 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical and Practical Framework for Evaluating Uncertainty Calibration in Object Detection
Sep 01, 2023



The proliferation of Deep Neural Networks has resulted in machine learning systems becoming increasingly more present in various real-world applications. Consequently, there is a growing demand for highly reliable models in these domains, making the problem of uncertainty calibration pivotal, when considering the future of deep learning. This is especially true when considering object detection systems, that are commonly present in safety-critical application such as autonomous driving and robotics. For this reason, this work presents a novel theoretical and practical framework to evaluate object detection systems in the context of uncertainty calibration. The robustness of the proposed uncertainty calibration metrics is shown through a series of representative experiments. Code for the proposed uncertainty calibration metrics at: https://github.com/pedrormconde/Uncertainty_Calibration_Object_Detection.
Approaching Test Time Augmentation in the Context of Uncertainty Calibration for Deep Neural Networks
Apr 11, 2023



With the rise of Deep Neural Networks, machine learning systems are nowadays ubiquitous in a number of real-world applications, which bears the need for highly reliable models. This requires a thorough look not only at the accuracy of such systems, but also to their predictive uncertainty. Hence, we propose a novel technique (with two different variations, named M-ATTA and V-ATTA) based on test time augmentation, to improve the uncertainty calibration of deep models for image classification. Unlike other test time augmentation approaches, M/V-ATTA improves uncertainty calibration without affecting the model's accuracy, by leveraging an adaptive weighting system. We evaluate the performance of the technique with respect to different metrics of uncertainty calibration. Empirical results, obtained on CIFAR-10, CIFAR-100, as well as on the benchmark Aerial Image Dataset, indicate that the proposed approach outperforms state-of-the-art calibration techniques, while maintaining the baseline classification performance. Code for M/V-ATTA available at: https://github.com/pedrormconde/MV-ATTA.
Proceedings of the Workshop on Data Mining for Oil and Gas
May 26, 2017The process of exploring and exploiting Oil and Gas (O&G) generates a lot of data that can bring more efficiency to the industry. The opportunities for using data mining techniques in the "digital oil-field" remain largely unexplored or uncharted. With the high rate of data expansion, companies are scrambling to develop ways to develop near-real-time predictive analytics, data mining and machine learning capabilities, and are expanding their data storage infrastructure and resources. With these new goals, come the challenges of managing data growth, integrating intelligence tools, and analyzing the data to glean useful insights. Oil and Gas companies need data solutions to economically extract value from very large volumes of a wide variety of data generated from exploration, well drilling and production devices and sensors. Data mining for oil and gas industry throughout the lifecycle of the reservoir includes the following roles: locating hydrocarbons, managing geological data, drilling and formation evaluation, well construction, well completion, and optimizing production through the life of the oil field. For each of these phases during the lifecycle of oil field, data mining play a significant role. Based on which phase were talking about, knowledge creation through scientific models, data analytics and machine learning, a effective, productive, and on demand data insight is critical for decision making within the organization. The significant challenges posed by this complex and economically vital field justify a meeting of data scientists that are willing to share their experience and knowledge. Thus, the Worskhop on Data Mining for Oil and Gas (DM4OG) aims to provide a quality forum for researchers that work on the significant challenges arising from the synergy between data science, machine learning, and the modeling and optimization problems in the O&G industry.
Mind the Gap: A Well Log Data Analysis
May 10, 2017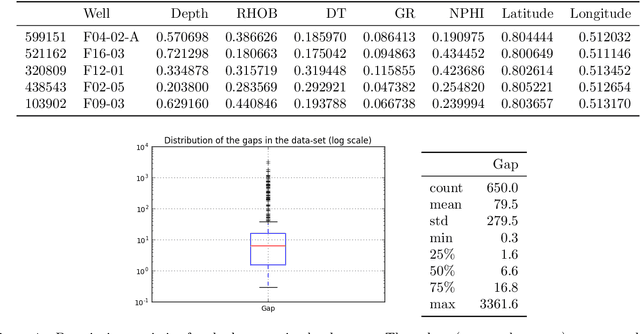
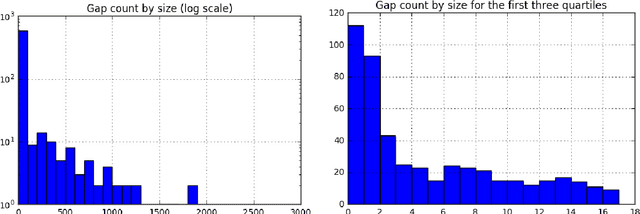
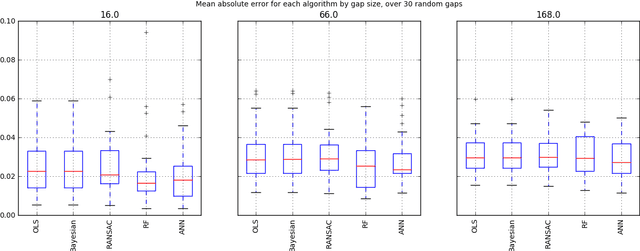
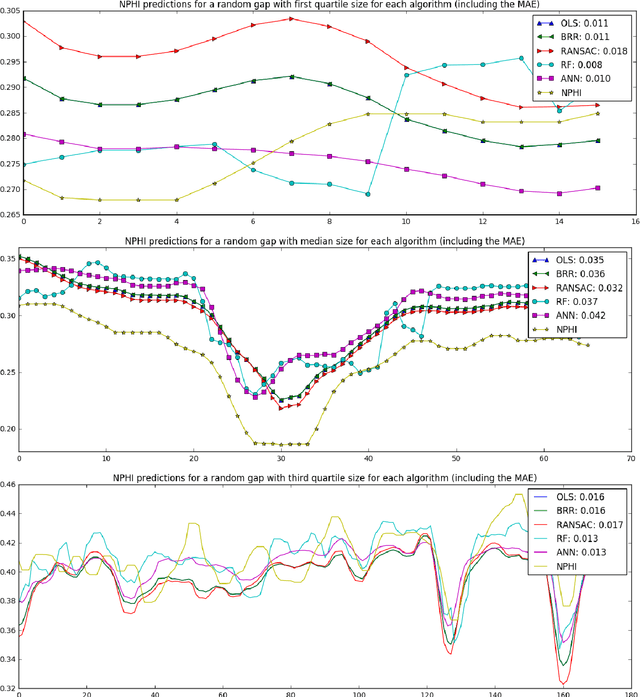
The main task in oil and gas exploration is to gain an understanding of the distribution and nature of rocks and fluids in the subsurface. Well logs are records of petro-physical data acquired along a borehole, providing direct information about what is in the subsurface. The data collected by logging wells can have significant economic consequences, due to the costs inherent to drilling wells, and the potential return of oil deposits. In this paper, we describe preliminary work aimed at building a general framework for well log prediction. First, we perform a descriptive and exploratory analysis of the gaps in the neutron porosity logs of more than a thousand wells in the North Sea. Then, we generate artificial gaps in the neutron logs that reflect the statistics collected before. Finally, we compare Artificial Neural Networks, Random Forests, and three algorithms of Linear Regression in the prediction of missing gaps on a well-by-well basis.