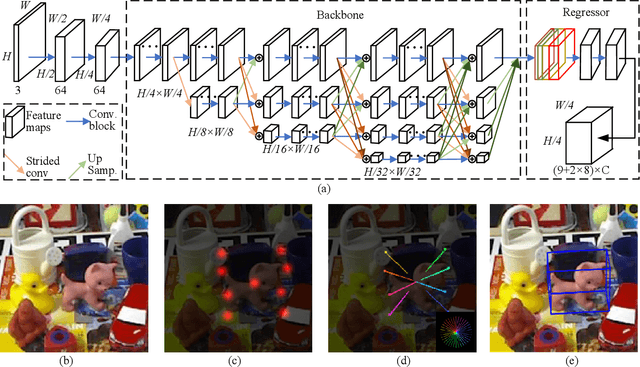


Real-time 6D object pose estimation is essential for many real-world applications, such as robotic grasping and augmented reality. To achieve an accurate object pose estimation from RGB images in real-time, we propose an effective and lightweight model, namely High-Resolution 6D Pose Estimation Network (HRPose). We adopt the efficient and small HRNetV2-W18 as a feature extractor to reduce computational burdens while generating accurate 6D poses. With only 33\% of the model size and lower computational costs, our HRPose achieves comparable performance compared with state-of-the-art models. Moreover, by transferring knowledge from a large model to our proposed HRPose through output and feature-similarity distillations, the performance of our HRPose is improved in effectiveness and efficiency. Numerical experiments on the widely-used benchmark LINEMOD demonstrate the superiority of our proposed HRPose against state-of-the-art methods.
Global Update Guided Federated Learning
Apr 08, 2022


