 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Energy-Inspired Cognitive Risk Integration for AV Navigation in Pedestrian-Rich Environments
Jul 28, 2025



Recent advances in autonomous vehicle (AV) behavior planning have shown impressive social interaction capabilities when interacting with other road users. However, achieving human-like prediction and decision-making in interactions with vulnerable road users remains a key challenge in complex multi-agent interactive environments. Existing research focuses primarily on crowd navigation for small mobile robots, which cannot be directly applied to AVs due to inherent differences in their decision-making strategies and dynamic boundaries. Moreover, pedestrians in these multi-agent simulations follow fixed behavior patterns that cannot dynamically respond to AV actions. To overcome these limitations, this paper proposes a novel framework for modeling interactions between the AV and multiple pedestrians. In this framework, a cognitive process modeling approach inspired by the Free Energy Principle is integrated into both the AV and pedestrian models to simulate more realistic interaction dynamics. Specifically, the proposed pedestrian Cognitive-Risk Social Force Model adjusts goal-directed and repulsive forces using a fused measure of cognitive uncertainty and physical risk to produce human-like trajectories. Meanwhile, the AV leverages this fused risk to construct a dynamic, risk-aware adjacency matrix for a Graph Convolutional Network within a Soft Actor-Critic architecture, allowing it to make more reasonable and informed decisions. Simulation results indicate that our proposed framework effectively improves safety, efficiency, and smoothness of AV navigation compared to the state-of-the-art method.
Evaluating Scenario-based Decision-making for Interactive Autonomous Driving Using Rational Criteria: A Survey
Jan 03, 2025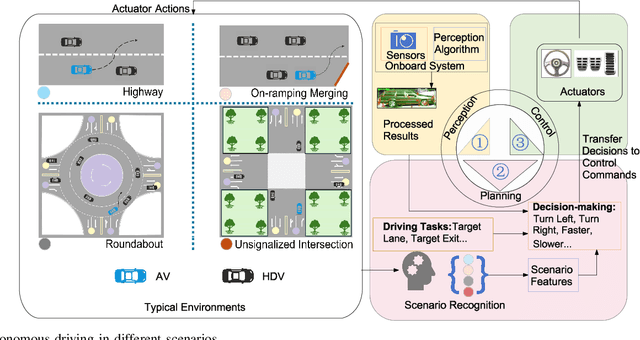
Autonomous vehicles (AVs) can significantly promote the advances in road transport mobility in terms of safety, reliability, and decarbonization. However, ensuring safety and efficiency in interactive during within dynamic and diverse environments is still a primary barrier to large-scale AV adoption. In recent years, deep reinforcement learning (DRL) has emerged as an advanced AI-based approach, enabling AVs to learn decision-making strategies adaptively from data and interactions. DRL strategies are better suited than traditional rule-based methods for handling complex, dynamic, and unpredictable driving environments due to their adaptivity. However, varying driving scenarios present distinct challenges, such as avoiding obstacles on highways and reaching specific exits at intersections, requiring different scenario-specific decision-making algorithms. Many DRL algorithms have been proposed in interactive decision-making. However, a rationale review of these DRL algorithms across various scenarios is lacking. Therefore, a comprehensive evaluation is essential to assess these algorithms from multiple perspectives, including those of vehicle users and vehicle manufacturers. This survey reviews the application of DRL algorithms in autonomous driving across typical scenarios, summarizing road features and recent advancements. The scenarios include highways, on-ramp merging, roundabouts, and unsignalized intersections. Furthermore, DRL-based algorithms are evaluated based on five rationale criteria: driving safety, driving efficiency, training efficiency, unselfishness, and interpretability (DDTUI). Each criterion of DDTUI is specifically analyzed in relation to the reviewed algorithms. Finally, the challenges for future DRL-based decision-making algorithms are summarized.
GMFlow: Global Motion-Guided Recurrent Flow for 6D Object Pose Estimation
Nov 26, 2024



6D object pose estimation is crucial for robotic perception and precise manipulation. Occlusion and incomplete object visibility are common challenges in this task, but existing pose refinement methods often struggle to handle these issues effectively. To tackle this problem, we propose a global motion-guided recurrent flow estimation method called GMFlow for pose estimation. GMFlow overcomes local ambiguities caused by occlusion or missing parts by seeking global explanations. We leverage the object's structural information to extend the motion of visible parts of the rigid body to its invisible regions. Specifically, we capture global contextual information through a linear attention mechanism and guide local motion information to generate global motion estimates. Furthermore, we introduce object shape constraints in the flow iteration process, making flow estimation suitable for pose estimation scenarios. Experiments on the LM-O and YCB-V datasets demonstrate that our method outperforms existing techniques in accuracy while maintaining competitive computational efficiency.
