 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing and Organizing Semantic Web and Machine Learning Systems in the SWeMLS-KG
Mar 27, 2023



In line with the general trend in artificial intelligence research to create intelligent systems that combine learning and symbolic components, a new sub-area has emerged that focuses on combining machine learning (ML) components with techniques developed by the Semantic Web (SW) community - Semantic Web Machine Learning (SWeML for short). Due to its rapid growth and impact on several communities in the last two decades, there is a need to better understand the space of these SWeML Systems, their characteristics, and trends. Yet, surveys that adopt principled and unbiased approaches are missing. To fill this gap, we performed a systematic study and analyzed nearly 500 papers published in the last decade in this area, where we focused on evaluating architectural, and application-specific features. Our analysis identified a rapidly growing interest in SWeML Systems, with a high impact on several application domains and tasks. Catalysts for this rapid growth are the increased application of deep learning and knowledge graph technologies. By leveraging the in-depth understanding of this area acquired through this study, a further key contribution of this paper is a classification system for SWeML Systems which we publish as ontology.
WiC-TSV: An Evaluation Benchmark for Target Sense Verification of Words in Context
Apr 30, 2020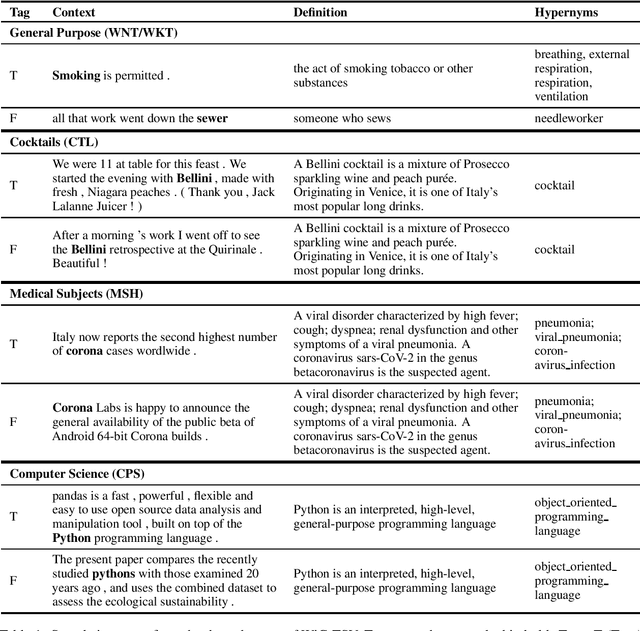
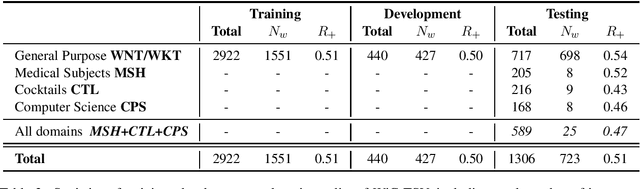
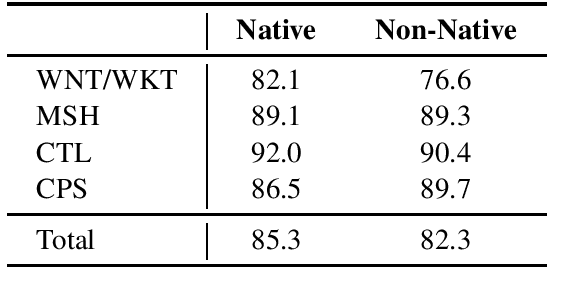
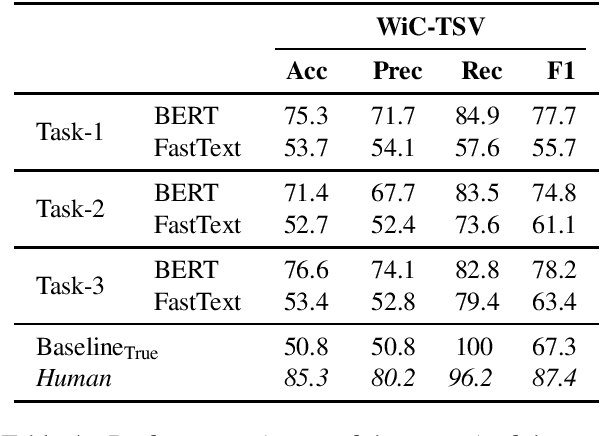
In this paper, we present WiC-TSV (\textit{Target Sense Verification for Words in Context}), a new multi-domain evaluation benchmark for Word Sense Disambiguation (WSD) and Entity Linking (EL). Our benchmark is different from conventional WSD and EL benchmarks for it being independent of a general sense inventory, making it highly flexible for the evaluation of a diverse set of models and systems in different domains. WiC-TSV is split into three tasks (systems get hypernymy or definitional or both hypernymy and definitional information about the target sense). Test data is available in four domains: general (WordNet), computer science, cocktails and medical concepts. Results show that existing state-of-the-art language models such as BERT can achieve a high performance in both in-domain data and out-of-domain data, but they still have room for improvement. WiC-TSV task data is available at \url{https://competitions.codalab.org/competitions/23683}.
