 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
A short review of the main concerns in A.I. development and application within the public sector supported by NLP and TM
Jul 25, 2023



Artificial Intelligence is not a new subject, and business, industry and public sectors have used it in different ways and contexts and considering multiple concerns. This work reviewed research papers published in ACM Digital Library and IEEE Xplore conference proceedings in the last two years supported by fundamental concepts of Natural Language Processing (NLP) and Text Mining (TM). The objective was to capture insights regarding data privacy, ethics, interpretability, explainability, trustworthiness, and fairness in the public sector. The methodology has saved analysis time and could retrieve papers containing relevant information. The results showed that fairness was the most frequent concern. The least prominent topic was data privacy (although embedded in most articles), while the most prominent was trustworthiness. Finally, gathering helpful insights about those concerns regarding A.I. applications in the public sector was also possible.
The CirCor DigiScope Dataset: From Murmur Detection to Murmur Classification
Aug 02, 2021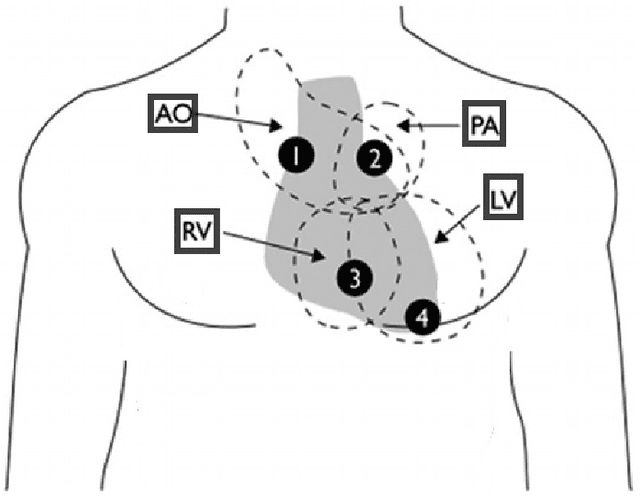
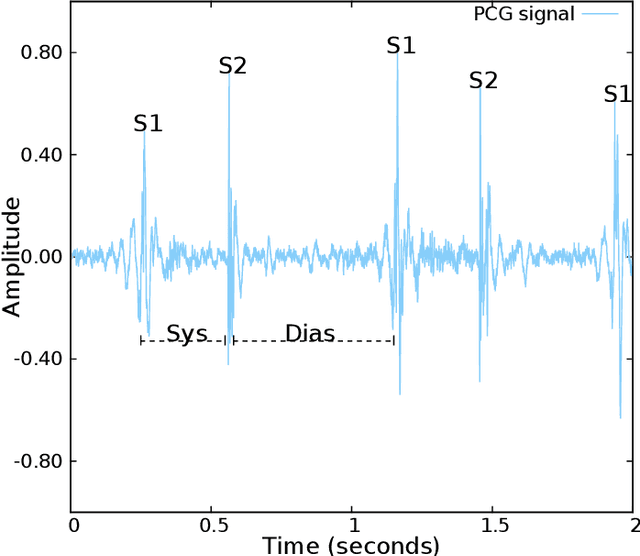

Cardiac auscultation is one of the most cost-effective techniques used to detect and identify many heart conditions. Computer-assisted decision systems based on auscultation can support physicians in their decisions. Unfortunately, the application of such systems in clinical trials is still minimal since most of them only aim to detect the presence of extra or abnormal waves in the phonocardiogram signal. This is mainly due to the lack of large publicly available datasets, where a more detailed description of such abnormal waves (e.g., cardiac murmurs) exists. As a result, current machine learning algorithms are unable to classify such waves. To pave the way to more effective research on healthcare recommendation systems based on auscultation, our team has prepared the currently largest pediatric heart sound dataset. A total of 5282 recordings have been collected from the four main auscultation locations of 1568 patients, in the process 215780 heart sounds have been manually annotated. Furthermore, and for the first time, each cardiac murmur has been manually annotated by an expert annotator according to its timing, shape, pitch, grading and quality. In addition, the auscultation locations where the murmur is present were identified as well as the auscultation location where the murmur is detected more intensively.