SEMPose: A Single End-to-end Network for Multi-object Pose Estimation
Nov 21, 2024



In computer vision, estimating the six-degree-of-freedom pose from an RGB image is a fundamental task. However, this task becomes highly challenging in multi-object scenes. Currently, the best methods typically employ an indirect strategy, which identifies 2D and 3D correspondences, and then solves with the Perspective-n-Points method. Yet, this approach cannot be trained end-to-end. Direct methods, on the other hand, suffer from lower accuracy due to challenges such as varying object sizes and occlusions. To address these issues, we propose SEMPose, an end-to-end multi-object pose estimation network. SEMPose utilizes a well-designed texture-shape guided feature pyramid network, effectively tackling the challenge of object size variations. Additionally, it employs an iterative refinement head structure, progressively regressing rotation and translation separately to enhance estimation accuracy. During training, we alleviate the impact of occlusion by selecting positive samples from visible parts. Experimental results demonstrate that SEMPose can perform inference at 32 FPS without requiring inputs other than the RGB image. It can accurately estimate the poses of multiple objects in real time, with inference time unaffected by the number of target objects. On the LM-O and YCB-V datasets, our method outperforms other RGB-based single-model methods, achieving higher accuracy. Even when compared with multi-model methods and approaches that use additional refinement, our results remain competitive.
Trustworthy Text-to-Image Diffusion Models: A Timely and Focused Survey
Sep 26, 2024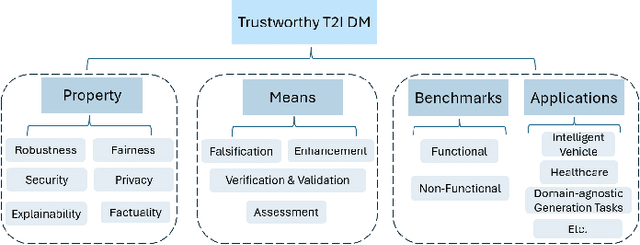
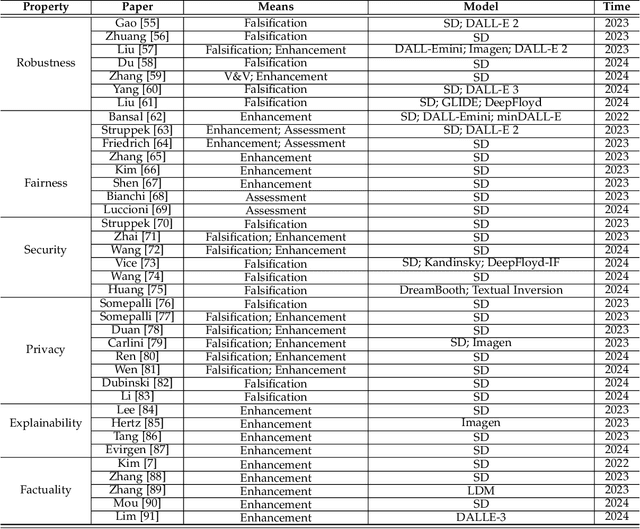
