 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Apr 11, 2024Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
A Deep Learning-based Global and Segmentation-based Semantic Feature Fusion Approach for Indoor Scene Classification
Feb 13, 2023
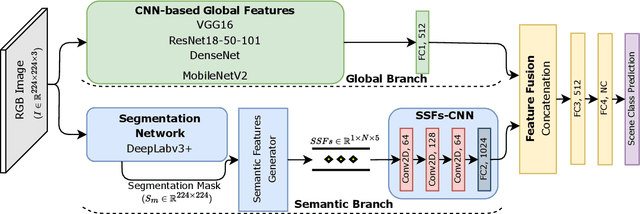
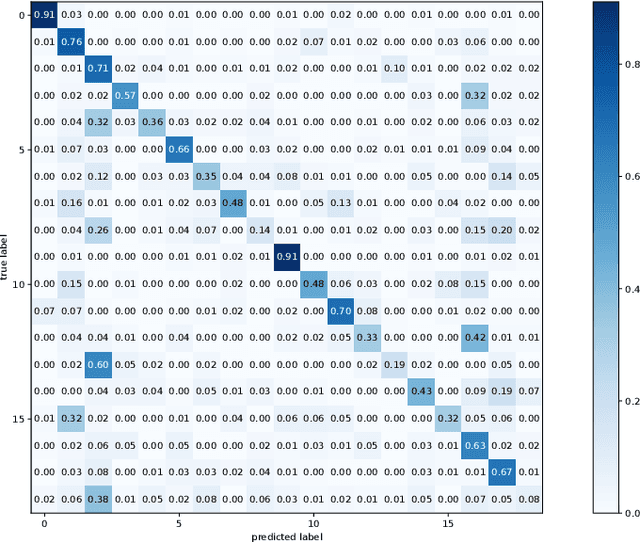
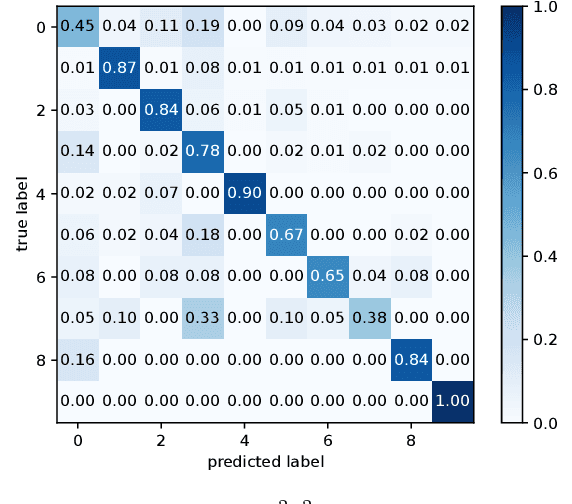
Indoor scene classification has become an important task in perception modules and has been widely used in various applications. However, problems such as intra-category variability and inter-category similarity have been holding back the models' performance, which leads to the need for new types of features to obtain a more meaningful scene representation. A semantic segmentation mask provides pixel-level information about the objects available in the scene, which makes it a promising source of information to obtain a more meaningful local representation of the scene. Therefore, in this work, a novel approach that uses a semantic segmentation mask to obtain a 2D spatial layout of the object categories across the scene, designated by segmentation-based semantic features (SSFs), is proposed. These features represent, per object category, the pixel count, as well as the 2D average position and respective standard deviation values. Moreover, a two-branch network, GS2F2App, that exploits CNN-based global features extracted from RGB images and the segmentation-based features extracted from the proposed SSFs, is also proposed. GS2F2App was evaluated in two indoor scene benchmark datasets: the SUN RGB-D and the NYU Depth V2, achieving state-of-the-art results on both datasets.
