 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring State Tracking Capabilities of Large Language Models
Nov 13, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in solving complex tasks, including those requiring a certain level of reasoning. In this paper, we focus on state tracking, a problem where models need to keep track of the state governing a number of entities. To isolate the state tracking component from other factors, we propose a benchmark based on three well-defined state tracking tasks and analyse the performance of LLMs in different scenarios. The results indicate that the recent generation of LLMs (specifically, GPT-4 and Llama3) are capable of tracking state, especially when integrated with mechanisms such as Chain of Thought. However, models from the former generation, while understanding the task and being able to solve it at the initial stages, often fail at this task after a certain number of steps.
SuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research
Oct 23, 2023


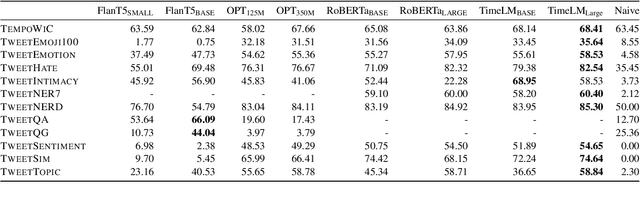
Despite its relevance, the maturity of NLP for social media pales in comparison with general-purpose models, metrics and benchmarks. This fragmented landscape makes it hard for the community to know, for instance, given a task, which is the best performing model and how it compares with others. To alleviate this issue, we introduce a unified