 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Apr 11, 2024Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
Multispectral Image Segmentation in Agriculture: A Comprehensive Study on Fusion Approaches
Jul 31, 2023Multispectral imagery is frequently incorporated into agricultural tasks, providing valuable support for applications such as image segmentation, crop monitoring, field robotics, and yield estimation. From an image segmentation perspective, multispectral cameras can provide rich spectral information, helping with noise reduction and feature extraction. As such, this paper concentrates on the use of fusion approaches to enhance the segmentation process in agricultural applications. More specifically, in this work, we compare different fusion approaches by combining RGB and NDVI as inputs for crop row detection, which can be useful in autonomous robots operating in the field. The inputs are used individually as well as combined at different times of the process (early and late fusion) to perform classical and DL-based semantic segmentation. In this study, two agriculture-related datasets are subjected to analysis using both deep learning (DL)-based and classical segmentation methodologies. The experiments reveal that classical segmentation methods, utilizing techniques such as edge detection and thresholding, can effectively compete with DL-based algorithms, particularly in tasks requiring precise foreground-background separation. This suggests that traditional methods retain their efficacy in certain specialized applications within the agricultural domain. Moreover, among the fusion strategies examined, late fusion emerges as the most robust approach, demonstrating superiority in adaptability and effectiveness across varying segmentation scenarios. The dataset and code is available at https://github.com/Cybonic/MISAgriculture.git.
TReR: A Lightweight Transformer Re-Ranking Approach for 3D LiDAR Place Recognition
May 29, 2023


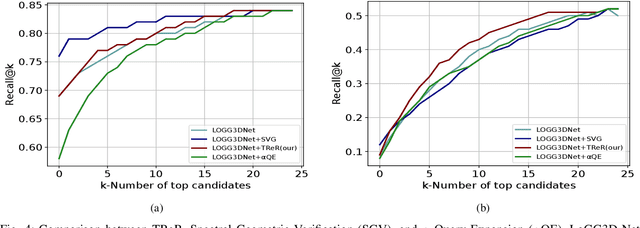
Autonomous driving systems often require reliable loop closure detection to guarantee reduced localization drift. Recently, 3D LiDAR-based localization methods have used retrieval-based place recognition to find revisited places efficiently. However, when deployed in challenging real-world scenarios, the place recognition models become more complex, which comes at the cost of high computational demand. This work tackles this problem from an information-retrieval perspective, adopting a first-retrieve-then-re-ranking paradigm, where an initial loop candidate ranking, generated from a 3D place recognition model, is re-ordered by a proposed lightweight transformer-based re-ranking approach (TReR). The proposed approach relies on global descriptors only, being agnostic to the place recognition model. The experimental evaluation, conducted on the KITTI Odometry dataset, where we compared TReR with s.o.t.a. re-ranking approaches such as alphaQE and SGV, indicate the robustness and efficiency when compared to alphaQE while offering a good trade-off between robustness and efficiency when compared to SGV.
Approaching Test Time Augmentation in the Context of Uncertainty Calibration for Deep Neural Networks
Apr 11, 2023



With the rise of Deep Neural Networks, machine learning systems are nowadays ubiquitous in a number of real-world applications, which bears the need for highly reliable models. This requires a thorough look not only at the accuracy of such systems, but also to their predictive uncertainty. Hence, we propose a novel technique (with two different variations, named M-ATTA and V-ATTA) based on test time augmentation, to improve the uncertainty calibration of deep models for image classification. Unlike other test time augmentation approaches, M/V-ATTA improves uncertainty calibration without affecting the model's accuracy, by leveraging an adaptive weighting system. We evaluate the performance of the technique with respect to different metrics of uncertainty calibration. Empirical results, obtained on CIFAR-10, CIFAR-100, as well as on the benchmark Aerial Image Dataset, indicate that the proposed approach outperforms state-of-the-art calibration techniques, while maintaining the baseline classification performance. Code for M/V-ATTA available at: https://github.com/pedrormconde/MV-ATTA.
