 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Feature Fusion with Point Pyramid for 3D Object Detection
Sep 06, 2024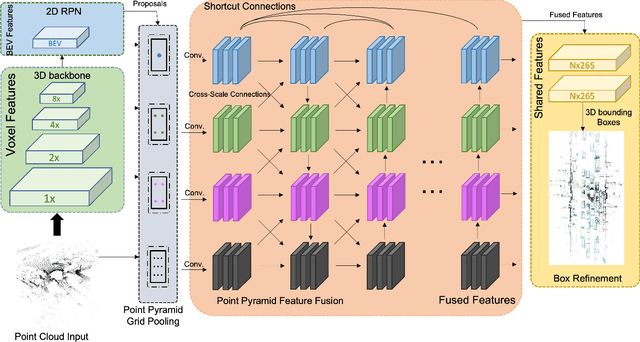
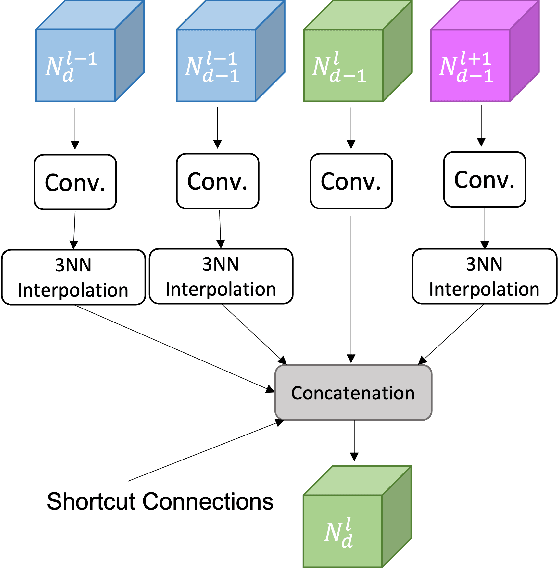
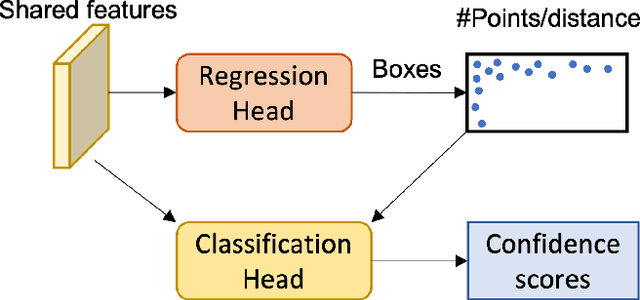

Effective point cloud processing is crucial to LiDARbased autonomous driving systems. The capability to understand features at multiple scales is required for object detection of intelligent vehicles, where road users may appear in different sizes. Recent methods focus on the design of the feature aggregation operators, which collect features at different scales from the encoder backbone and assign them to the points of interest. While efforts are made into the aggregation modules, the importance of how to fuse these multi-scale features has been overlooked. This leads to insufficient feature communication across scales. To address this issue, this paper proposes the Point Pyramid RCNN (POP-RCNN), a feature pyramid-based framework for 3D object detection on point clouds. POP-RCNN consists of a Point Pyramid Feature Enhancement (PPFE) module to establish connections across spatial scales and semantic depths for information exchange. The PPFE module effectively fuses multi-scale features for rich information without the increased complexity in feature aggregation. To remedy the impact of inconsistent point densities, a point density confidence module is deployed. This design integration enables the use of a lightweight feature aggregator, and the emphasis on both shallow and deep semantics, realising a detection framework for 3D object detection. With great adaptability, the proposed method can be applied to a variety of existing frameworks to increase feature richness, especially for long-distance detection. By adopting the PPFE in the voxel-based and point-voxel-based baselines, experimental results on KITTI and Waymo Open Dataset show that the proposed method achieves remarkable performance even with limited computational headroom.
Causality from Bottom to Top: A Survey
Mar 17, 2024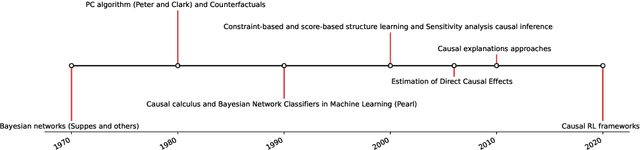



Causality has become a fundamental approach for explaining the relationships between events, phenomena, and outcomes in various fields of study. It has invaded various fields and applications, such as medicine, healthcare, economics, finance, fraud detection, cybersecurity, education, public policy, recommender systems, anomaly detection, robotics, control, sociology, marketing, and advertising. In this paper, we survey its development over the past five decades, shedding light on the differences between causality and other approaches, as well as the preconditions for using it. Furthermore, the paper illustrates how causality interacts with new approaches such as Artificial Intelligence (AI), Generative AI (GAI), Machine and Deep Learning, Reinforcement Learning (RL), and Fuzzy Logic. We study the impact of causality on various fields, its contribution, and its interaction with state-of-the-art approaches. Additionally, the paper exemplifies the trustworthiness and explainability of causality models. We offer several ways to evaluate causality models and discuss future directions.
