 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTweet Insights: A Visualization Platform to Extract Temporal Insights from Twitter
Aug 04, 2023
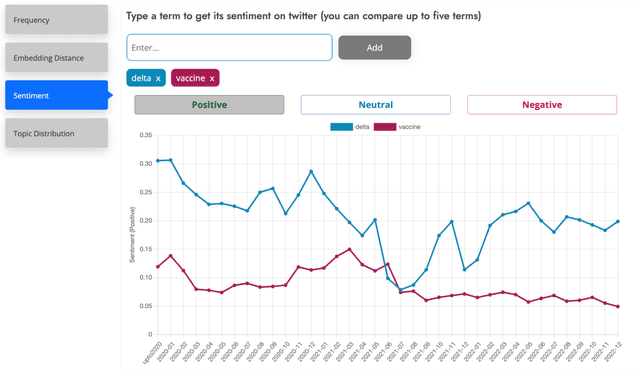
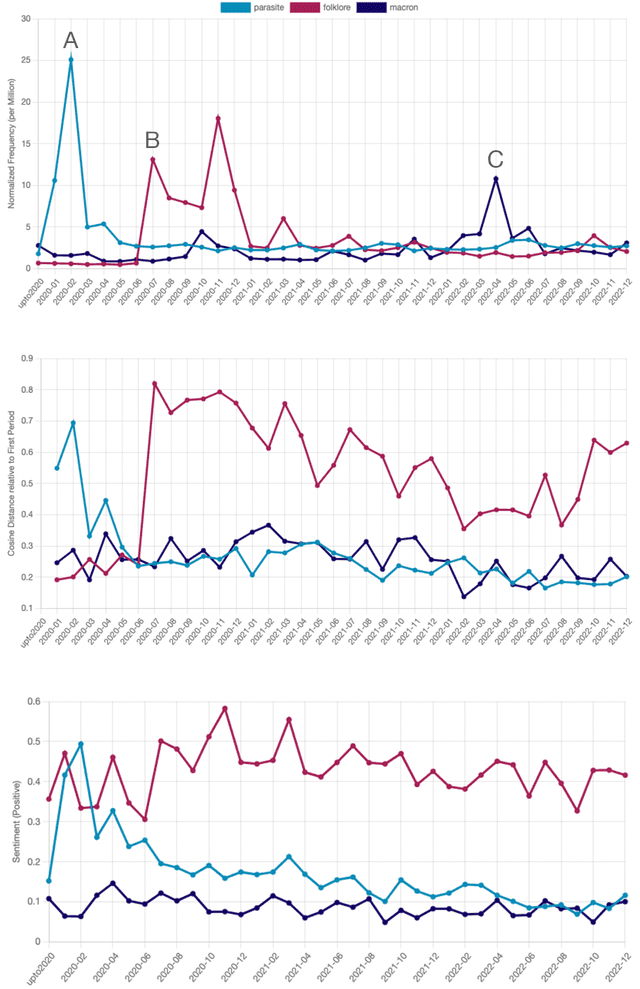
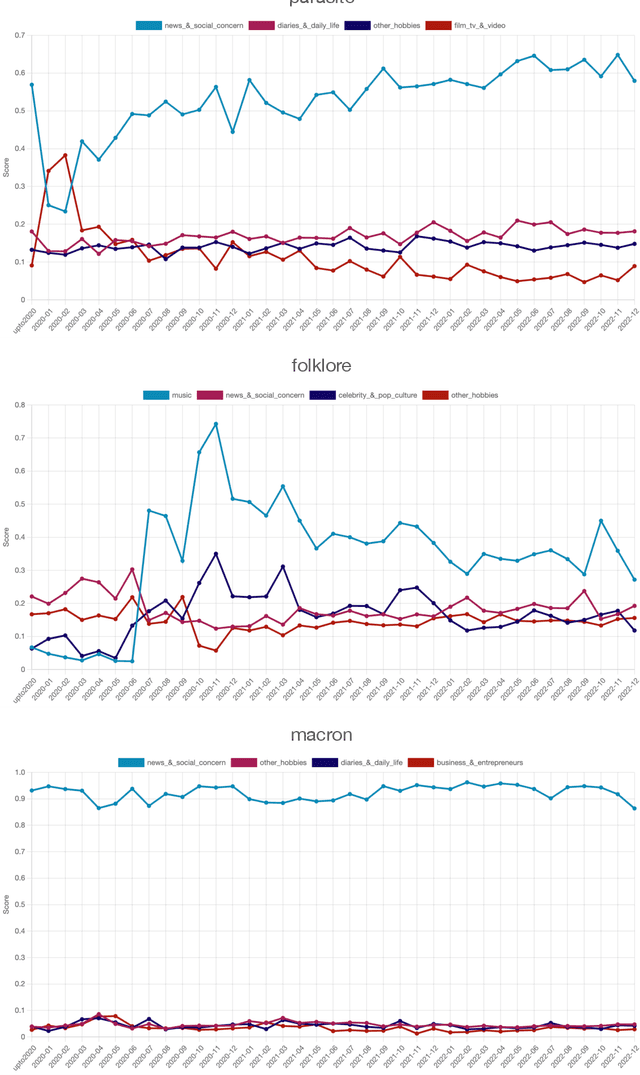
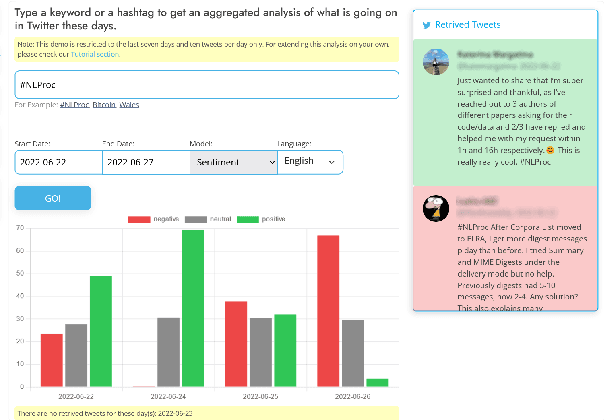
This paper introduces a large collection of time series data derived from Twitter, postprocessed using word embedding techniques, as well as specialized fine-tuned language models. This data comprises the past five years and captures changes in n-gram frequency, similarity, sentiment and topic distribution. The interface built on top of this data enables temporal analysis for detecting and characterizing shifts in meaning, including complementary information to trending metrics, such as sentiment and topic association over time. We release an online demo for easy experimentation, and we share code and the underlying