 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal concept analysis for evaluating intrinsic dimension of a natural language
Nov 17, 2023Some results of a computational experiment for determining the intrinsic dimension of linguistic varieties for the Bengali and Russian languages are presented. At the same time, both sets of words and sets of bigrams in these languages were considered separately. The method used to solve this problem was based on formal concept analysis algorithms. It was found that the intrinsic dimensions of these languages are significantly less than the dimensions used in popular neural network models in natural language processing.
Delta-Closure Structure for Studying Data Distribution
Oct 13, 2022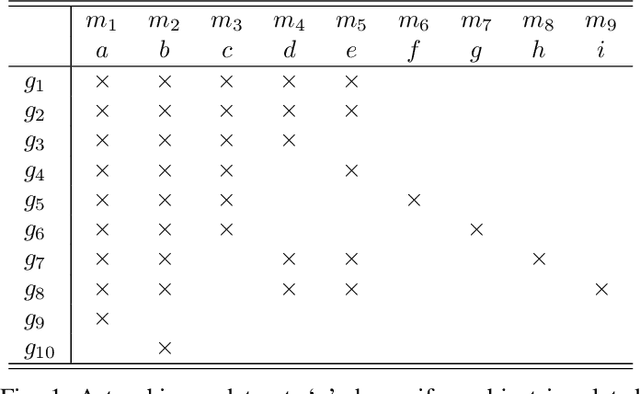
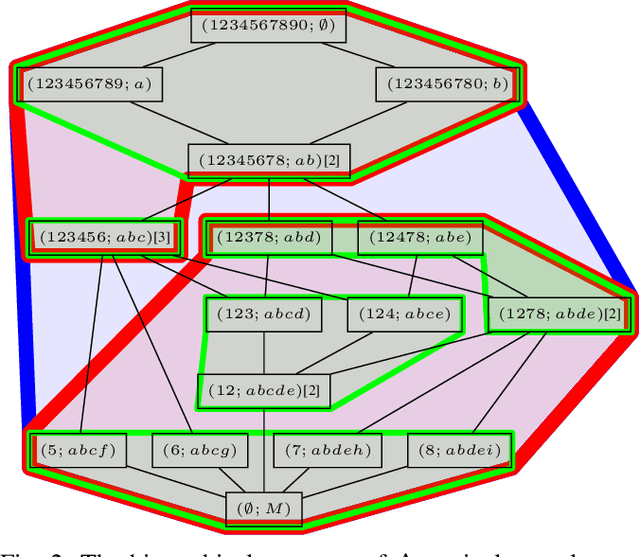
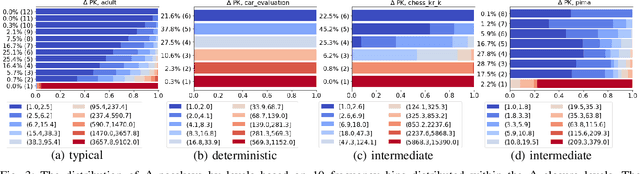
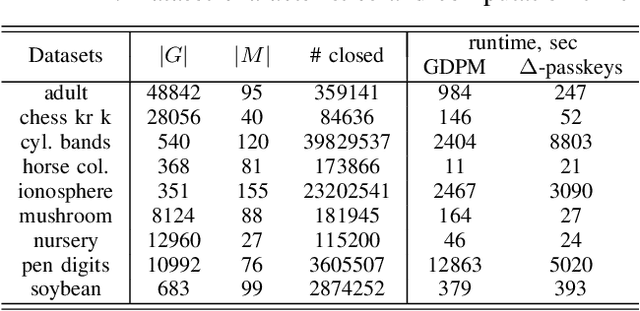
In this paper, we revisit pattern mining and study the distribution underlying a binary dataset thanks to the closure structure which is based on passkeys, i.e., minimum generators in equivalence classes robust to noise. We introduce $\Delta$-closedness, a generalization of the closure operator, where $\Delta$ measures how a closed set differs from its upper neighbors in the partial order induced by closure. A $\Delta$-class of equivalence includes minimum and maximum elements and allows us to characterize the distribution underlying the data. Moreover, the set of $\Delta$-classes of equivalence can be partitioned into the so-called $\Delta$-closure structure. In particular, a $\Delta$-class of equivalence with a high level demonstrates correlations among many attributes, which are supported by more observations when $\Delta$ is large. In the experiments, we study the $\Delta$-closure structure of several real-world datasets and show that this structure is very stable for large $\Delta$ and does not substantially depend on the data sampling used for the analysis.