LNDb: A Lung Nodule Database on Computed Tomography
Dec 19, 2019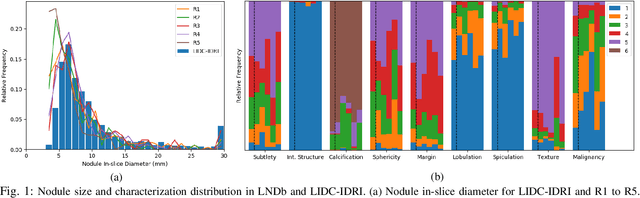
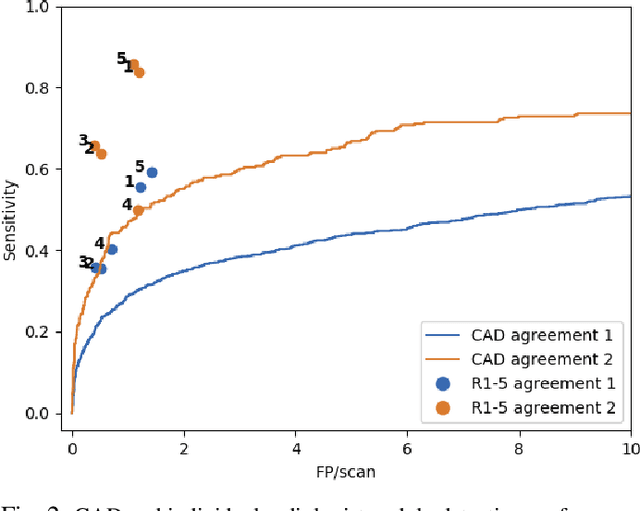
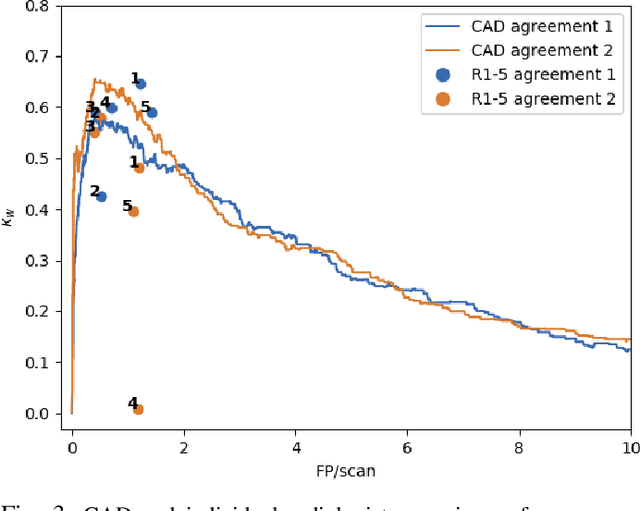
Lung cancer is the deadliest type of cancer worldwide and late detection is the major factor for the low survival rate of patients. Low dose computed tomography has been suggested as a potential screening tool but manual screening is costly, time-consuming and prone to variability. This has fueled the development of automatic methods for the detection, segmentation and characterisation of pulmonary nodules but its application to clinical routine is challenging. In this study, a new database for the development and testing of pulmonary nodule computer-aided strategies is presented which intends to complement current databases by giving additional focus to radiologist variability and local clinical reality. State-of-the-art nodule detection, segmentation and characterization methods are tested and compared to manual annotations as well as collaborative strategies combining multiple radiologists and radiologists and computer-aided systems. It is shown that state-of-the-art methodologies can determine a patient's follow-up recommendation as accurately as a radiologist, though the nodule detection method used shows decreased performance in this database.