aggregated data for future work. In this paper, we also discuss three case studies unlocked thanks to our platform, showcasing its potential for temporal linguistic analysis.
Probing Commonsense Knowledge in Pre-trained Language Models with Sense-level Precision and Expanded Vocabulary
Oct 12, 2022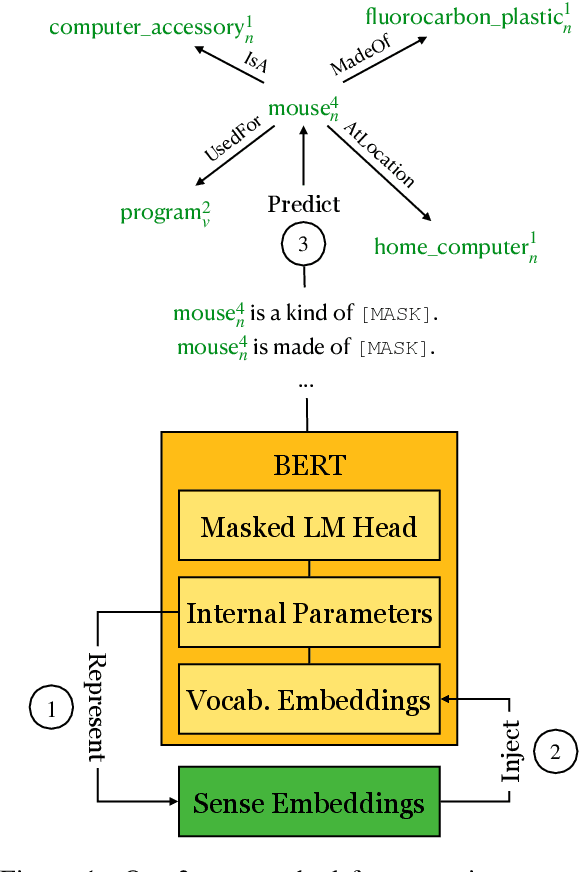
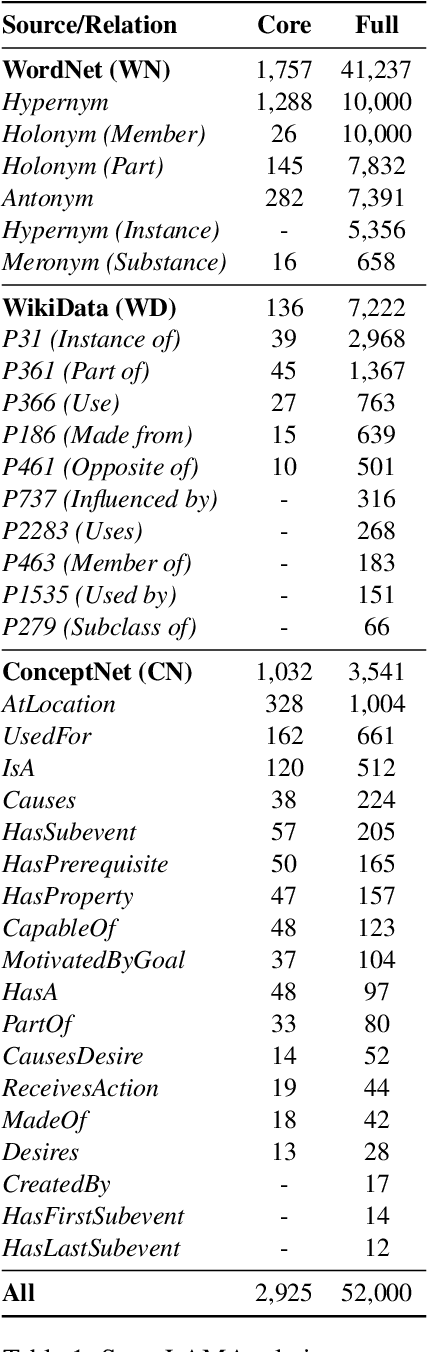
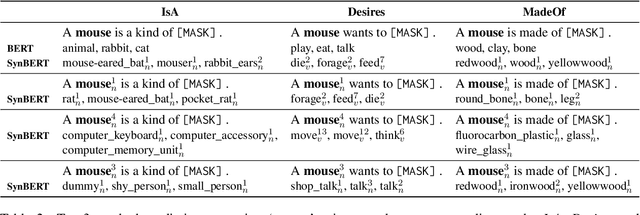
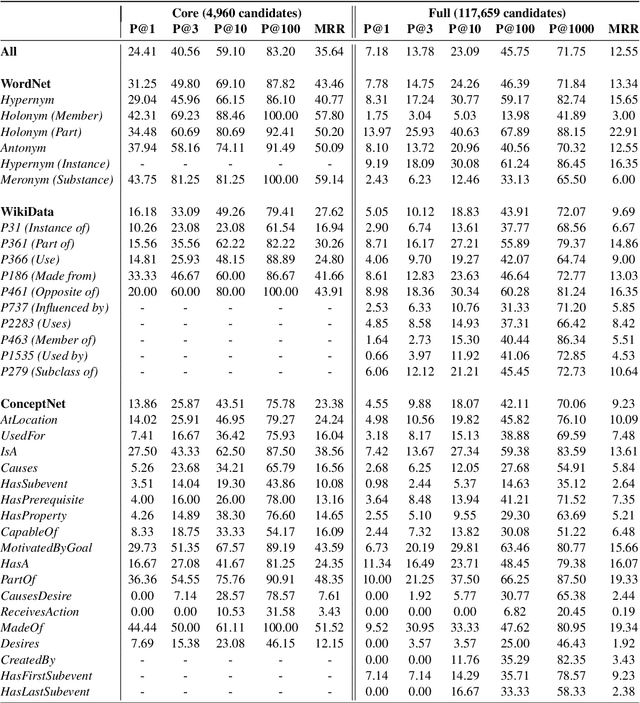
Progress on commonsense reasoning is usually measured from performance improvements on Question Answering tasks designed to require commonsense knowledge. However, fine-tuning large Language Models (LMs) on these specific tasks does not directly evaluate commonsense learned during pre-training. The most direct assessments of commonsense knowledge in pre-trained LMs are arguably cloze-style tasks targeting commonsense assertions (e.g., A pen is used for [MASK].). However, this approach is restricted by the LM's vocabulary available for masked predictions, and its precision is subject to the context provided by the assertion. In this work, we present a method for enriching LMs with a grounded sense inventory (i.e., WordNet) available at the vocabulary level, without further training. This modification augments the prediction space of cloze-style prompts to the size of a large ontology while enabling finer-grained (sense-level) queries and predictions. In order to evaluate LMs with higher precision, we propose SenseLAMA, a cloze-style task featuring verbalized relations from disambiguated triples sourced from WordNet, WikiData, and ConceptNet. Applying our method to BERT, producing a WordNet-enriched version named SynBERT, we find that LMs can learn non-trivial commonsense knowledge from self-supervision, covering numerous relations, and more effectively than comparable similarity-based approaches.