Orchestrating NLP Services for the Legal Domain
Mar 28, 2020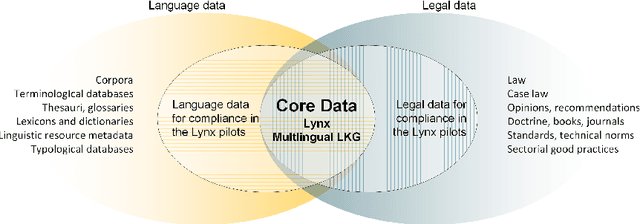
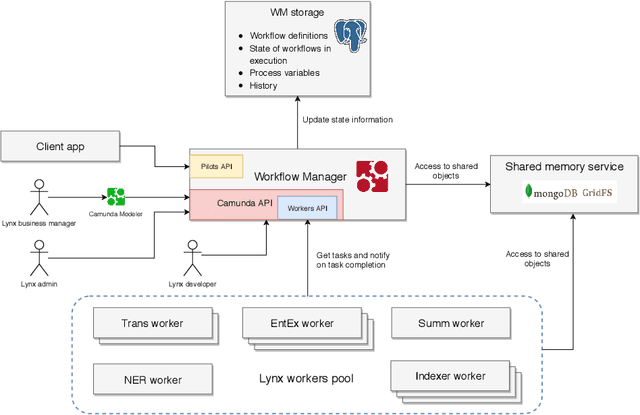
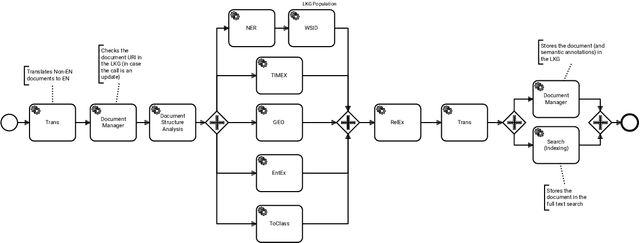
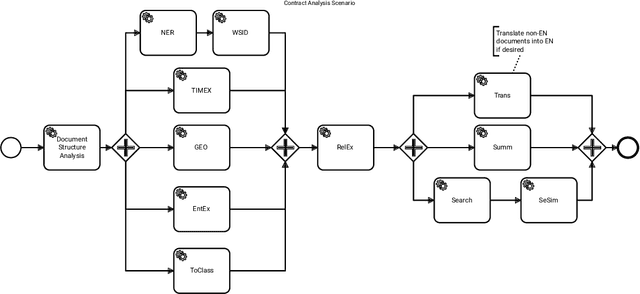
Legal technology is currently receiving a lot of attention from various angles. In this contribution we describe the main technical components of a system that is currently under development in the European innovation project Lynx, which includes partners from industry and research. The key contribution of this paper is a workflow manager that enables the flexible orchestration of workflows based on a portfolio of Natural Language Processing and Content Curation services as well as a Multilingual Legal Knowledge Graph that contains semantic information and meaningful references to legal documents. We also describe different use cases with which we experiment and develop prototypical solutions.