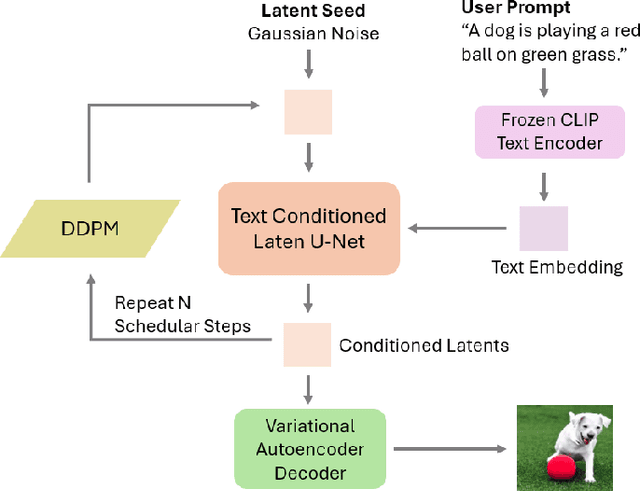
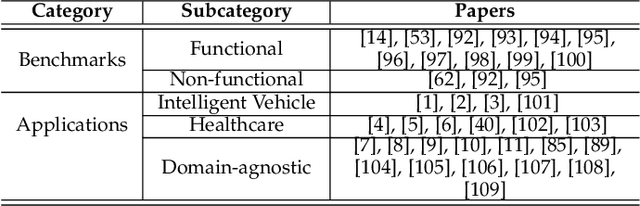
Text-to-Image (T2I) Diffusion Models (DMs) have garnered widespread attention for their impressive advancements in image generation. However, their growing popularity has raised ethical and social concerns related to key non-functional properties of trustworthiness, such as robustness, fairness, security, privacy, factuality, and explainability, similar to those in traditional deep learning (DL) tasks. Conventional approaches for studying trustworthiness in DL tasks often fall short due to the unique characteristics of T2I DMs, e.g., the multi-modal nature. Given the challenge, recent efforts have been made to develop new methods for investigating trustworthiness in T2I DMs via various means, including falsification, enhancement, verification \& validation and assessment. However, there is a notable lack of in-depth analysis concerning those non-functional properties and means. In this survey, we provide a timely and focused review of the literature on trustworthy T2I DMs, covering a concise-structured taxonomy from the perspectives of property, means, benchmarks and applications. Our review begins with an introduction to essential preliminaries of T2I DMs, and then we summarise key definitions/metrics specific to T2I tasks and analyses the means proposed in recent literature based on these definitions/metrics. Additionally, we review benchmarks and domain applications of T2I DMs. Finally, we highlight the gaps in current research, discuss the limitations of existing methods, and propose future research directions to advance the development of trustworthy T2I DMs. Furthermore, we keep up-to-date updates in this field to track the latest developments and maintain our GitHub repository at: https://github.com/wellzline/Trustworthy_T2I_DMs