TempoWiC: An Evaluation Benchmark for Detecting Meaning Shift in Social Media
Sep 16, 2022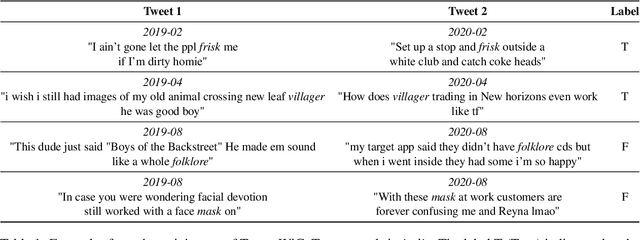
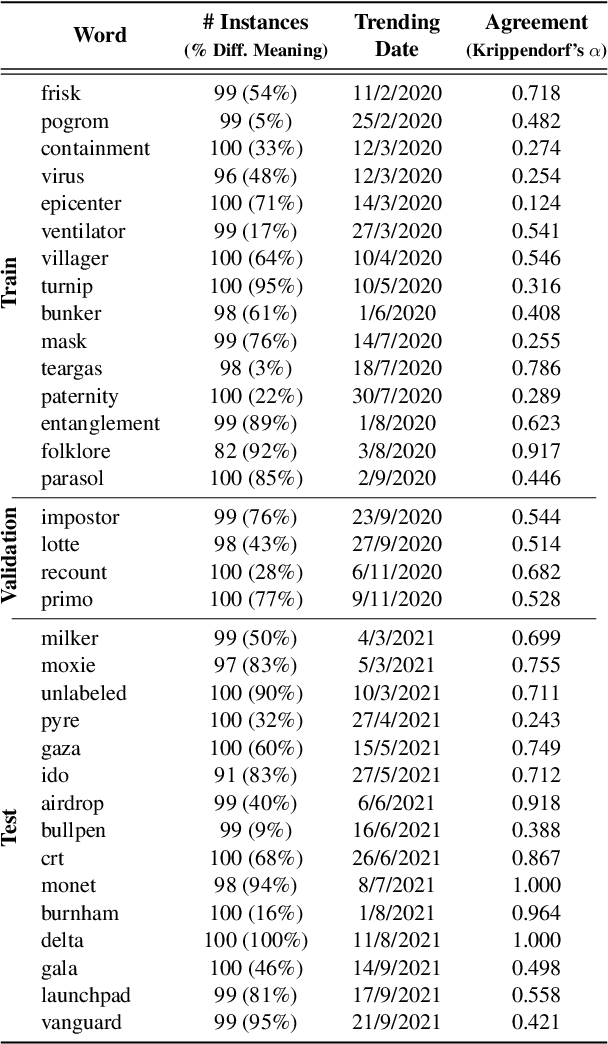
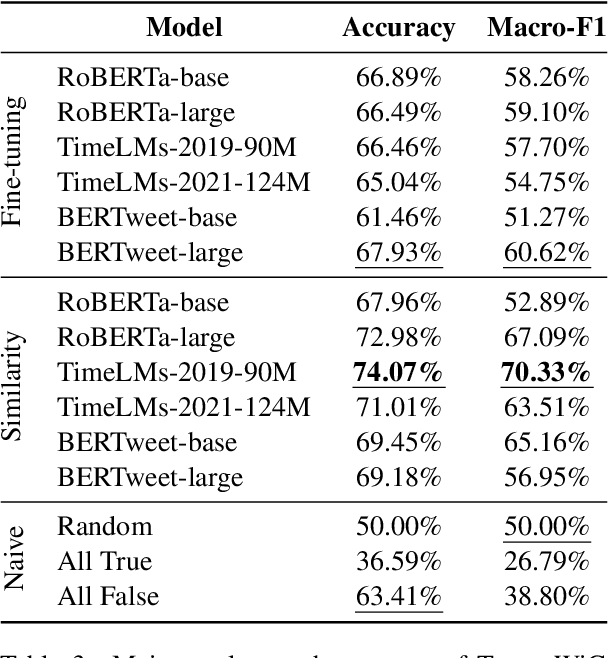
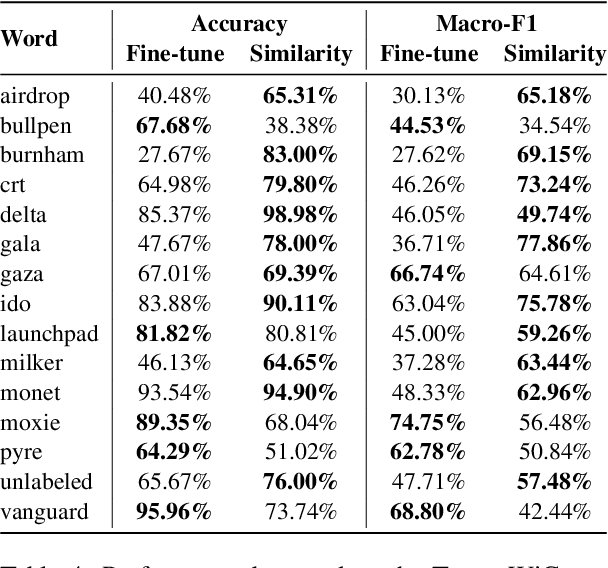
Language evolves over time, and word meaning changes accordingly. This is especially true in social media, since its dynamic nature leads to faster semantic shifts, making it challenging for NLP models to deal with new content and trends. However, the number of datasets and models that specifically address the dynamic nature of these social platforms is scarce. To bridge this gap, we present TempoWiC, a new benchmark especially aimed at accelerating research in social media-based meaning shift. Our results show that TempoWiC is a challenging benchmark, even for recently-released language models specialized in social media.