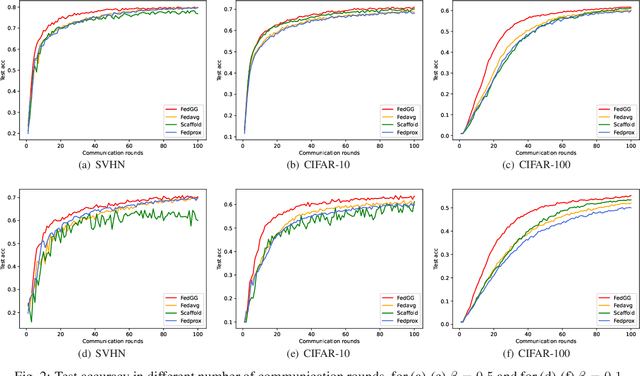
Federated learning protects data privacy and security by exchanging models instead of data. However, unbalanced data distributions among participating clients compromise the accuracy and convergence speed of federated learning algorithms. To alleviate this problem, unlike previous studies that limit the distance of updates for local models, we propose global-update-guided federated learning (FedGG), which introduces a model-cosine loss into local objective functions, so that local models can fit local data distributions under the guidance of update directions of global models. Furthermore, considering that the update direction of a global model is informative in the early stage of training, we propose adaptive loss weights based on the update distances of local models. Numerical simulations show that, compared with other advanced algorithms, FedGG has a significant improvement on model convergence accuracies and speeds. Additionally, compared with traditional fixed loss weights, adaptive loss weights enable our algorithm to be more stable and easier to implement in practice.
A Cooperation-Aware Lane Change Method for Autonomous Vehicles
Jan 26, 2022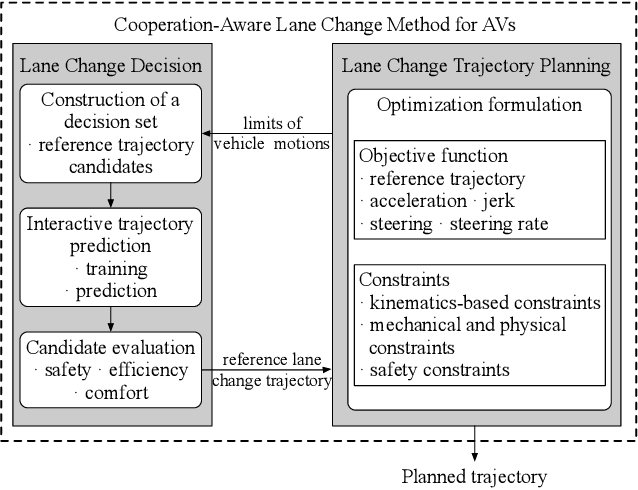
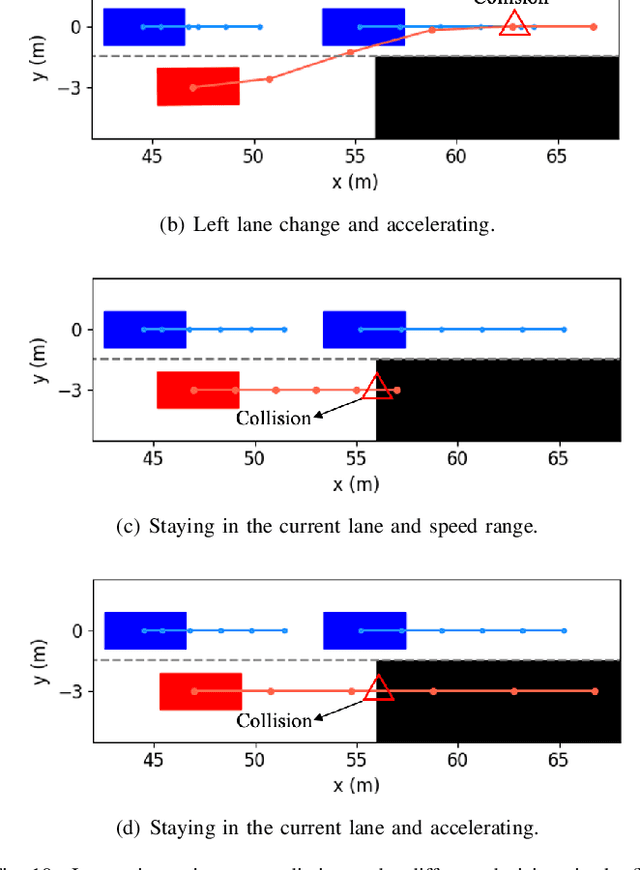
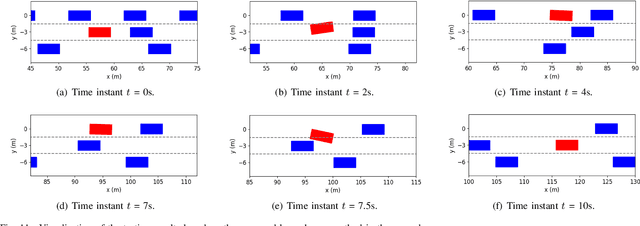
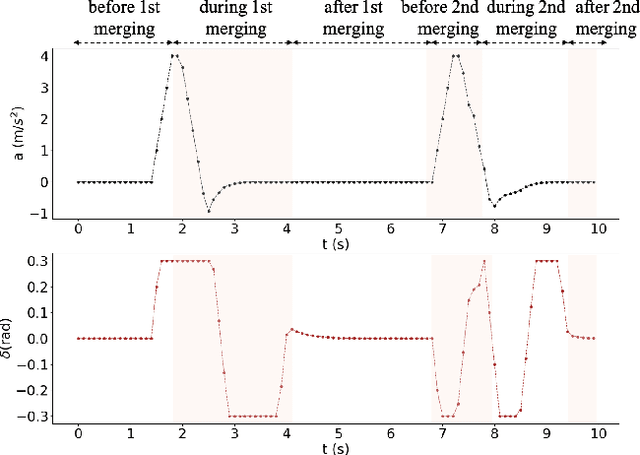
Lane change for autonomous vehicles (AVs) is an important but challenging task in complex dynamic traffic environments. Due to difficulties in guarantee safety as well as a high efficiency, AVs are inclined to choose relatively conservative strategies for lane change. To avoid the conservatism, this paper presents a cooperation-aware lane change method utilizing interactions between vehicles. We first propose an interactive trajectory prediction method to explore possible cooperations between an AV and the others. Further, an evaluation is designed to make a decision on lane change, in which safety, efficiency and comfort are taken into consideration. Thereafter, we propose a motion planning algorithm based on model predictive control (MPC), which incorporates AV's decision and surrounding vehicles' interactive behaviors into constraints so as to avoid collisions during lane change. Quantitative testing results show that compared with the methods without an interactive prediction, our method enhances driving efficiencies of the AV and other vehicles by 14.8$\%$ and 2.6$\%$ respectively, which indicates that a proper utilization of vehicle interactions can effectively reduce the conservatism of the AV and promote the cooperation between the AV and others.
Graph-Based Spatial-Temporal Convolutional Network for Vehicle Trajectory Prediction in Autonomous Driving
Sep 27, 2021



Forecasting the trajectories of neighbor vehicles is a crucial step for decision making and motion planning of autonomous vehicles. This paper proposes a graph-based spatial-temporal convolutional network (GSTCN) to predict future trajectory distributions of all neighbor vehicles using past trajectories. This network tackles the spatial interactions using a graph convolutional network (GCN), and captures the temporal features with a convolutional neural network (CNN). The spatial-temporal features are encoded and decoded by a gated recurrent unit (GRU) network to generate future trajectory distributions. Besides, we propose a weighted adjacency matrix to describe the intensities of mutual influence between vehicles, and the ablation study demonstrates the effectiveness of our proposed scheme. Our network is evaluated on two real-world freeway trajectory datasets: I-80 and US-101 in the Next Generation Simulation (NGSIM).Comparisons in three aspects, including prediction errors, model sizes, and inference speeds, show that our network can achieve state-of-the-art performance.