Multi-scale Feature Fusion with Point Pyramid for 3D Object Detection
Sep 06, 2024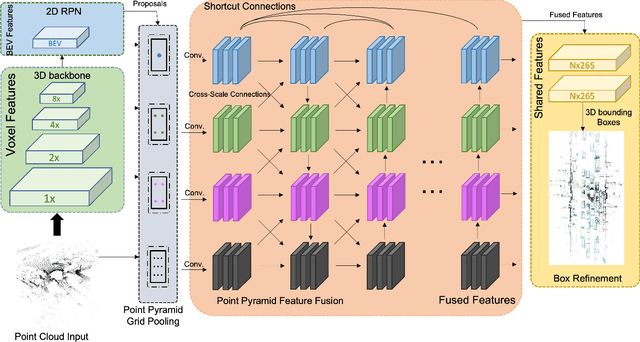
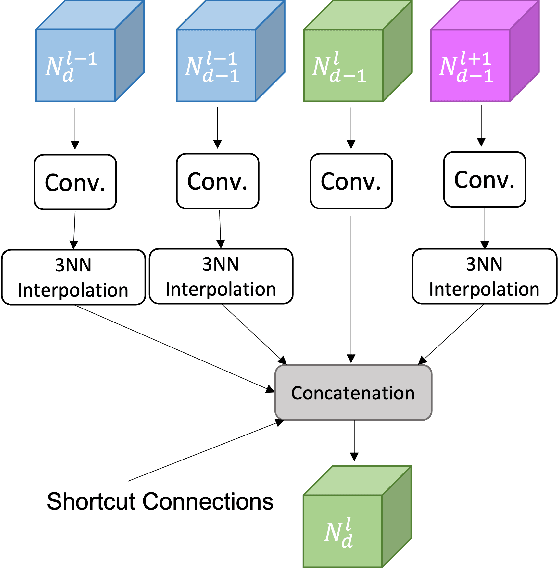
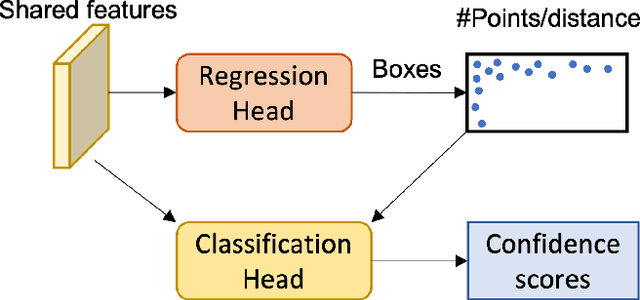

Effective point cloud processing is crucial to LiDARbased autonomous driving systems. The capability to understand features at multiple scales is required for object detection of intelligent vehicles, where road users may appear in different sizes. Recent methods focus on the design of the feature aggregation operators, which collect features at different scales from the encoder backbone and assign them to the points of interest. While efforts are made into the aggregation modules, the importance of how to fuse these multi-scale features has been overlooked. This leads to insufficient feature communication across scales. To address this issue, this paper proposes the Point Pyramid RCNN (POP-RCNN), a feature pyramid-based framework for 3D object detection on point clouds. POP-RCNN consists of a Point Pyramid Feature Enhancement (PPFE) module to establish connections across spatial scales and semantic depths for information exchange. The PPFE module effectively fuses multi-scale features for rich information without the increased complexity in feature aggregation. To remedy the impact of inconsistent point densities, a point density confidence module is deployed. This design integration enables the use of a lightweight feature aggregator, and the emphasis on both shallow and deep semantics, realising a detection framework for 3D object detection. With great adaptability, the proposed method can be applied to a variety of existing frameworks to increase feature