benchmark for NLP evaluation in social media, SuperTweetEval, which includes a heterogeneous set of tasks and datasets combined, adapted and constructed from scratch. We benchmarked the performance of a wide range of models on SuperTweetEval and our results suggest that, despite the recent advances in language modelling, social media remains challenging.
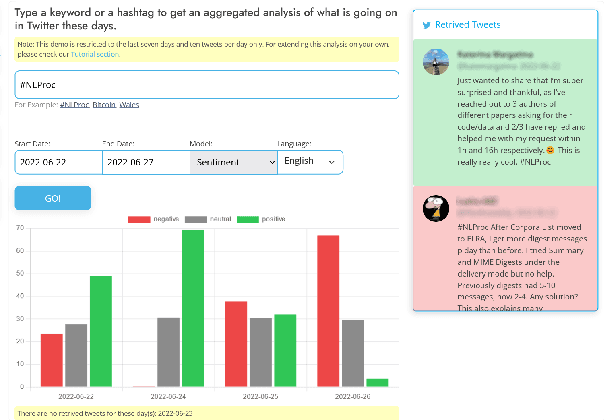
Tweet Insights: A Visualization Platform to Extract Temporal Insights from Twitter
Aug 04, 2023
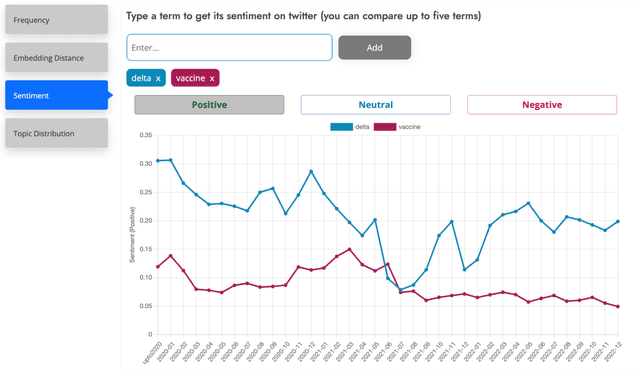
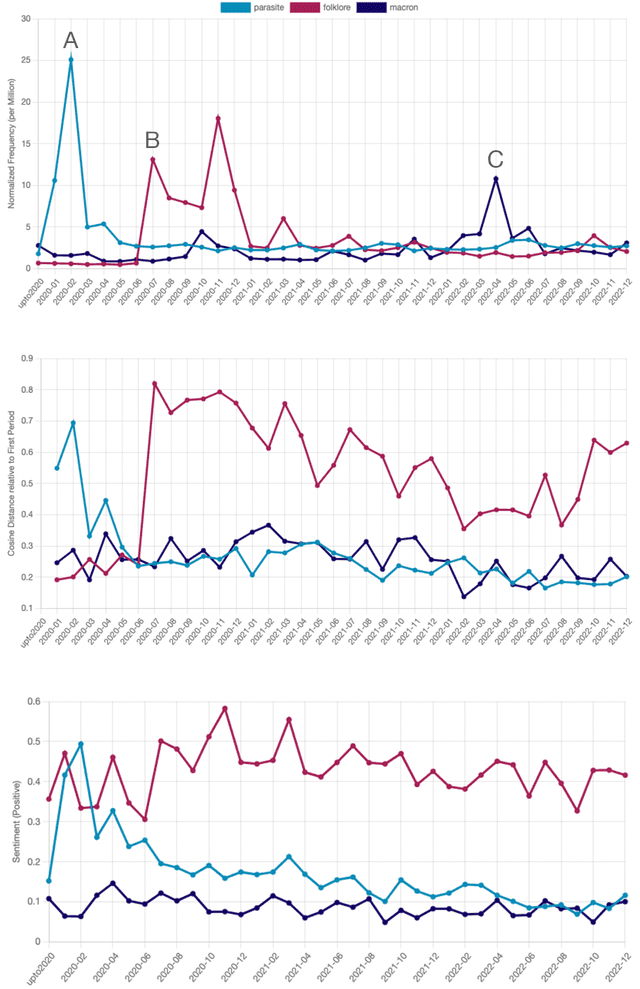
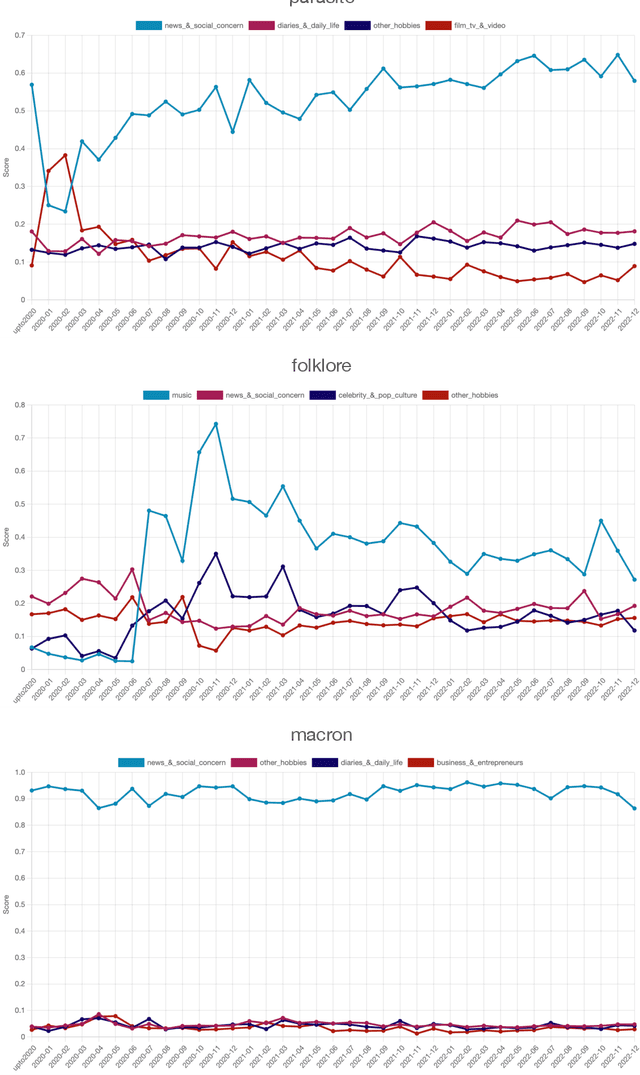
This paper introduces a large collection of time series data derived from Twitter, postprocessed using word embedding techniques, as well as specialized fine-tuned language models. This data comprises the past five years and captures changes in n-gram frequency, similarity, sentiment and topic distribution. The interface built on top of this data enables temporal analysis for detecting and characterizing shifts in meaning, including complementary information to trending metrics, such as sentiment and topic association over time. We release an online demo for easy experimentation, and we share code and the underlying aggregated data for future work. In this paper, we also discuss three case studies unlocked thanks to our platform, showcasing its potential for temporal linguistic analysis.