TweetNLP: Cutting-Edge Natural Language Processing for Social Media
Jun 29, 2022
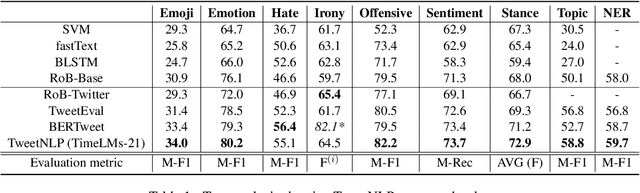

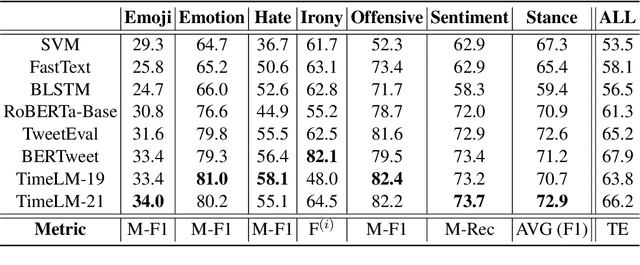
In this paper we present TweetNLP, an integrated platform for Natural Language Processing (NLP) in social media. TweetNLP supports a diverse set of NLP tasks, including generic focus areas such as sentiment analysis and named entity recognition, as well as social media-specific tasks such as emoji prediction and offensive language identification. Task-specific systems are powered by reasonably-sized Transformer-based language models specialized on social media text (in particular, Twitter) which can be run without the need for dedicated hardware or cloud services. The main contributions of TweetNLP are: (1) an integrated Python library for a modern toolkit supporting social media analysis using our various task-specific models adapted to the social domain; (2) an interactive online demo for codeless experimentation using our models; and (3) a tutorial covering a wide variety of typical social media applications.
TimeLMs: Diachronic Language Models from Twitter
Feb 08, 2022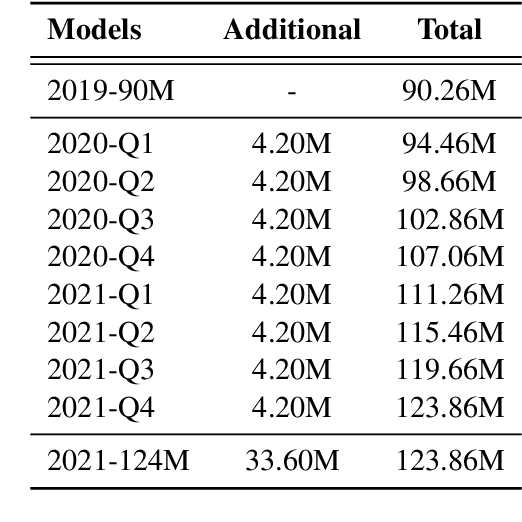
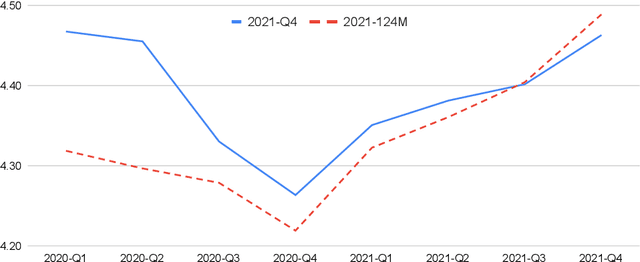
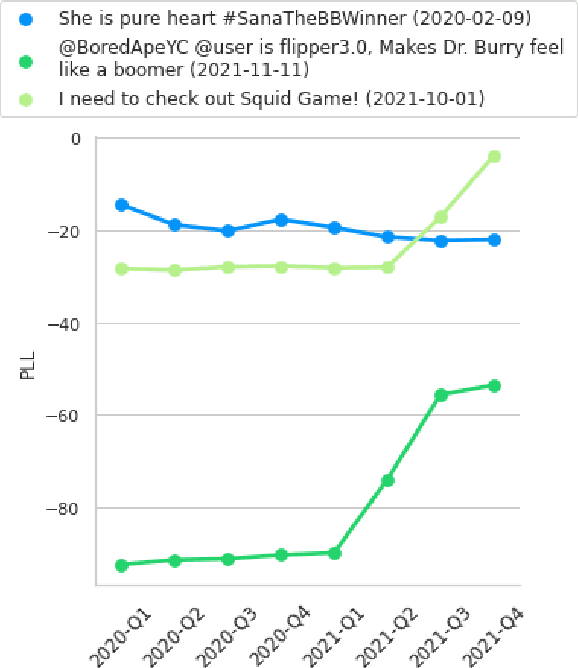
Despite its importance, the time variable has been largely neglected in the NLP and language model literature. In this paper, we present TimeLMs, a set of language models specialized on diachronic Twitter data. We show that a continual learning strategy contributes to enhancing Twitter-based language models' capacity to deal with future and out-of-distribution tweets, while making them competitive with standardized and more monolithic benchmarks. We also perform a number of qualitative analyses showing how they cope with trends and peaks in activity involving specific named entities or concept drift.