A Deep Learning-based Global and Segmentation-based Semantic Feature Fusion Approach for Indoor Scene Classification
Feb 13, 2023
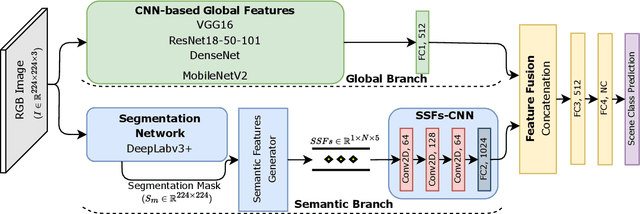
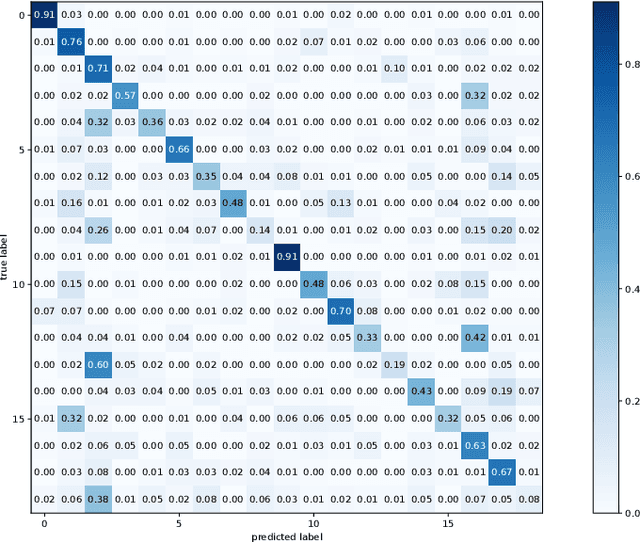
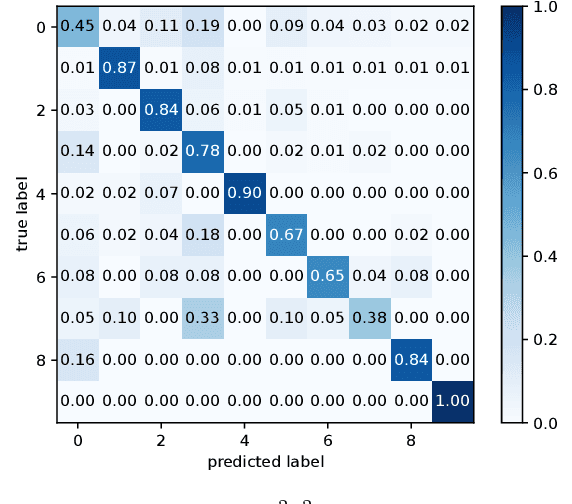
Indoor scene classification has become an important task in perception modules and has been widely used in various applications. However, problems such as intra-category variability and inter-category similarity have been holding back the models' performance, which leads to the need for new types of features to obtain a more meaningful scene representation. A semantic segmentation mask provides pixel-level information about the objects available in the scene, which makes it a promising source of information to obtain a more meaningful local representation of the scene. Therefore, in this work, a novel approach that uses a semantic segmentation mask to obtain a 2D spatial layout of the object categories across the scene, designated by segmentation-based semantic features (SSFs), is proposed. These features represent, per object category, the pixel count, as well as the 2D average position and respective standard deviation values. Moreover, a two-branch network, GS2F2App, that exploits CNN-based global features extracted from RGB images and the segmentation-based features extracted from the proposed SSFs, is also proposed. GS2F2App was evaluated in two indoor scene benchmark datasets: the SUN RGB-D and the NYU Depth V2, achieving state-of-the-art results on both datasets.
Place recognition survey: An update on deep learning approaches
Jun 22, 2021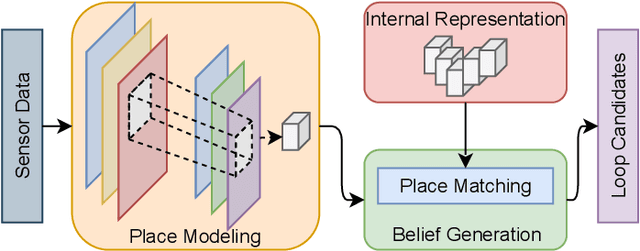

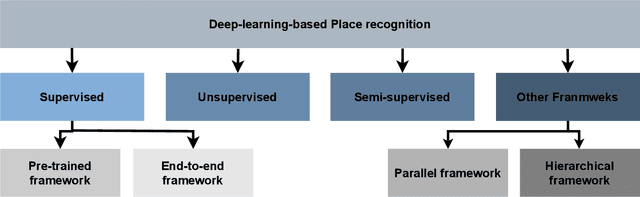
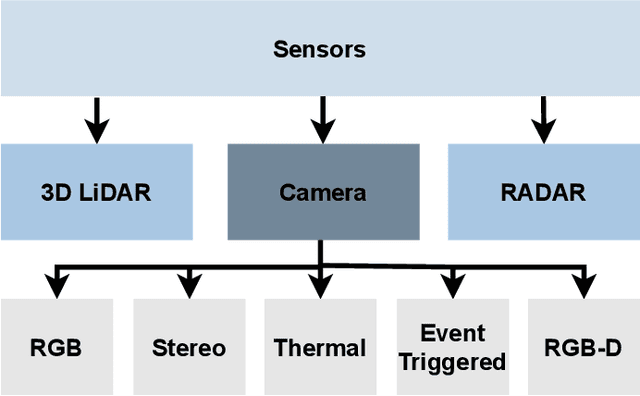
Autonomous Vehicles (AV) are becoming more capable of navigating in complex environments with dynamic and changing conditions. A key component that enables these intelligent vehicles to overcome such conditions and become more autonomous is the sophistication of the perception and localization systems. As part of the localization system, place recognition has benefited from recent developments in other perception tasks such as place categorization or object recognition, namely with the emergence of deep learning (DL) frameworks. This paper surveys recent approaches and methods used in place recognition, particularly those based on deep learning. The contributions of this work are twofold: surveying recent sensors such as 3D LiDARs and RADARs, applied in place recognition; and categorizing the various DL-based place recognition works into supervised, unsupervised, semi-supervised, parallel, and hierarchical categories. First, this survey introduces key place recognition concepts to contextualize the reader. Then, sensor characteristics are addressed. This survey proceeds by elaborating on the various DL-based works, presenting summaries for each framework. Some lessons learned from this survey include: the importance of NetVLAD for supervised end-to-end learning; the advantages of unsupervised approaches in place recognition, namely for cross-domain applications; or the increasing tendency of recent works to seek, not only for higher performance but also for higher efficiency.