Did you miss it? Automatic lung nodule detection combined with gaze information improves radiologists' screening performance
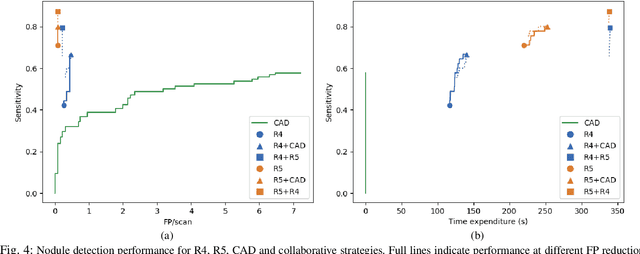
Oct 09, 2019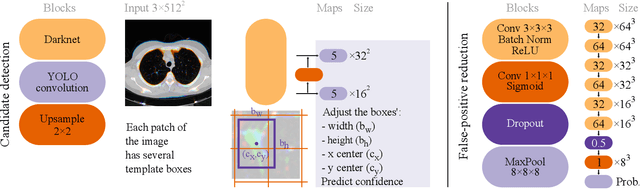
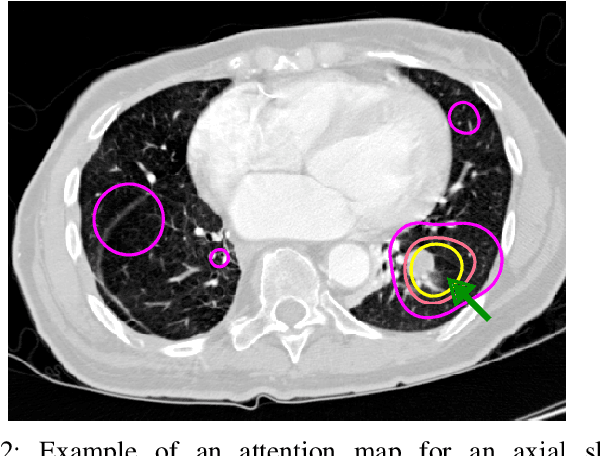
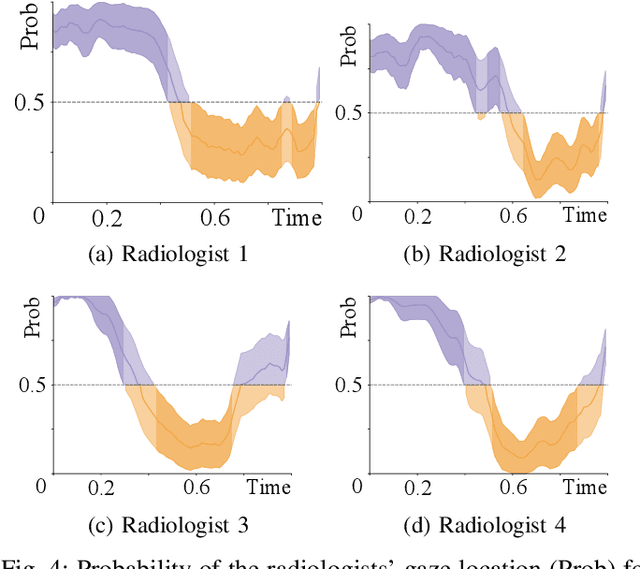
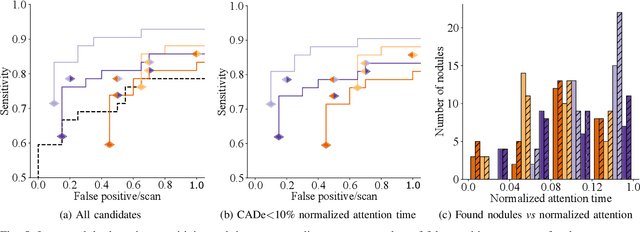
Early diagnosis of lung cancer via computed tomography can significantly reduce the morbidity and mortality rates associated with the pathology. However, search lung nodules is a high complexity task, which affects the success of screening programs. Whilst computer-aided detection systems can be used as second observers, they may bias radiologists and introduce significant time overheads. With this in mind, this study assesses the potential of using gaze information for integrating automatic detection systems in the clinical practice. For that purpose, 4 radiologists were asked to annotate 20 scans from a public dataset while being monitored by an eye tracker device and an automatic lung nodule detection system was developed. Our results show that radiologists follow a similar search routine and tend to have lower fixation periods in regions where finding errors occur. The overall detection sensitivity of the specialists was 0.67$\pm$0.07, whereas the system achieved 0.69. Combining the annotations of one radiologist with the automatic system significantly improves the detection performance to similar levels of two annotators. Likewise, combining the findings of radiologist with the detection algorithm only for low fixation regions still significantly improves the detection sensitivity without increasing the number of false-positives. The combination of the automatic system with the gaze information allows to mitigate possible errors of the radiologist without some of the issues usually associated with automatic detection system.