LMMS Reloaded: Transformer-based Sense Embeddings for Disambiguation and Beyond
May 26, 2021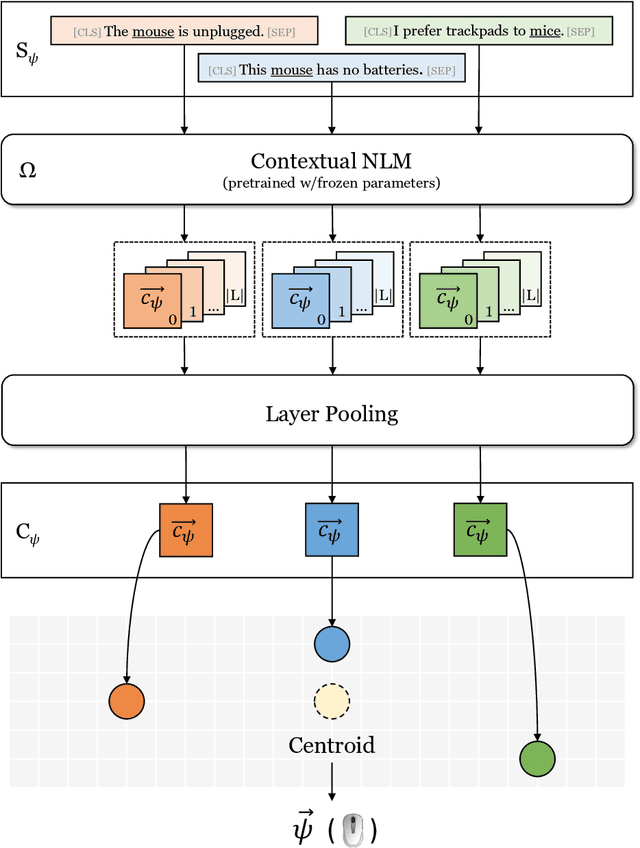
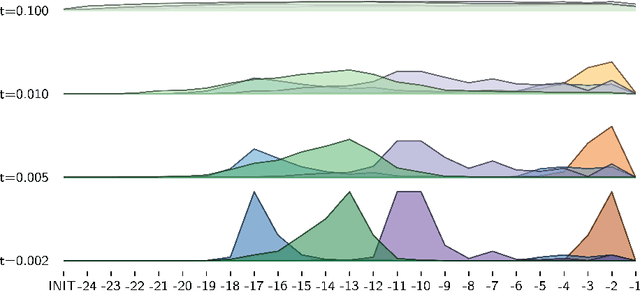
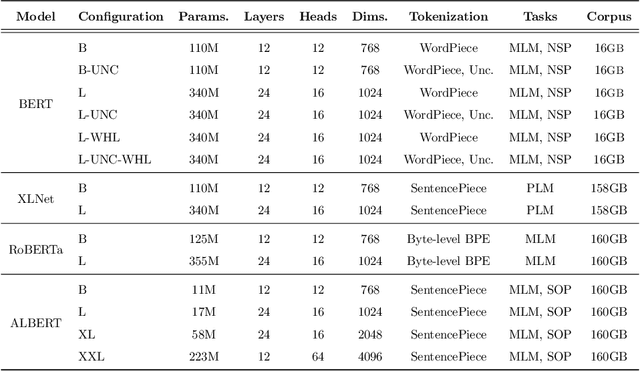
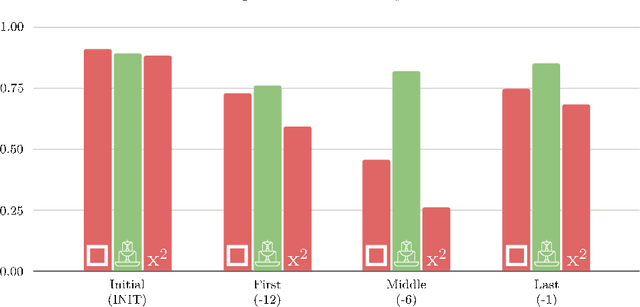
Distributional semantics based on neural approaches is a cornerstone of Natural Language Processing, with surprising connections to human meaning representation as well. Recent Transformer-based Language Models have proven capable of producing contextual word representations that reliably convey sense-specific information, simply as a product of self-supervision. Prior work has shown that these contextual representations can be used to accurately represent large sense inventories as sense embeddings, to the extent that a distance-based solution to Word Sense Disambiguation (WSD) tasks outperforms models trained specifically for the task. Still, there remains much to understand on how to use these Neural Language Models (NLMs) to produce sense embeddings that can better harness each NLM's meaning representation abilities. In this work we introduce a more principled approach to leverage information from all layers of NLMs, informed by a probing analysis on 14 NLM variants. We also emphasize the versatility of these sense embeddings in contrast to task-specific models, applying them on several sense-related tasks, besides WSD, while demonstrating improved performance using our proposed approach over prior work focused on sense embeddings. Finally, we discuss unexpected findings regarding layer and model performance variations, and potential applications for downstream tasks.
