 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Apr 11, 2024Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
A Deep Learning-based Global and Segmentation-based Semantic Feature Fusion Approach for Indoor Scene Classification
Feb 13, 2023
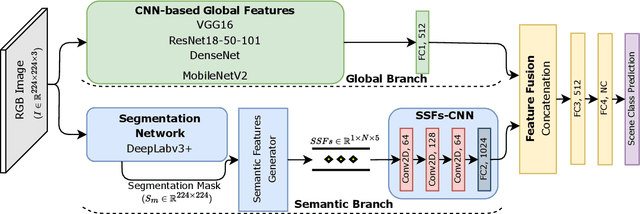
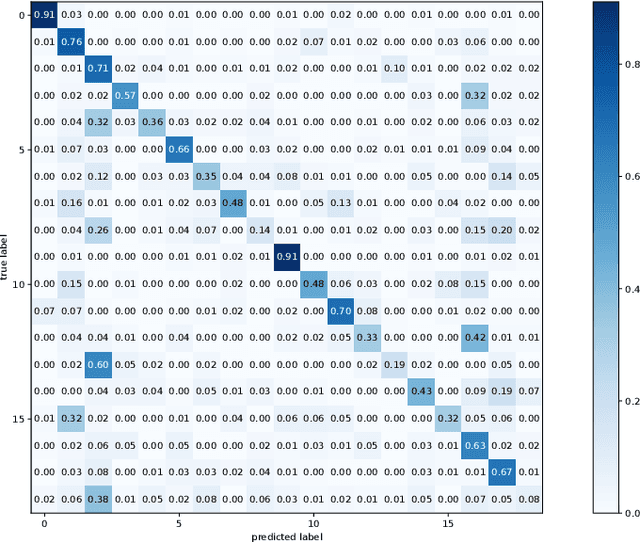
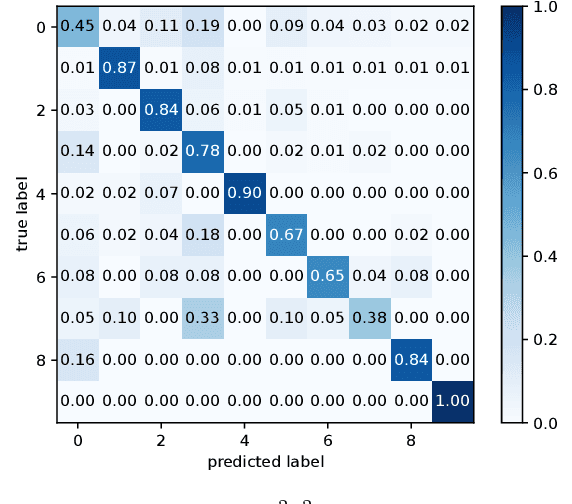
Indoor scene classification has become an important task in perception modules and has been widely used in various applications. However, problems such as intra-category variability and inter-category similarity have been holding back the models' performance, which leads to the need for new types of features to obtain a more meaningful scene representation. A semantic segmentation mask provides pixel-level information about the objects available in the scene, which makes it a promising source of information to obtain a more meaningful local representation of the scene. Therefore, in this work, a novel approach that uses a semantic segmentation mask to obtain a 2D spatial layout of the object categories across the scene, designated by segmentation-based semantic features (SSFs), is proposed. These features represent, per object category, the pixel count, as well as the 2D average position and respective standard deviation values. Moreover, a two-branch network, GS2F2App, that exploits CNN-based global features extracted from RGB images and the segmentation-based features extracted from the proposed SSFs, is also proposed. GS2F2App was evaluated in two indoor scene benchmark datasets: the SUN RGB-D and the NYU Depth V2, achieving state-of-the-art results on both datasets.
Multi-stage Deep Layer Aggregation for Brain Tumor Segmentation
Jan 02, 2021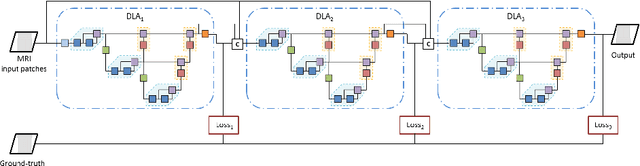
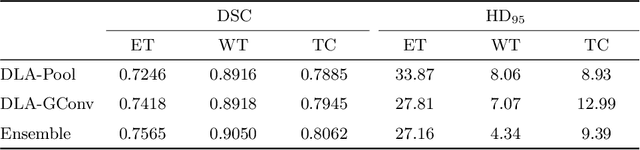
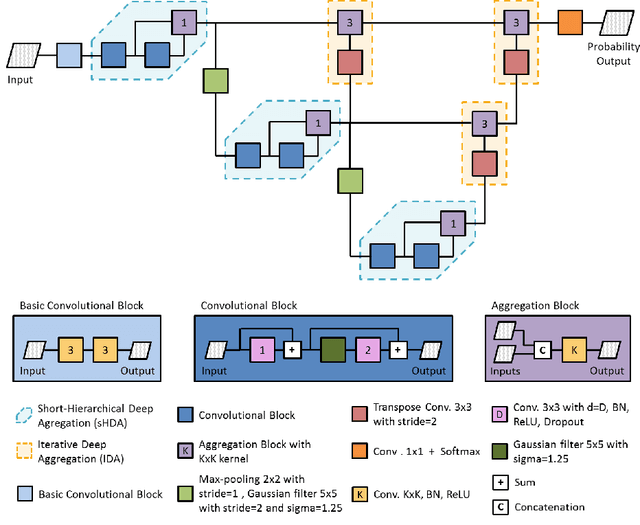
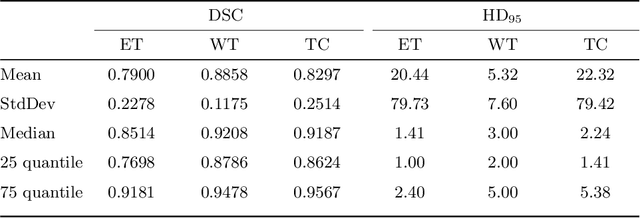
Gliomas are among the most aggressive and deadly brain tumors. This paper details the proposed Deep Neural Network architecture for brain tumor segmentation from Magnetic Resonance Images. The architecture consists of a cascade of three Deep Layer Aggregation neural networks, where each stage elaborates the response using the feature maps and the probabilities of the previous stage, and the MRI channels as inputs. The neuroimaging data are part of the publicly available Brain Tumor Segmentation (BraTS) 2020 challenge dataset, where we evaluated our proposal in the BraTS 2020 Validation and Test sets. In the Test set, the experimental results achieved a Dice score of 0.8858, 0.8297 and 0.7900, with an Hausdorff Distance of 5.32 mm, 22.32 mm and 20.44 mm for the whole tumor, core tumor and enhanced tumor, respectively.