AttDLNet: Attention-based DL Network for 3D LiDAR Place Recognition
Jun 17, 2021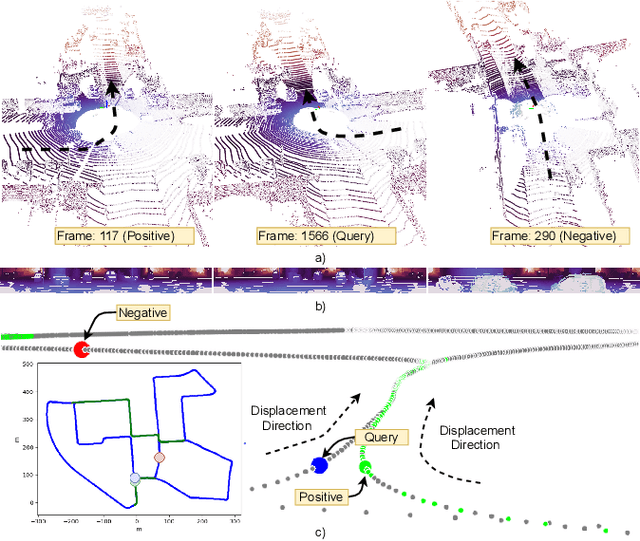
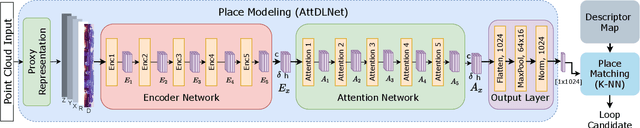
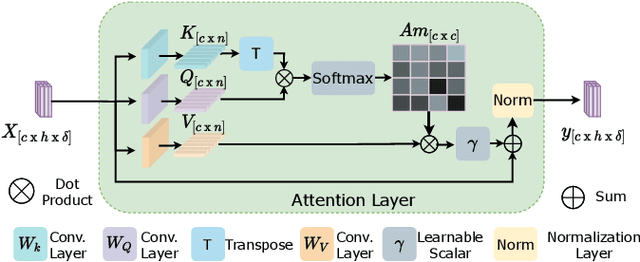

Deep networks have been progressively adapted to new sensor modalities, namely to 3D LiDAR, which led to unprecedented achievements in autonomous vehicle-related applications such as place recognition. One of the main challenges of deep models in place recognition is to extract efficient and descriptive feature representations that relate places based on their similarity. To address the problem of place recognition using LiDAR data, this paper proposes a novel 3D LiDAR-based deep learning network (named AttDLNet) that comprises an encoder network and exploits an attention mechanism to selectively focus on long-range context and interfeature relationships. The proposed network is trained and validated on the KITTI dataset, using the cosine loss for training and a retrieval-based place recognition pipeline for validation. Additionally, an ablation study is presented to assess the best network configuration. Results show that the encoder network features are already very descriptive, but adding attention to the network further improves performance. From the ablation study, results indicate that the middle encoder layers have the highest mean performance, while deeper layers are more robust to orientation change. The code is publicly available on the project website: https://github.com/Cybonic/ AttDLNet
CNN-based Approaches For Cross-Subject Classification in Motor Imagery: From The State-of-The-Art to DynamicNet
May 17, 2021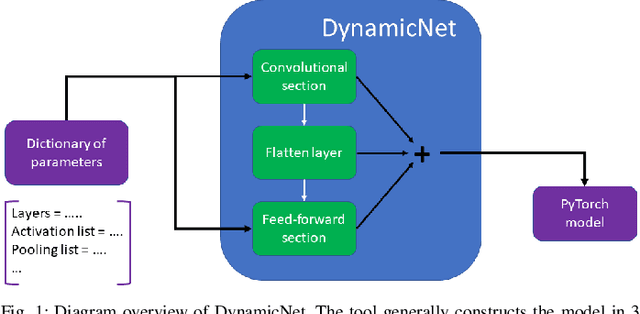
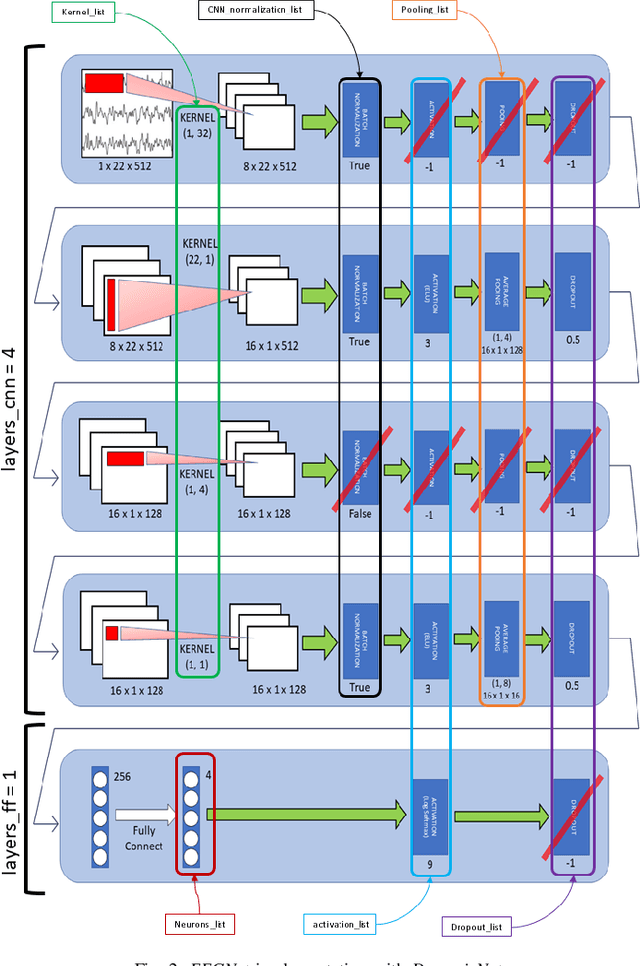