A Theoretical and Practical Framework for Evaluating Uncertainty Calibration in Object Detection
Sep 01, 2023



The proliferation of Deep Neural Networks has resulted in machine learning systems becoming increasingly more present in various real-world applications. Consequently, there is a growing demand for highly reliable models in these domains, making the problem of uncertainty calibration pivotal, when considering the future of deep learning. This is especially true when considering object detection systems, that are commonly present in safety-critical application such as autonomous driving and robotics. For this reason, this work presents a novel theoretical and practical framework to evaluate object detection systems in the context of uncertainty calibration. The robustness of the proposed uncertainty calibration metrics is shown through a series of representative experiments. Code for the proposed uncertainty calibration metrics at: https://github.com/pedrormconde/Uncertainty_Calibration_Object_Detection.
Multispectral Image Segmentation in Agriculture: A Comprehensive Study on Fusion Approaches
Jul 31, 2023Multispectral imagery is frequently incorporated into agricultural tasks, providing valuable support for applications such as image segmentation, crop monitoring, field robotics, and yield estimation. From an image segmentation perspective, multispectral cameras can provide rich spectral information, helping with noise reduction and feature extraction. As such, this paper concentrates on the use of fusion approaches to enhance the segmentation process in agricultural applications. More specifically, in this work, we compare different fusion approaches by combining RGB and NDVI as inputs for crop row detection, which can be useful in autonomous robots operating in the field. The inputs are used individually as well as combined at different times of the process (early and late fusion) to perform classical and DL-based semantic segmentation. In this study, two agriculture-related datasets are subjected to analysis using both deep learning (DL)-based and classical segmentation methodologies. The experiments reveal that classical segmentation methods, utilizing techniques such as edge detection and thresholding, can effectively compete with DL-based algorithms, particularly in tasks requiring precise foreground-background separation. This suggests that traditional methods retain their efficacy in certain specialized applications within the agricultural domain. Moreover, among the fusion strategies examined, late fusion emerges as the most robust approach, demonstrating superiority in adaptability and effectiveness across varying segmentation scenarios. The dataset and code is available at https://github.com/Cybonic/MISAgriculture.git.
TReR: A Lightweight Transformer Re-Ranking Approach for 3D LiDAR Place Recognition
May 29, 2023


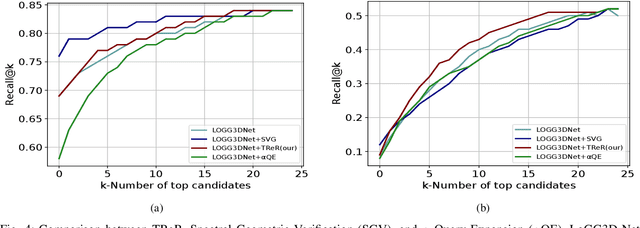
Autonomous driving systems often require reliable loop closure detection to guarantee reduced localization drift. Recently, 3D LiDAR-based localization methods have used retrieval-based place recognition to find revisited places efficiently. However, when deployed in challenging real-world scenarios, the place recognition models become more complex, which comes at the cost of high computational demand. This work tackles this problem from an information-retrieval perspective, adopting a first-retrieve-then-re-ranking paradigm, where an initial loop candidate ranking, generated from a 3D place recognition model, is re-ordered by a proposed lightweight transformer-based re-ranking approach (TReR). The proposed approach relies on global descriptors only, being agnostic to the place recognition model. The experimental evaluation, conducted on the KITTI Odometry dataset, where we compared TReR with s.o.t.a. re-ranking approaches such as alphaQE and SGV, indicate the robustness and efficiency when compared to alphaQE while offering a good trade-off between robustness and efficiency when compared to SGV.