Transformers and Transfer Learning for Improving Portuguese Semantic Role Labeling
Jan 06, 2021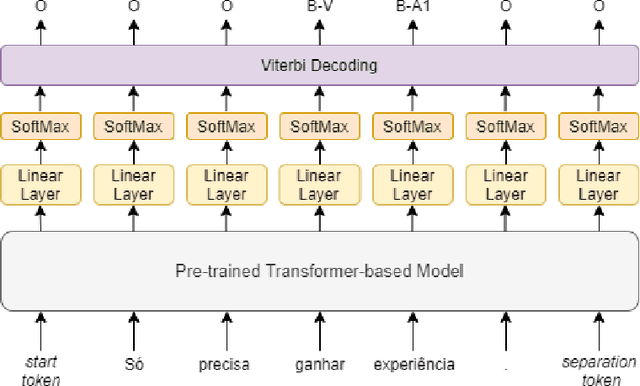



Semantic Role Labeling (SRL) is a core Natural Language Processing task. For English, recent methods based on Transformer models have allowed for major improvements over the previous state of the art. However, for low resource languages, and in particular for Portuguese, currently available SRL models are hindered by scarce training data. In this paper, we explore a model architecture with only a pre-trained BERT-based model, a linear layer, softmax and Viterbi decoding. We substantially improve the state of the art performance in Portuguese by over 15$F_1$. Additionally, we improve SRL results in Portuguese corpora by exploiting cross-lingual transfer learning using multilingual pre-trained models (XLM-R), and transfer learning from dependency parsing in Portuguese. We evaluate the various proposed approaches empirically and as result we present an heuristic that supports the choice of the most appropriate model considering the available resources.
Language Models and Word Sense Disambiguation: An Overview and Analysis
Aug 26, 2020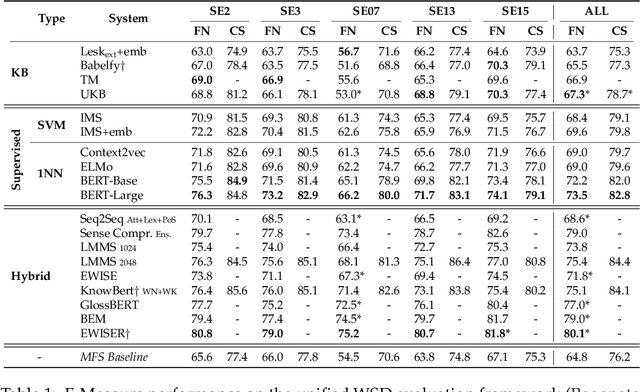
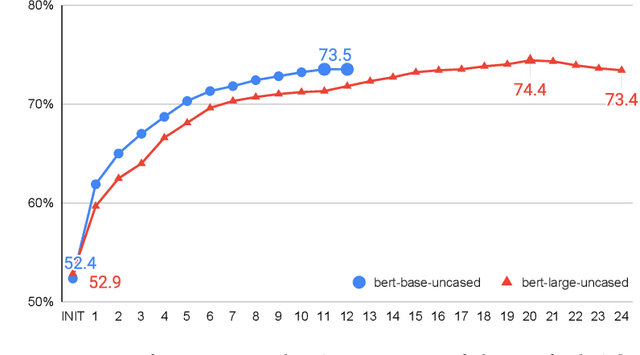

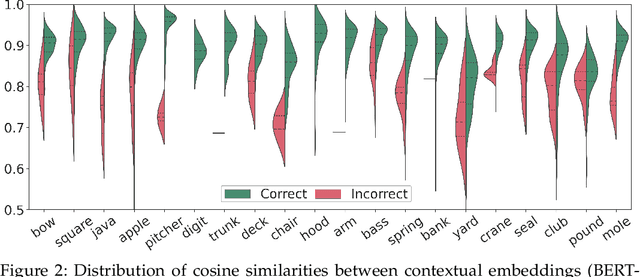
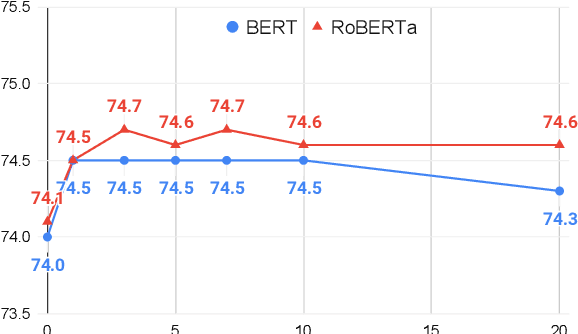
Transformer-based language models have taken many fields in NLP by storm. BERT and its derivatives dominate most of the existing evaluation benchmarks, including those for Word Sense Disambiguation (WSD), thanks to their ability in capturing context-sensitive semantic nuances. However, there is still little knowledge about their capabilities and potential limitations for encoding and recovering word senses. In this article, we provide an in-depth quantitative and qualitative analysis of the celebrated BERT model with respect to lexical ambiguity. One of the main conclusions of our analysis is that BERT performs a decent job in capturing high-level sense distinctions, even when a limited number of examples is available for each word sense. Our analysis also reveals that in some cases language models come close to solving coarse-grained noun disambiguation under ideal conditions in terms of availability of training data and computing resources. However, this scenario rarely occurs in real-world settings and, hence, many practical challenges remain even in the coarse-grained setting. We also perform an in-depth comparison of the two main language model based WSD strategies, i.e., fine-tuning and feature extraction, finding that the latter approach is more robust with respect to sense bias and it can better exploit limited available training data.
