 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEl Departamento de Nosotros: How Machine Translated Corpora Affects Language Models in MRC Tasks
Jul 03, 2020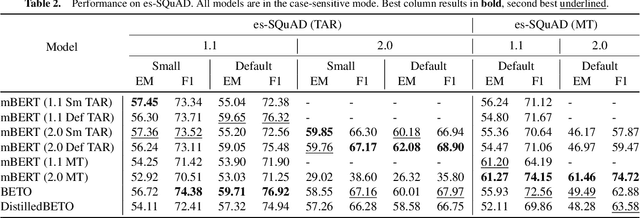
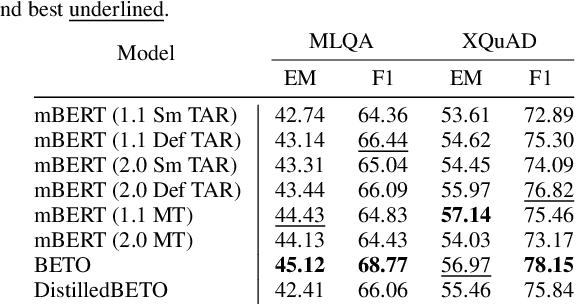
Pre-training large-scale language models (LMs) requires huge amounts of text corpora. LMs for English enjoy ever growing corpora of diverse language resources. However, less resourced languages and their mono- and multilingual LMs often struggle to obtain bigger datasets. A typical approach in this case implies using machine translation of English corpora to a target language. In this work, we study the caveats of applying directly translated corpora for fine-tuning LMs for downstream natural language processing tasks and demonstrate that careful curation along with post-processing lead to improved performance and overall LMs robustness. In the empirical evaluation, we perform a comparison of directly translated against curated Spanish SQuAD datasets on both user and system levels. Further experimental results on XQuAD and MLQA transfer-learning evaluation question answering tasks show that presumably multilingual LMs exhibit more resilience to machine translation artifacts in terms of the exact match score.
Orchestrating NLP Services for the Legal Domain
Mar 28, 2020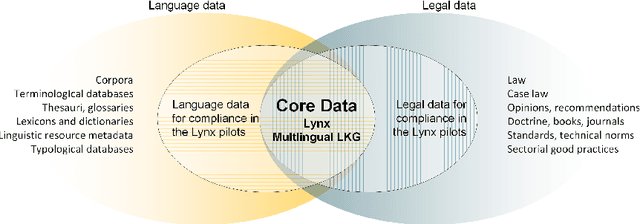
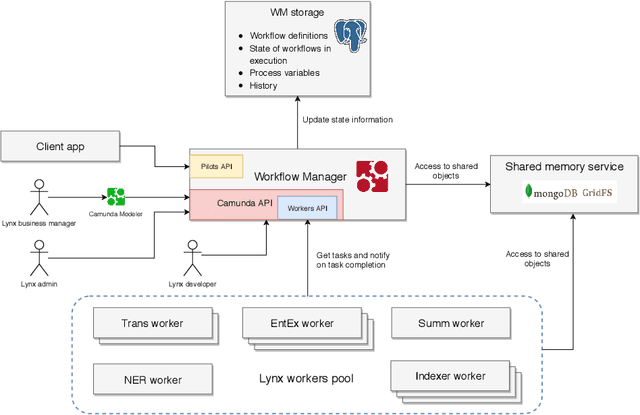
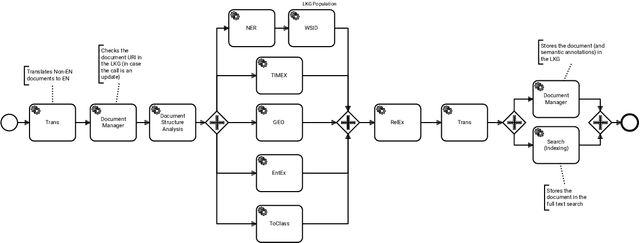
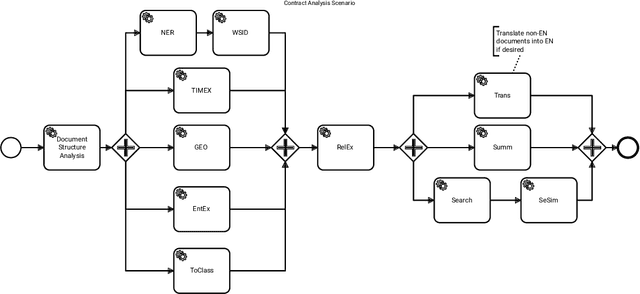
Legal technology is currently receiving a lot of attention from various angles. In this contribution we describe the main technical components of a system that is currently under development in the European innovation project Lynx, which includes partners from industry and research. The key contribution of this paper is a workflow manager that enables the flexible orchestration of workflows based on a portfolio of Natural Language Processing and Content Curation services as well as a Multilingual Legal Knowledge Graph that contains semantic information and meaningful references to legal documents. We also describe different use cases with which we experiment and develop prototypical solutions.