Approaching Test Time Augmentation in the Context of Uncertainty Calibration for Deep Neural Networks
Apr 11, 2023



With the rise of Deep Neural Networks, machine learning systems are nowadays ubiquitous in a number of real-world applications, which bears the need for highly reliable models. This requires a thorough look not only at the accuracy of such systems, but also to their predictive uncertainty. Hence, we propose a novel technique (with two different variations, named M-ATTA and V-ATTA) based on test time augmentation, to improve the uncertainty calibration of deep models for image classification. Unlike other test time augmentation approaches, M/V-ATTA improves uncertainty calibration without affecting the model's accuracy, by leveraging an adaptive weighting system. We evaluate the performance of the technique with respect to different metrics of uncertainty calibration. Empirical results, obtained on CIFAR-10, CIFAR-100, as well as on the benchmark Aerial Image Dataset, indicate that the proposed approach outperforms state-of-the-art calibration techniques, while maintaining the baseline classification performance. Code for M/V-ATTA available at: https://github.com/pedrormconde/MV-ATTA.
Survey on Deep Fuzzy Systems in regression applications: a view on interpretability
Sep 09, 2022
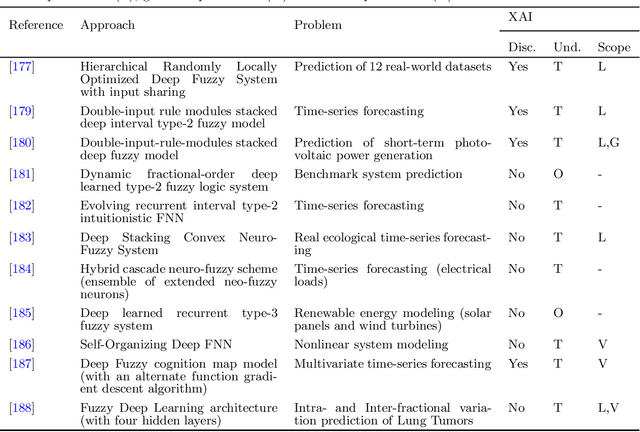

Regression problems have been more and more embraced by deep learning (DL) techniques. The increasing number of papers recently published in this domain, including surveys and reviews, shows that deep regression has captured the attention of the community due to efficiency and good accuracy in systems with high-dimensional data. However, many DL methodologies have complex structures that are not readily transparent to human users. Accessing the interpretability of these models is an essential factor for addressing problems in sensitive areas such as cyber-security systems, medical, financial surveillance, and industrial processes. Fuzzy logic systems (FLS) are inherently interpretable models, well known in the literature, capable of using nonlinear representations for complex systems through linguistic terms with membership degrees mimicking human thought. Within an atmosphere of explainable artificial intelligence, it is necessary to consider a trade-off between accuracy and interpretability for developing intelligent models. This paper aims to investigate the state-of-the-art on existing methodologies that combine DL and FLS, namely deep fuzzy systems, to address regression problems, configuring a topic that is currently not sufficiently explored in the literature and thus deserves a comprehensive survey.
High-Order Conditional Mutual Information Maximization for dealing with High-Order Dependencies in Feature Selection
Jul 18, 2022
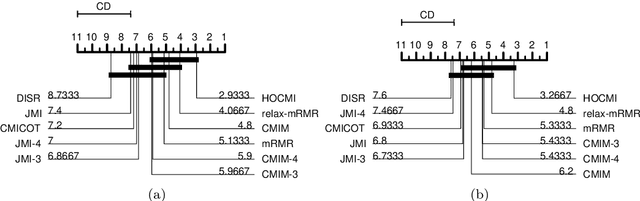

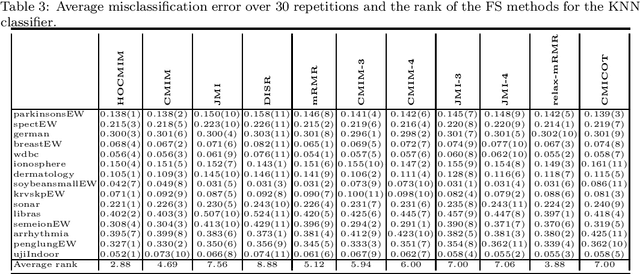
This paper presents a novel feature selection method based on the conditional mutual information (CMI). The proposed High Order Conditional Mutual Information Maximization (HOCMIM) incorporates high order dependencies into the feature selection procedure and has a straightforward interpretation due to its bottom-up derivation. The HOCMIM is derived from the CMI's chain expansion and expressed as a maximization optimization problem. The maximization problem is solved using a greedy search procedure, which speeds up the entire feature selection process. The experiments are run on a set of benchmark datasets (20 in total). The HOCMIM is compared with eighteen state-of-the-art feature selection algorithms, from the results of two supervised learning classifiers (Support Vector Machine and K-Nearest Neighbor). The HOCMIM achieves the best results in terms of accuracy and shows to be faster than high order feature selection counterparts.