Place recognition survey: An update on deep learning approaches
Jun 22, 2021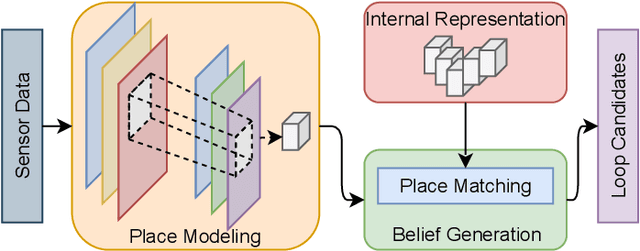

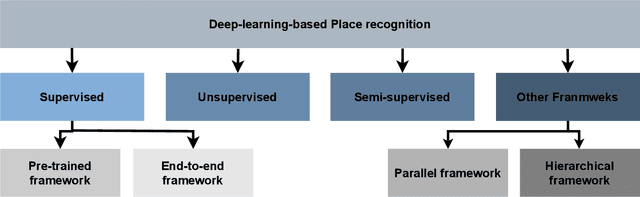
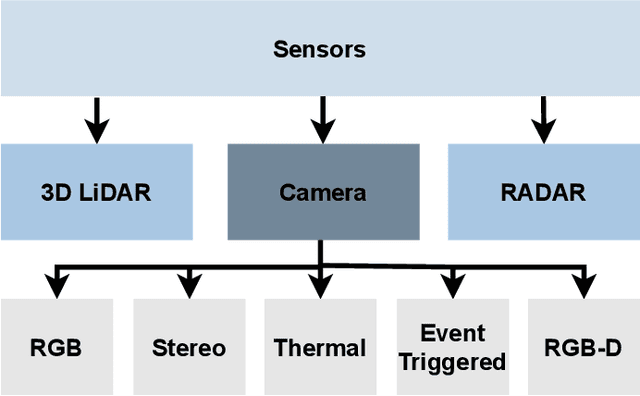
Autonomous Vehicles (AV) are becoming more capable of navigating in complex environments with dynamic and changing conditions. A key component that enables these intelligent vehicles to overcome such conditions and become more autonomous is the sophistication of the perception and localization systems. As part of the localization system, place recognition has benefited from recent developments in other perception tasks such as place categorization or object recognition, namely with the emergence of deep learning (DL) frameworks. This paper surveys recent approaches and methods used in place recognition, particularly those based on deep learning. The contributions of this work are twofold: surveying recent sensors such as 3D LiDARs and RADARs, applied in place recognition; and categorizing the various DL-based place recognition works into supervised, unsupervised, semi-supervised, parallel, and hierarchical categories. First, this survey introduces key place recognition concepts to contextualize the reader. Then, sensor characteristics are addressed. This survey proceeds by elaborating on the various DL-based works, presenting summaries for each framework. Some lessons learned from this survey include: the importance of NetVLAD for supervised end-to-end learning; the advantages of unsupervised approaches in place recognition, namely for cross-domain applications; or the increasing tendency of recent works to seek, not only for higher performance but also for higher efficiency.
AttDLNet: Attention-based DL Network for 3D LiDAR Place Recognition
Jun 17, 2021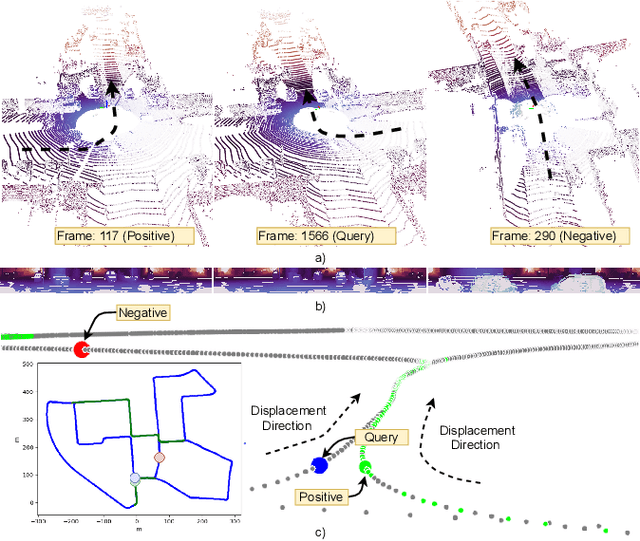
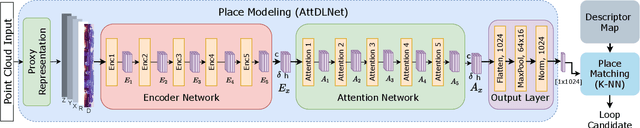
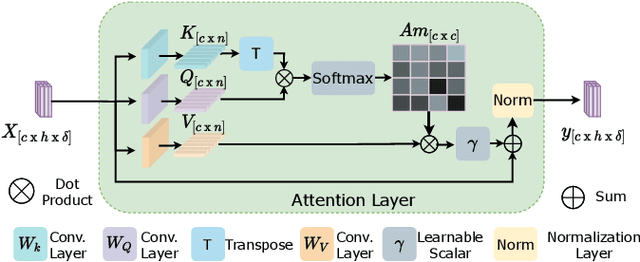

Deep networks have been progressively adapted to new sensor modalities, namely to 3D LiDAR, which led to unprecedented achievements in autonomous vehicle-related applications such as place recognition. One of the main challenges of deep models in place recognition is to extract efficient and descriptive feature representations that relate places based on their similarity. To address the problem of place recognition using LiDAR data, this paper proposes a novel 3D LiDAR-based deep learning network (named AttDLNet) that comprises an encoder network and exploits an attention mechanism to selectively focus on long-range context and interfeature relationships. The proposed network is trained and validated on the KITTI dataset, using the cosine loss for training and a retrieval-based place recognition pipeline for validation. Additionally, an ablation study is presented to assess the best network configuration. Results show that the encoder network features are already very descriptive, but adding attention to the network further improves performance. From the ablation study, results indicate that the middle encoder layers have the highest mean performance, while deeper layers are more robust to orientation change. The code is publicly available on the project website: https://github.com/Cybonic/ AttDLNet