richness, especially for long-distance detection. By adopting the PPFE in the voxel-based and point-voxel-based baselines, experimental results on KITTI and Waymo Open Dataset show that the proposed method achieves remarkable performance even with limited computational headroom.
Generative AI-driven Semantic Communication Networks: Architecture, Technologies and Applications
Jan 07, 2024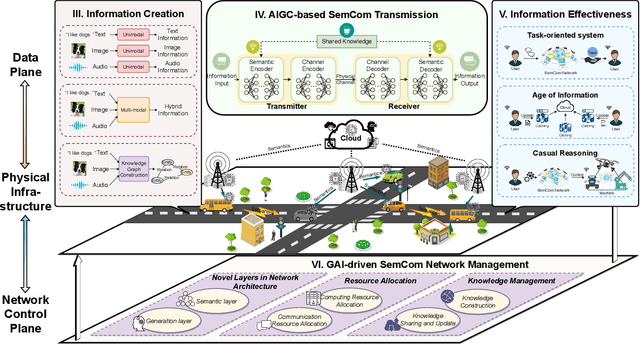
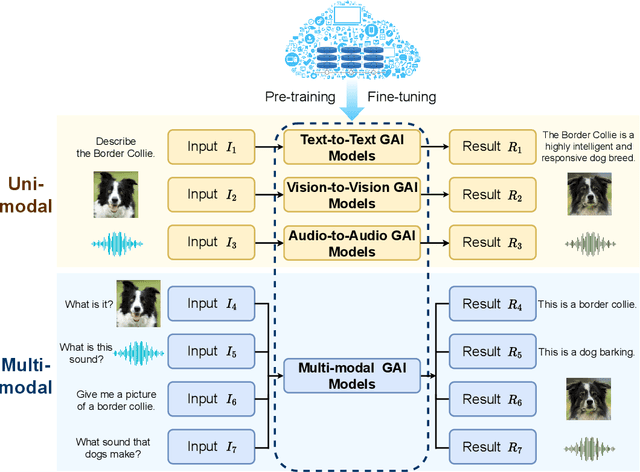
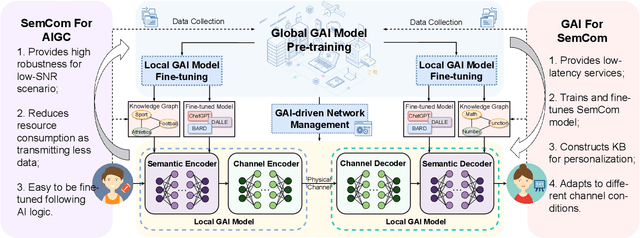
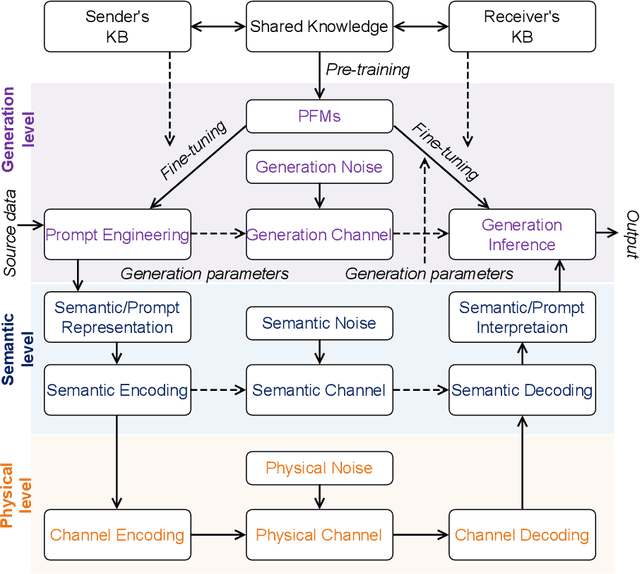
Generative artificial intelligence (GAI) has emerged as a rapidly burgeoning field demonstrating significant potential in creating diverse contents intelligently and automatically. To support such artificial intelligence-generated content (AIGC) services, future communication systems should fulfill much more stringent requirements (including data rate, throughput, latency, etc.) with limited yet precious spectrum resources. To tackle this challenge, semantic communication (SemCom), dramatically reducing resource consumption via extracting and transmitting semantics, has been deemed as a revolutionary communication scheme. The advanced GAI algorithms facilitate SemCom on sophisticated intelligence for model training, knowledge base construction and channel adaption. Furthermore, GAI algorithms also play an important role in the management of SemCom networks. In this survey, we first overview the basics of GAI and SemCom as well as the synergies of the two technologies. Especially, the GAI-driven SemCom framework is presented, where many GAI models for information creation, SemCom-enabled information transmission and information effectiveness for AIGC are discussed separately. We then delve into the GAI-driven SemCom network management involving with novel management layers, knowledge management, and resource allocation. Finally, we envision several promising use cases, i.e., autonomous driving, smart city, and the Metaverse for a more comprehensive exploration.