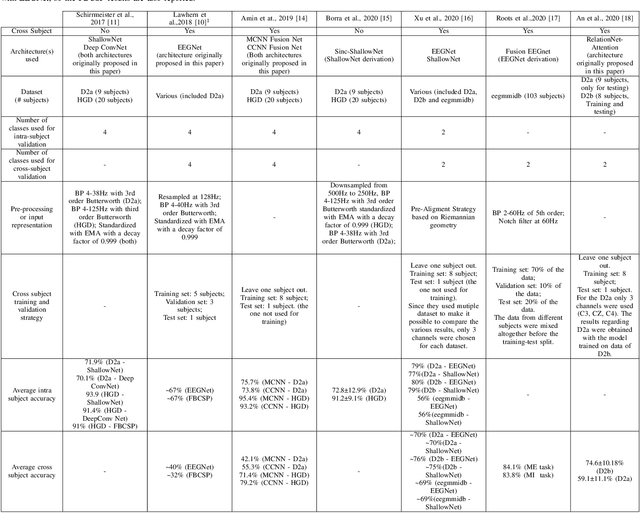

Motor imagery (MI)-based brain-computer interface (BCI) systems are being increasingly employed to provide alternative means of communication and control for people suffering from neuro-motor impairments, with a special effort to bring these systems out of the controlled lab environments. Hence, accurately classifying MI from brain signals, e.g., from electroencephalography (EEG), is essential to obtain reliable BCI systems. However, MI classification is still a challenging task, because the signals are characterized by poor SNR, high intra-subject and cross-subject variability. Deep learning approaches have started to emerge as valid alternatives to standard machine learning techniques, e.g., filter bank common spatial pattern (FBCSP), to extract subject-independent features and to increase the cross-subject classification performance of MI BCI systems. In this paper, we first present a review of the most recent studies using deep learning for MI classification, with particular attention to their cross-subject performance. Second, we propose DynamicNet, a Python-based tool for quick and flexible implementations of deep learning models based on convolutional neural networks. We show-case the potentiality of DynamicNet by implementing EEGNet, a well-established architecture for effective EEG classification. Finally, we compare its performance with FBCSP in a 4-class MI classification over public datasets. To explore its cross-subject classification ability, we applied three different cross-validation schemes. From our results, we demonstrate that DynamicNet-implemented EEGNet outperforms FBCSP by about 25%, with a statistically significant difference when cross-subject validation schemes are applied.