Reducing Overconfidence Predictions for Autonomous Driving Perception
Feb 16, 2022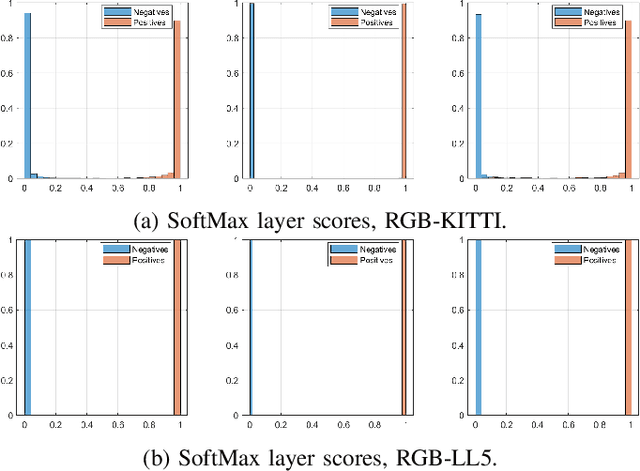
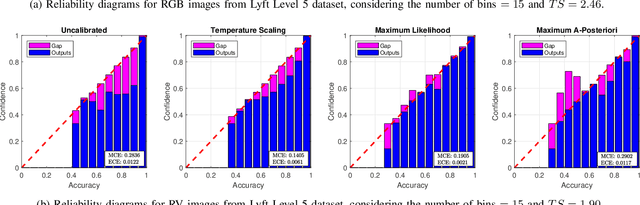
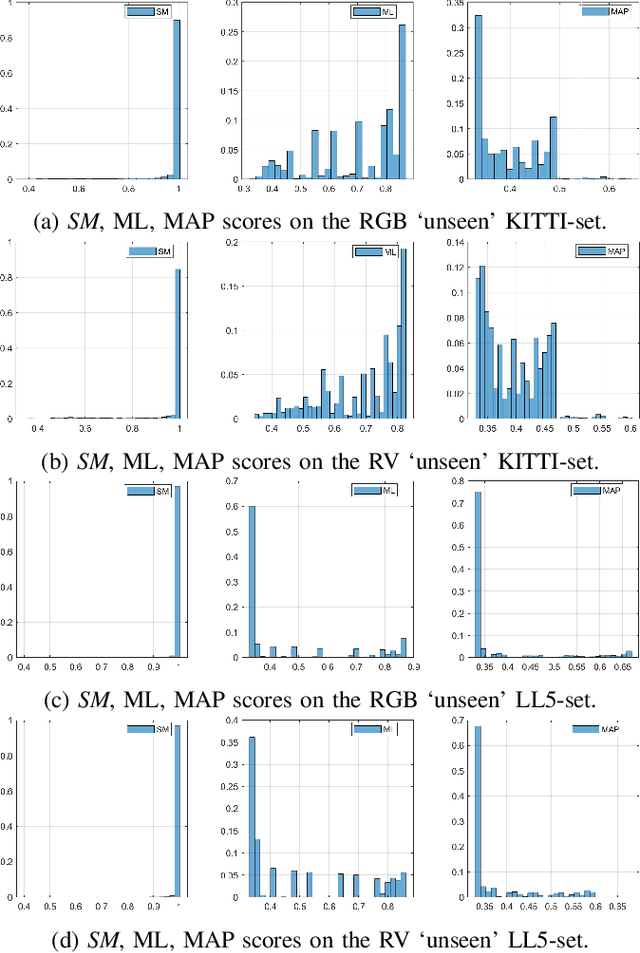
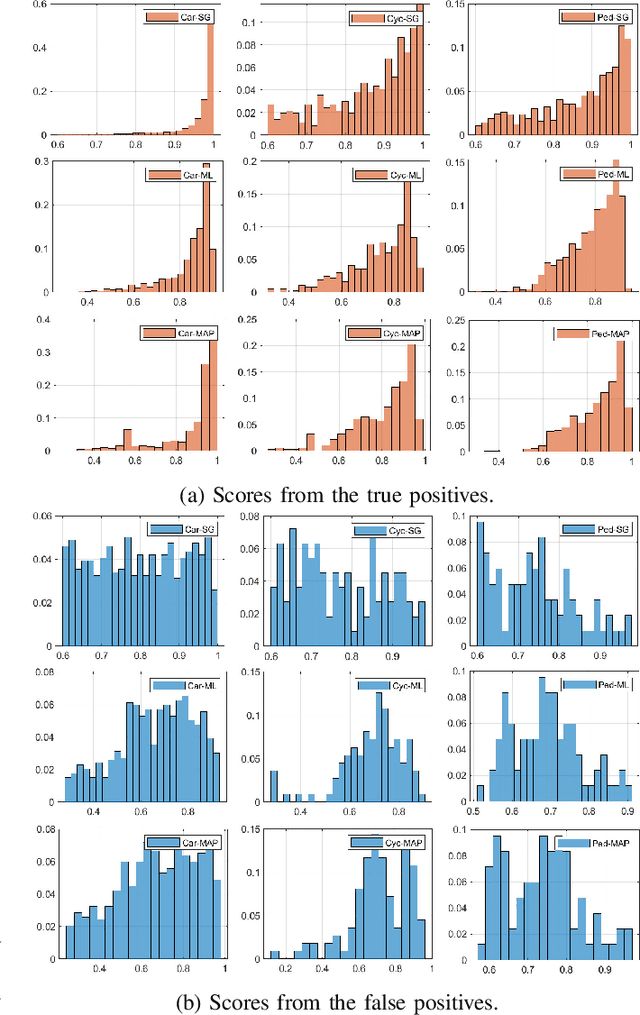
In state-of-the-art deep learning for object recognition, SoftMax and Sigmoid functions are most commonly employed as the predictor outputs. Such layers often produce overconfident predictions rather than proper probabilistic scores, which can thus harm the decision-making of `critical' perception systems applied in autonomous driving and robotics. Given this, the experiments in this work propose a probabilistic approach based on distributions calculated out of the Logit layer scores of pre-trained networks. We demonstrate that Maximum Likelihood (ML) and Maximum a-Posteriori (MAP) functions are more suitable for probabilistic interpretations than SoftMax and Sigmoid-based predictions for object recognition. We explore distinct sensor modalities via RGB images and LiDARs (RV: range-view) data from the KITTI and Lyft Level-5 datasets, where our approach shows promising performance compared to the usual SoftMax and Sigmoid layers, with the benefit of enabling interpretable probabilistic predictions. Another advantage of the approach introduced in this paper is that the ML and MAP functions can be implemented in existing trained networks, that is, the approach benefits from the output of the Logit layer of pre-trained networks. Thus, there is no need to carry out a new training phase since the ML and MAP functions are used in the test/prediction phase.