Empirical Analysis of AI-based Energy Management in Electric Vehicles: A Case Study on Reinforcement Learning
Dec 18, 2022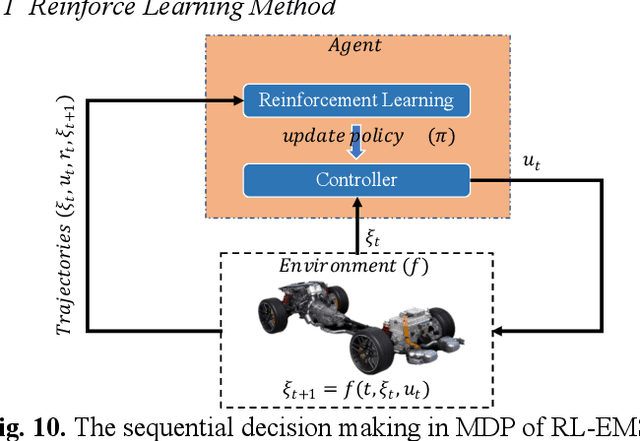
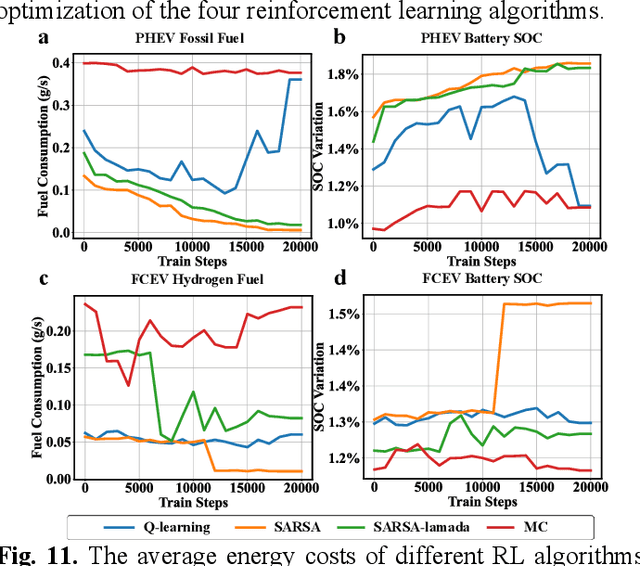
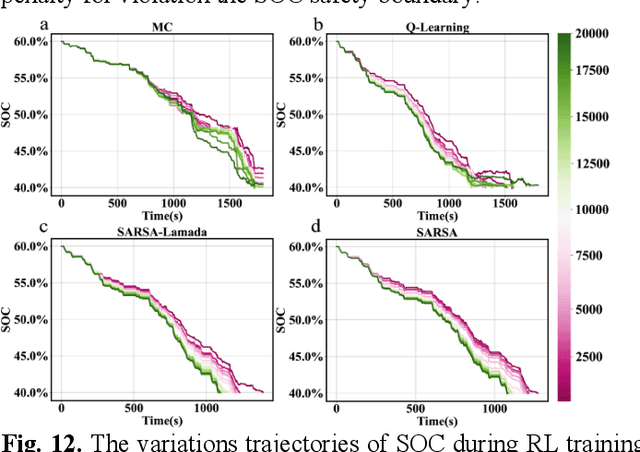
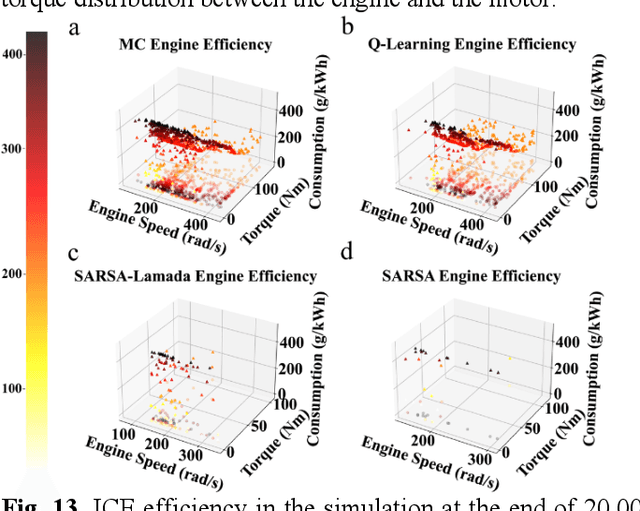
Reinforcement learning-based (RL-based) energy management strategy (EMS) is considered a promising solution for the energy management of electric vehicles with multiple power sources. It has been shown to outperform conventional methods in energy management problems regarding energy-saving and real-time performance. However, previous studies have not systematically examined the essential elements of RL-based EMS. This paper presents an empirical analysis of RL-based EMS in a Plug-in Hybrid Electric Vehicle (PHEV) and Fuel Cell Electric Vehicle (FCEV). The empirical analysis is developed in four aspects: algorithm, perception and decision granularity, hyperparameters, and reward function. The results show that the Off-policy algorithm effectively develops a more fuel-efficient solution within the complete driving cycle compared with other algorithms. Improving the perception and decision granularity does not produce a more desirable energy-saving solution but better balances battery power and fuel consumption. The equivalent energy optimization objective based on the instantaneous state of charge (SOC) variation is parameter sensitive and can help RL-EMSs to achieve more efficient energy-cost strategies.
