 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CirCor DigiScope Dataset: From Murmur Detection to Murmur Classification
Aug 02, 2021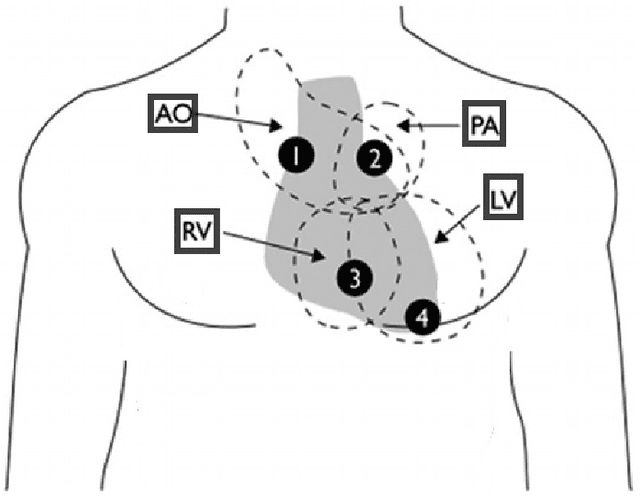
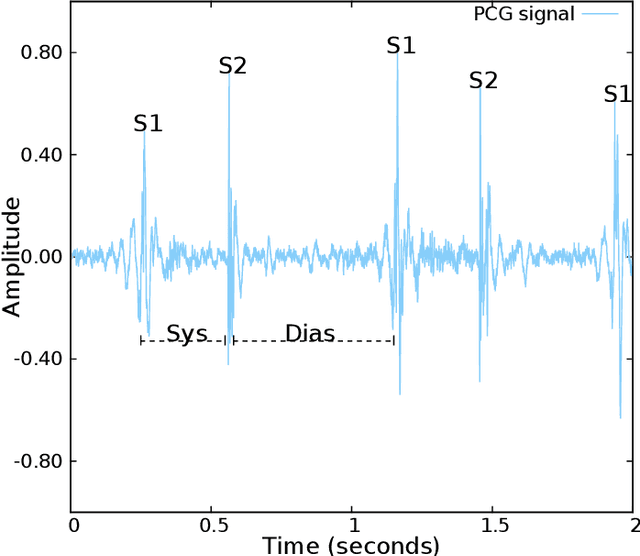

Cardiac auscultation is one of the most cost-effective techniques used to detect and identify many heart conditions. Computer-assisted decision systems based on auscultation can support physicians in their decisions. Unfortunately, the application of such systems in clinical trials is still minimal since most of them only aim to detect the presence of extra or abnormal waves in the phonocardiogram signal. This is mainly due to the lack of large publicly available datasets, where a more detailed description of such abnormal waves (e.g., cardiac murmurs) exists. As a result, current machine learning algorithms are unable to classify such waves. To pave the way to more effective research on healthcare recommendation systems based on auscultation, our team has prepared the currently largest pediatric heart sound dataset. A total of 5282 recordings have been collected from the four main auscultation locations of 1568 patients, in the process 215780 heart sounds have been manually annotated. Furthermore, and for the first time, each cardiac murmur has been manually annotated by an expert annotator according to its timing, shape, pitch, grading and quality. In addition, the auscultation locations where the murmur is present were identified as well as the auscultation location where the murmur is detected more intensively.
Language Modelling Makes Sense: Propagating Representations through WordNet for Full-Coverage Word Sense Disambiguation
Jun 24, 2019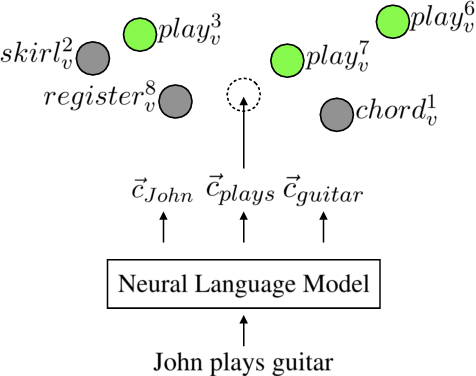

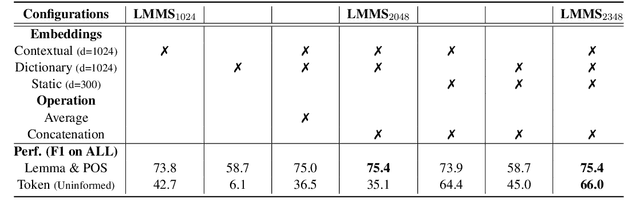
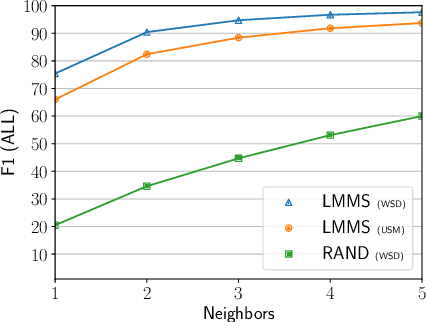
Contextual embeddings represent a new generation of semantic representations learned from Neural Language Modelling (NLM) that addresses the issue of meaning conflation hampering traditional word embeddings. In this work, we show that contextual embeddings can be used to achieve unprecedented gains in Word Sense Disambiguation (WSD) tasks. Our approach focuses on creating sense-level embeddings with full-coverage of WordNet, and without recourse to explicit knowledge of sense distributions or task-specific modelling. As a result, a simple Nearest Neighbors (k-NN) method using our representations is able to consistently surpass the performance of previous systems using powerful neural sequencing models. We also analyse the robustness of our approach when ignoring part-of-speech and lemma features, requiring disambiguation against the full sense inventory, and revealing shortcomings to be improved. Finally, we explore applications of our sense embeddings for concept-level analyses of contextual embeddings and their respective NLMs.