Place recognition survey: An update on deep learning approaches
Jun 22, 2021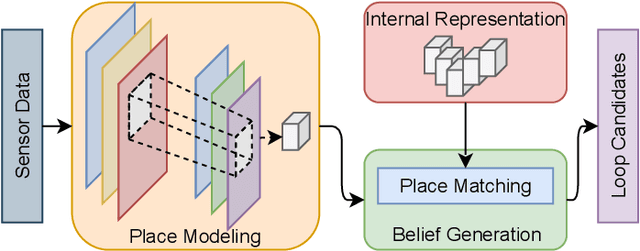

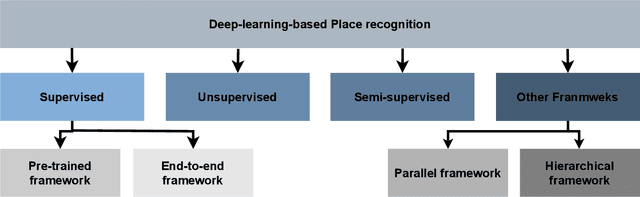
Autonomous Vehicles (AV) are becoming more capable of navigating in complex environments with dynamic and changing conditions. A key component that enables these intelligent vehicles to overcome such conditions and become more autonomous is the sophistication of the perception and localization systems. As part of the localization system, place recognition has benefited from recent developments in other perception tasks such as place categorization or object recognition, namely with the emergence of deep learning (DL) frameworks. This paper surveys recent approaches and methods used in place recognition, particularly those based on deep learning. The contributions of this work are twofold: surveying recent sensors such as 3D LiDARs and RADARs, applied in place recognition; and categorizing the various DL-based place recognition works into supervised, unsupervised, semi-supervised, parallel, and hierarchical categories. First, this survey introduces key place recognition concepts to contextualize the reader. Then, sensor characteristics are addressed. This survey proceeds by elaborating on the various DL-based works, presenting summaries for each framework. Some lessons learned from this survey include: the importance of NetVLAD for supervised end-to-end learning; the advantages of unsupervised approaches in place recognition, namely for cross-domain applications; or the increasing tendency of recent works to seek, not only for higher performance but also for higher efficiency.