 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTweet Insights: A Visualization Platform to Extract Temporal Insights from Twitter
Paper and Code
Aug 04, 2023
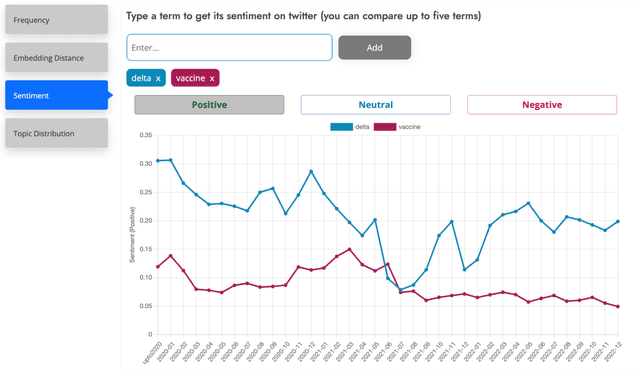
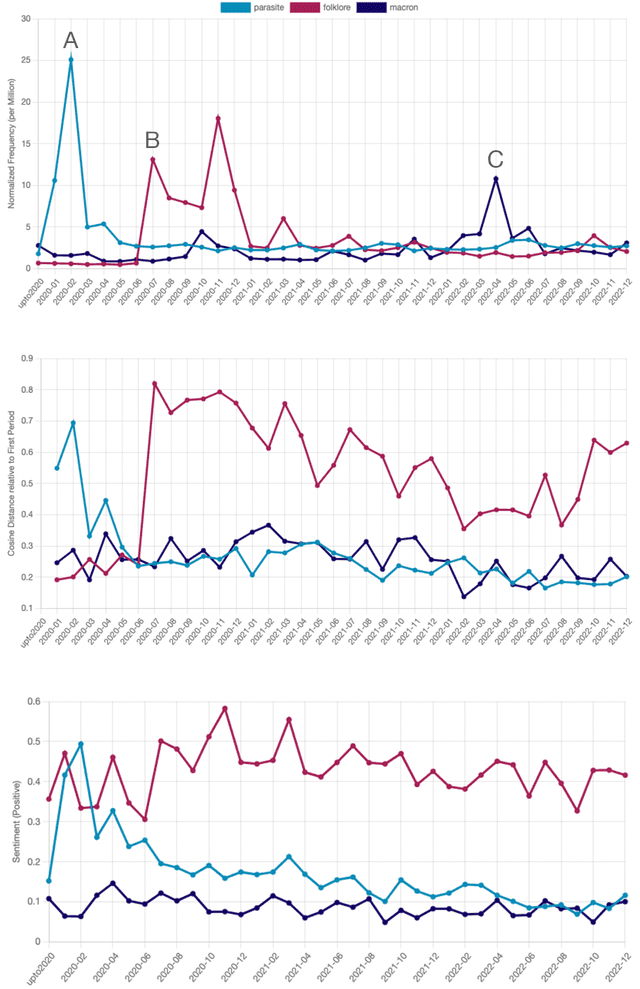
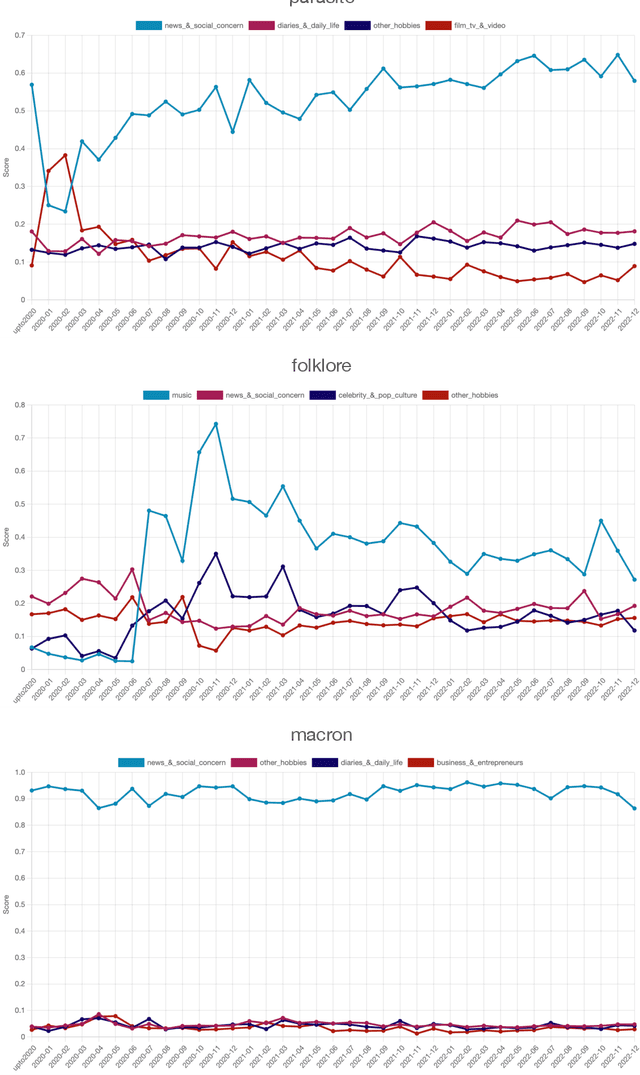
This paper introduces a large collection of time series data derived from Twitter, postprocessed using word embedding techniques, as well as specialized fine-tuned language models. This data comprises the past five years and captures changes in n-gram frequency, similarity, sentiment and topic distribution. The interface built on top of this data enables temporal analysis for detecting and characterizing shifts in meaning, including complementary information to trending metrics, such as sentiment and topic association over time. We release an online demo for easy experimentation, and we share code and the underlying aggregated data for future work. In this paper, we also discuss three case studies unlocked thanks to our platform, showcasing its potential for temporal linguistic analysis.