A Cooperation-Aware Lane Change Method for Autonomous Vehicles
Jan 26, 2022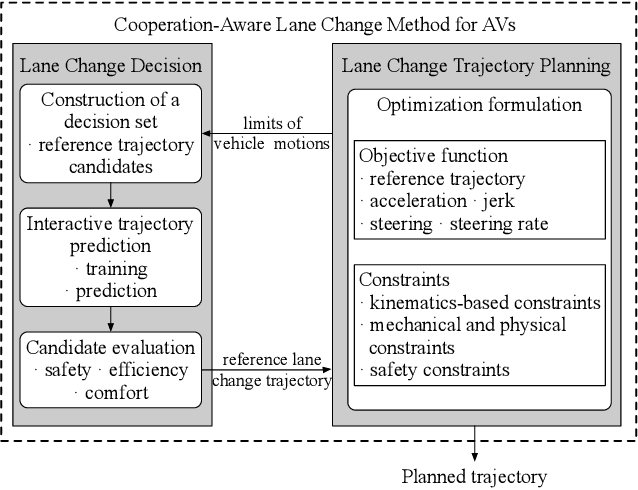
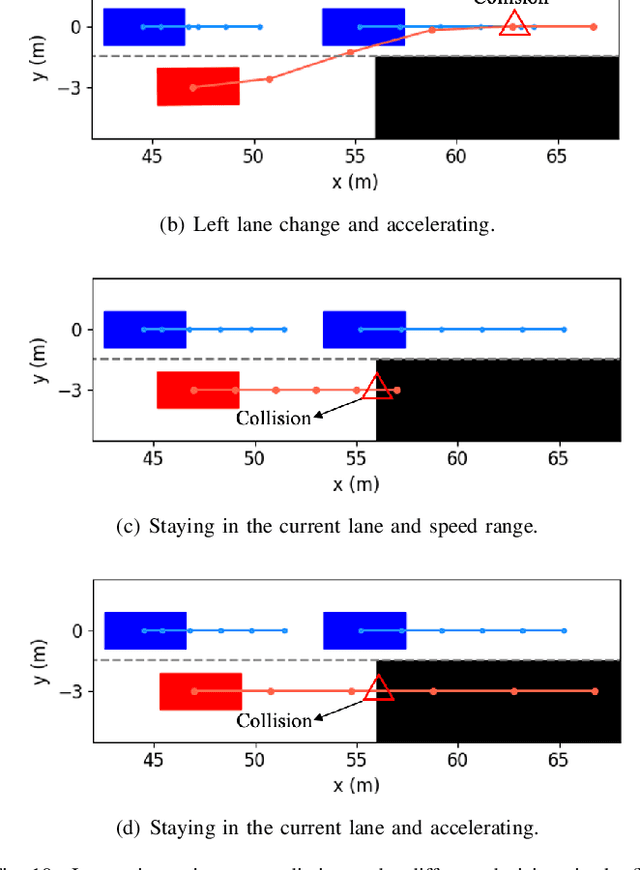
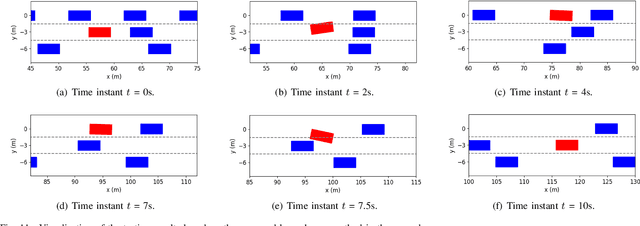
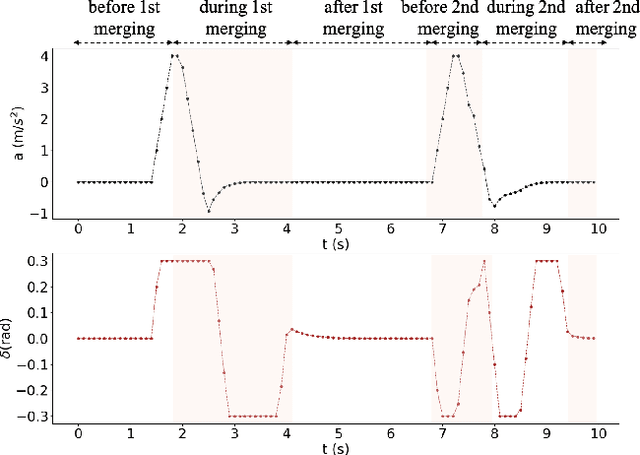
Lane change for autonomous vehicles (AVs) is an important but challenging task in complex dynamic traffic environments. Due to difficulties in guarantee safety as well as a high efficiency, AVs are inclined to choose relatively conservative strategies for lane change. To avoid the conservatism, this paper presents a cooperation-aware lane change method utilizing interactions between vehicles. We first propose an interactive trajectory prediction method to explore possible cooperations between an AV and the others. Further, an evaluation is designed to make a decision on lane change, in which safety, efficiency and comfort are taken into consideration. Thereafter, we propose a motion planning algorithm based on model predictive control (MPC), which incorporates AV's decision and surrounding vehicles' interactive behaviors into constraints so as to avoid collisions during lane change. Quantitative testing results show that compared with the methods without an interactive prediction, our method enhances driving efficiencies of the AV and other vehicles by 14.8$\%$ and 2.6$\%$ respectively, which indicates that a proper utilization of vehicle interactions can effectively reduce the conservatism of the AV and promote the cooperation between the AV and others.