Don't Neglect the Obvious: On the Role of Unambiguous Words in Word Sense Disambiguation
Apr 29, 2020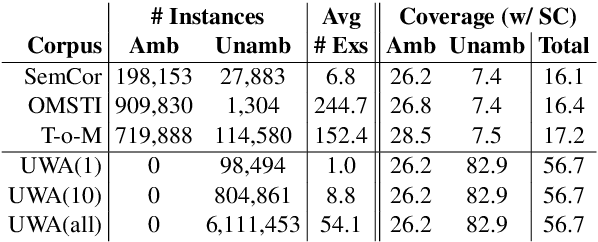
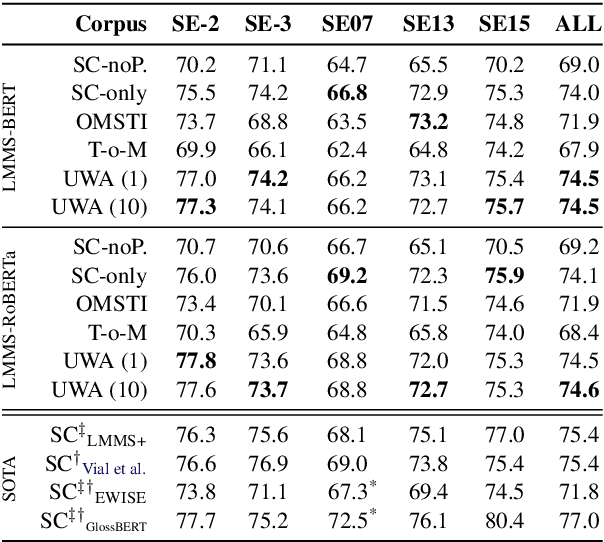
State-of-the-art methods for Word Sense Disambiguation (WSD) combine two different features: the power of pre-trained language models and a propagation method to extend the coverage of such models. This propagation is needed as current sense-annotated corpora lack coverage of many instances in the underlying sense inventory (usually WordNet). At the same time, unambiguous words make for a large portion of all words in WordNet, while being poorly covered in existing sense-annotated corpora. In this paper we propose a simple method to provide annotations for most unambiguous words in a large corpus. We introduce the UWA (Unambiguous Word Annotations) dataset and show how a state-of-the-art propagation-based model can use it to extend the coverage and quality of its word sense embeddings by a significant margin, improving on its original results on WSD.
Language Modelling Makes Sense: Propagating Representations through WordNet for Full-Coverage Word Sense Disambiguation
Jun 24, 2019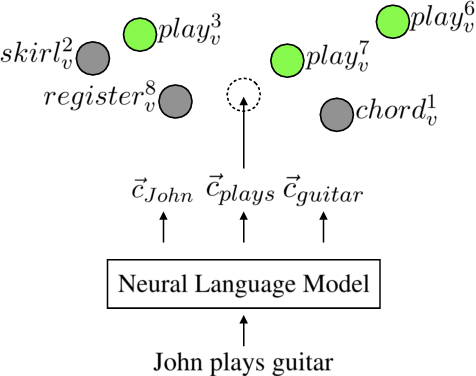

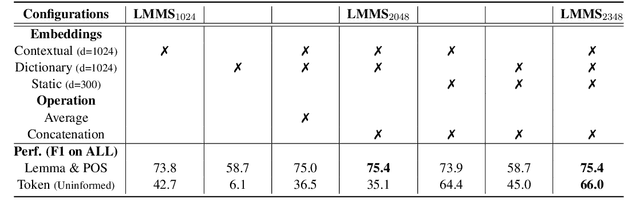
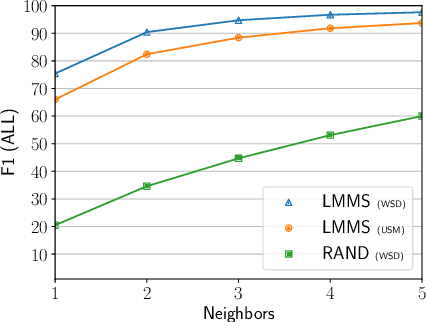
Contextual embeddings represent a new generation of semantic representations learned from Neural Language Modelling (NLM) that addresses the issue of meaning conflation hampering traditional word embeddings. In this work, we show that contextual embeddings can be used to achieve unprecedented gains in Word Sense Disambiguation (WSD) tasks. Our approach focuses on creating sense-level embeddings with full-coverage of WordNet, and without recourse to explicit knowledge of sense distributions or task-specific modelling. As a result, a simple Nearest Neighbors (k-NN) method using our representations is able to consistently surpass the performance of previous systems using powerful neural sequencing models. We also analyse the robustness of our approach when ignoring part-of-speech and lemma features, requiring disambiguation against the full sense inventory, and revealing shortcomings to be improved. Finally, we explore applications of our sense embeddings for concept-level analyses of contextual embeddings and their respective NLMs.