TweetNLP: Cutting-Edge Natural Language Processing for Social Media
Jun 29, 2022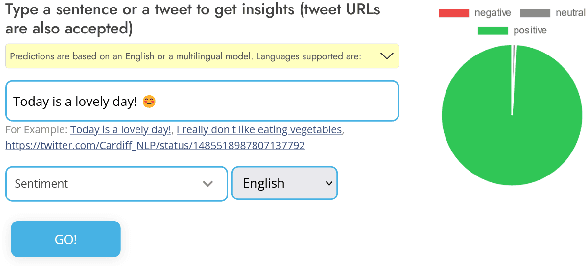
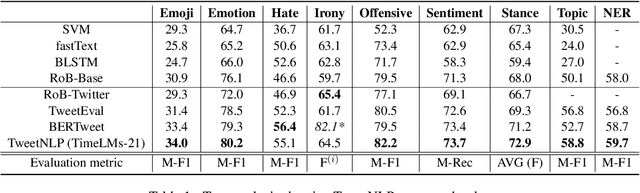

In this paper we present TweetNLP, an integrated platform for Natural Language Processing (NLP) in social media. TweetNLP supports a diverse set of NLP tasks, including generic focus areas such as sentiment analysis and named entity recognition, as well as social media-specific tasks such as emoji prediction and offensive language identification. Task-specific systems are powered by reasonably-sized Transformer-based language models specialized on social media text (in particular, Twitter) which can be run without the need for dedicated hardware or cloud services. The main contributions of TweetNLP are: (1) an integrated Python library for a modern toolkit supporting social media analysis using our various task-specific models adapted to the social domain; (2) an interactive online demo for codeless experimentation using our models; and (3) a tutorial covering a wide variety of typical social media applications.
Language Models and Word Sense Disambiguation: An Overview and Analysis
Aug 26, 2020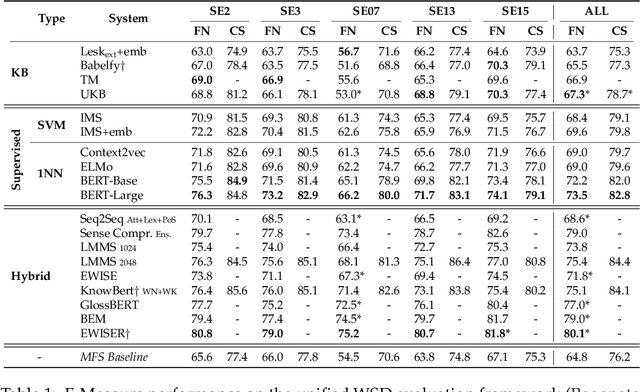
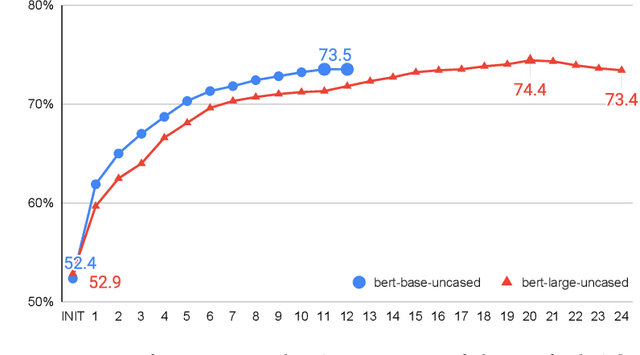

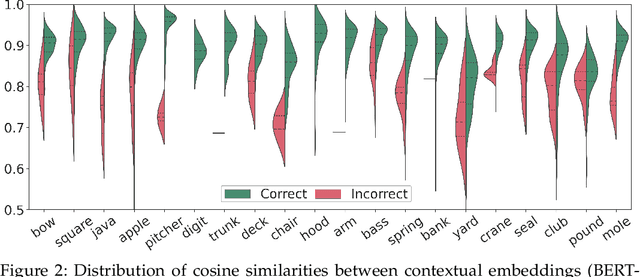
Transformer-based language models have taken many fields in NLP by storm. BERT and its derivatives dominate most of the existing evaluation benchmarks, including those for Word Sense Disambiguation (WSD), thanks to their ability in capturing context-sensitive semantic nuances. However, there is still little knowledge about their capabilities and potential limitations for encoding and recovering word senses. In this article, we provide an in-depth quantitative and qualitative analysis of the celebrated BERT model with respect to lexical ambiguity. One of the main conclusions of our analysis is that BERT performs a decent job in capturing high-level sense distinctions, even when a limited number of examples is available for each word sense. Our analysis also reveals that in some cases language models come close to solving coarse-grained noun disambiguation under ideal conditions in terms of availability of training data and computing resources. However, this scenario rarely occurs in real-world settings and, hence, many practical challenges remain even in the coarse-grained setting. We also perform an in-depth comparison of the two main language model based WSD strategies, i.e., fine-tuning and feature extraction, finding that the latter approach is more robust with respect to sense bias and it can better exploit limited available training data.