Interactive Error Correction in Implicative Theories
Oct 20, 2014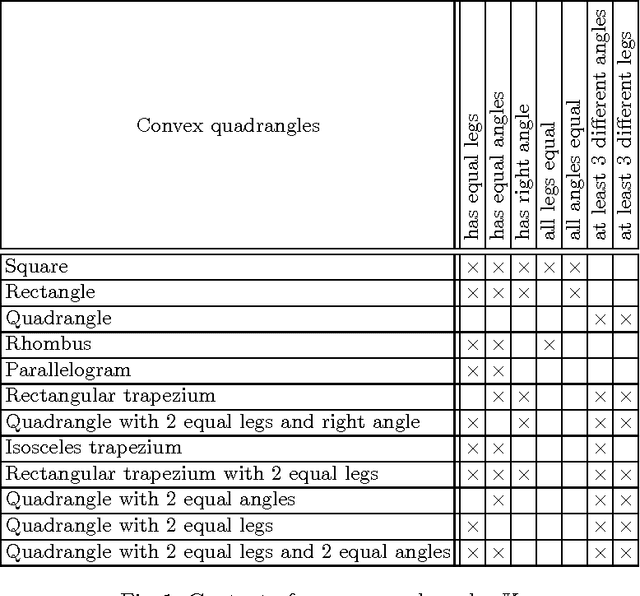

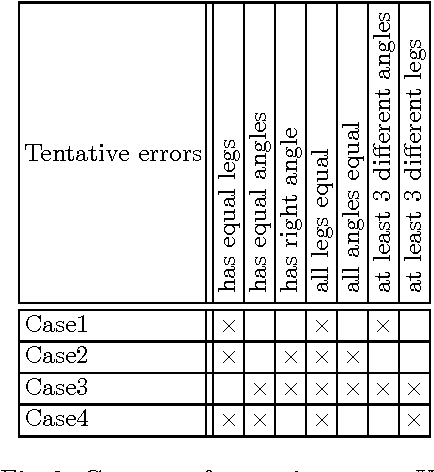
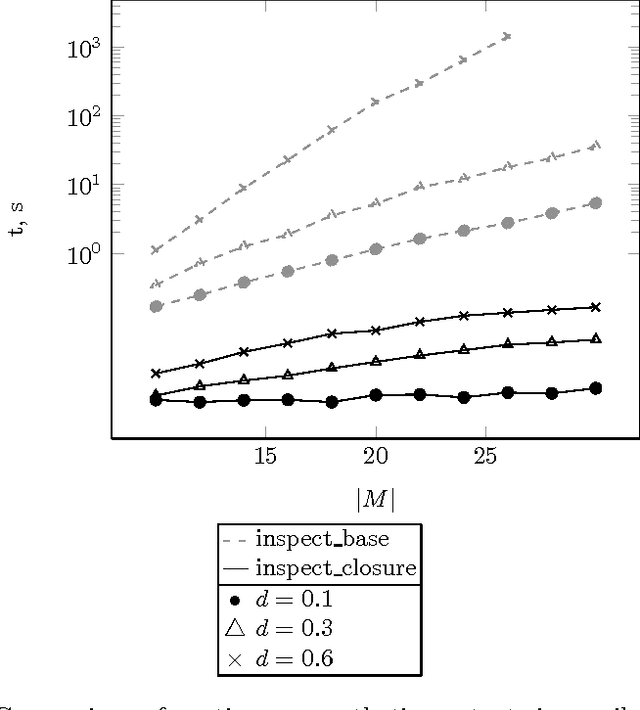
Errors in implicative theories coming from binary data are studied. First, two classes of errors that may affect implicative theories are singled out. Two approaches for finding errors of these classes are proposed, both of them based on methods of Formal Concept Analysis. The first approach uses the cardinality minimal (canonical or Duquenne-Guigues) implication base. The construction of such a base is computationally intractable. Using an alternative approach one checks possible errors on the fly in polynomial time via computing closures of subsets of attributes. Both approaches are interactive, based on questions about the validity of certain implications. Results of computer experiments are presented and discussed.