LIAAD at SemDeep-5 Challenge: Word-in-Context
Jun 24, 2019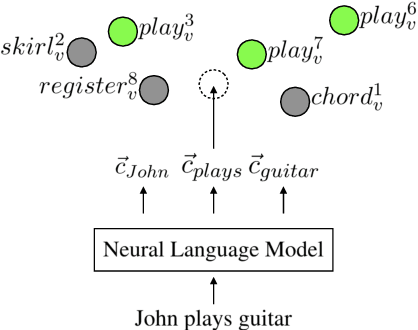
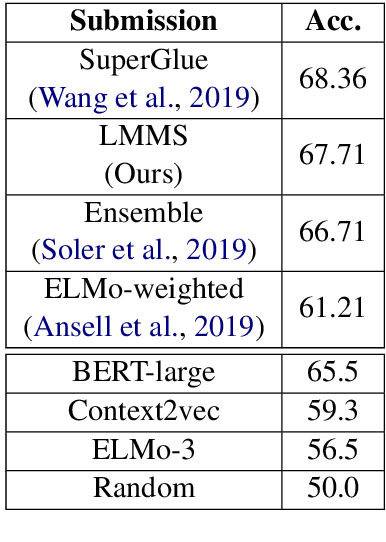
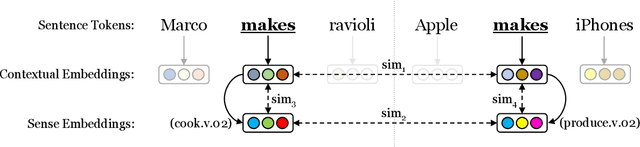
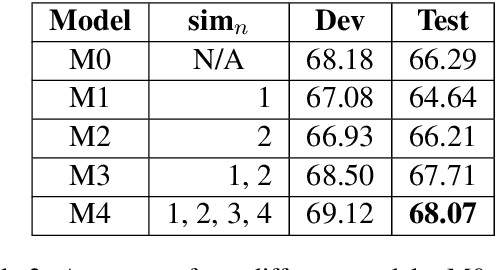
This paper describes the LIAAD system that was ranked second place in the Word-in-Context challenge (WiC) featured in SemDeep-5. Our solution is based on a novel system for Word Sense Disambiguation (WSD) using contextual embeddings and full-inventory sense embeddings. We adapt this WSD system, in a straightforward manner, for the present task of detecting whether the same sense occurs in a pair of sentences. Additionally, we show that our solution is able to achieve competitive performance even without using the provided training or development sets, mitigating potential concerns related to task overfitting
Proceedings of the Workshop on Data Mining for Oil and Gas
May 26, 2017The process of exploring and exploiting Oil and Gas (O&G) generates a lot of data that can bring more efficiency to the industry. The opportunities for using data mining techniques in the "digital oil-field" remain largely unexplored or uncharted. With the high rate of data expansion, companies are scrambling to develop ways to develop near-real-time predictive analytics, data mining and machine learning capabilities, and are expanding their data storage infrastructure and resources. With these new goals, come the challenges of managing data growth, integrating intelligence tools, and analyzing the data to glean useful insights. Oil and Gas companies need data solutions to economically extract value from very large volumes of a wide variety of data generated from exploration, well drilling and production devices and sensors. Data mining for oil and gas industry throughout the lifecycle of the reservoir includes the following roles: locating hydrocarbons, managing geological data, drilling and formation evaluation, well construction, well completion, and optimizing production through the life of the oil field. For each of these phases during the lifecycle of oil field, data mining play a significant role. Based on which phase were talking about, knowledge creation through scientific models, data analytics and machine learning, a effective, productive, and on demand data insight is critical for decision making within the organization. The significant challenges posed by this complex and economically vital field justify a meeting of data scientists that are willing to share their experience and knowledge. Thus, the Worskhop on Data Mining for Oil and Gas (DM4OG) aims to provide a quality forum for researchers that work on the significant challenges arising from the synergy between data science, machine learning, and the modeling and optimization problems in the O&G industry.