WiC-TSV: An Evaluation Benchmark for Target Sense Verification of Words in Context
Apr 30, 2020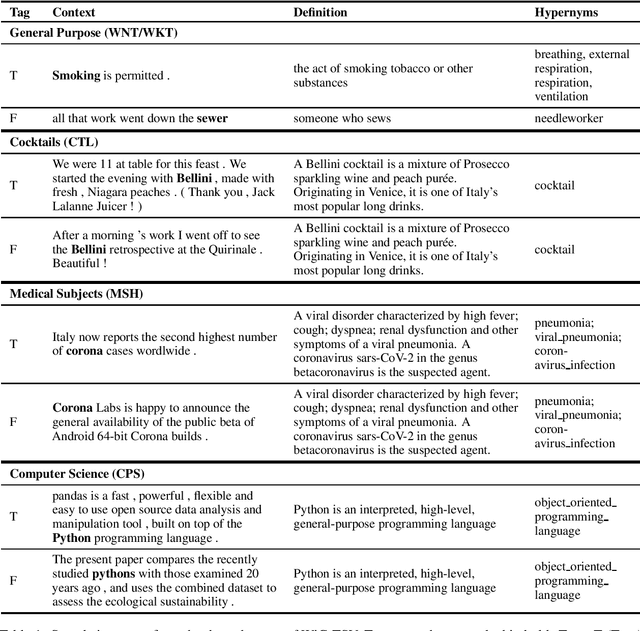
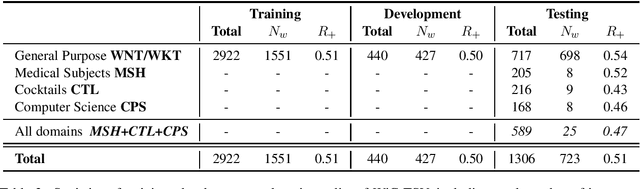
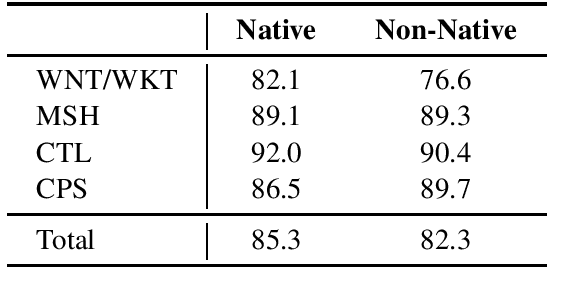
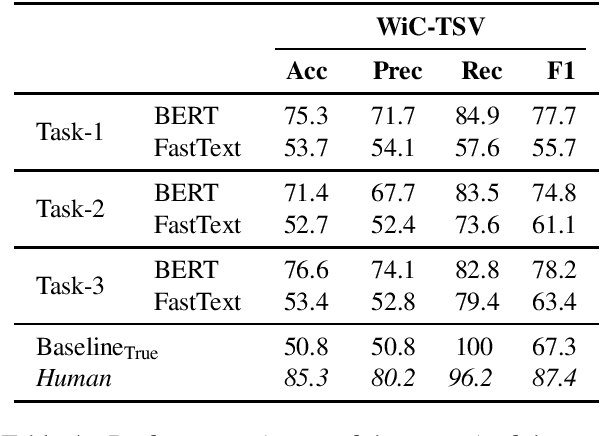
In this paper, we present WiC-TSV (\textit{Target Sense Verification for Words in Context}), a new multi-domain evaluation benchmark for Word Sense Disambiguation (WSD) and Entity Linking (EL). Our benchmark is different from conventional WSD and EL benchmarks for it being independent of a general sense inventory, making it highly flexible for the evaluation of a diverse set of models and systems in different domains. WiC-TSV is split into three tasks (systems get hypernymy or definitional or both hypernymy and definitional information about the target sense). Test data is available in four domains: general (WordNet), computer science, cocktails and medical concepts. Results show that existing state-of-the-art language models such as BERT can achieve a high performance in both in-domain data and out-of-domain data, but they still have room for improvement. WiC-TSV task data is available at \url{https://competitions.codalab.org/competitions/23683}.