Decision Concept Lattice vs. Decision Trees and Random Forests
Jun 01, 2021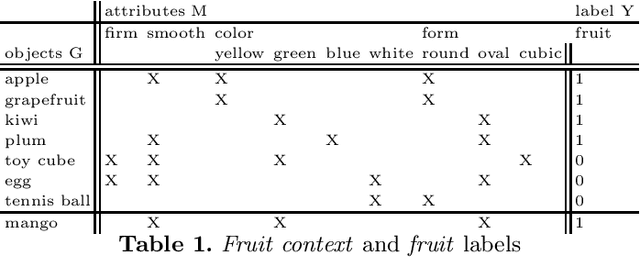
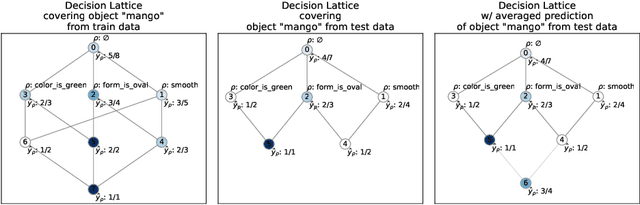
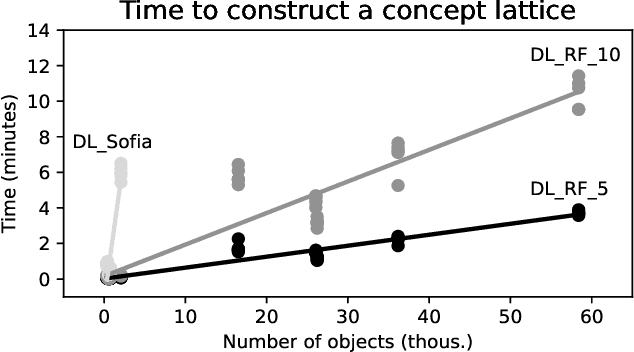
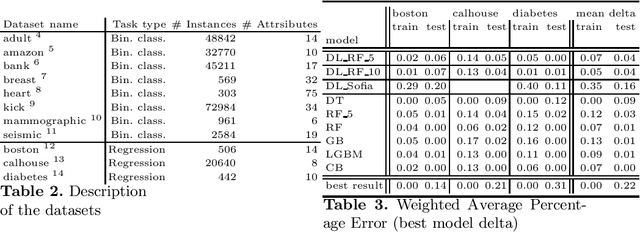
Decision trees and their ensembles are very popular models of supervised machine learning. In this paper we merge the ideas underlying decision trees, their ensembles and FCA by proposing a new supervised machine learning model which can be constructed in polynomial time and is applicable for both classification and regression problems. Specifically, we first propose a polynomial-time algorithm for constructing a part of the concept lattice that is based on a decision tree. Second, we describe a prediction scheme based on a concept lattice for solving both classification and regression tasks with prediction quality comparable to that of state-of-the-art models.
Mint: MDL-based approach for Mining INTeresting Numerical Pattern Sets
Nov 30, 2020



Pattern mining is well established in data mining research, especially for mining binary datasets. Surprisingly, there is much less work about numerical pattern mining and this research area remains under-explored. In this paper, we propose Mint, an efficient MDL-based algorithm for mining numerical datasets. The MDL principle is a robust and reliable framework widely used in pattern mining, and as well in subgroup discovery. In Mint we reuse MDL for discovering useful patterns and returning a set of non-redundant overlapping patterns with well-defined boundaries and covering meaningful groups of objects. Mint is not alone in the category of numerical pattern miners based on MDL. In the experiments presented in the paper we show that Mint outperforms competitors among which Slim and RealKrimp.
Discovery data topology with the closure structure. Theoretical and practical aspects
Oct 06, 2020
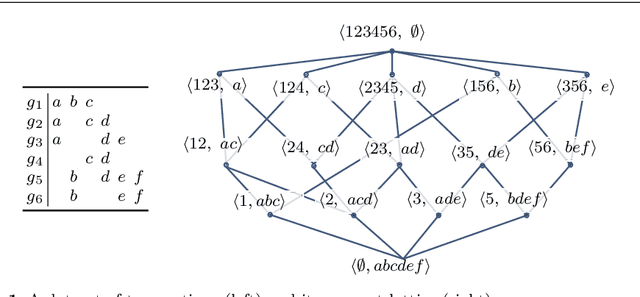


In this paper, we are revisiting pattern mining and especially itemset mining, which allows one to analyze binary datasets in searching for interesting and meaningful association rules and respective itemsets in an unsupervised way. While a summarization of a dataset based on a set of patterns does not provide a general and satisfying view over a dataset, we introduce a concise representation --the closure structure-- based on closed itemsets and their minimum generators, for capturing the intrinsic content of a dataset. The closure structure allows one to understand the topology of the dataset in the whole and the inherent complexity of the data. We propose a formalization of the closure structure in terms of Formal Concept Analysis, which is well adapted to study this data topology. We present and demonstrate theoretical results, and as well, practical results using the GDPM algorithm. GDPM is rather unique in its functionality as it returns a characterization of the topology of a dataset in terms of complexity levels, highlighting the diversity and the distribution of the itemsets. Finally, a series of experiments shows how GDPM can be practically used and what can be expected from the output.
Ordered Sets for Data Analysis
Aug 27, 2019This book dwells on mathematical and algorithmic issues of data analysis based on generality order of descriptions and respective precision. To speak of these topics correctly, we have to go some way getting acquainted with the important notions of relation and order theory. On the one hand, data often have a complex structure with natural order on it. On the other hand, many symbolic methods of data analysis and machine learning allow to compare the obtained classifiers w.r.t. their generality, which is also an order relation. Efficient algorithms are very important in data analysis, especially when one deals with big data, so scalability is a real issue. That is why we analyze the computational complexity of algorithms and problems of data analysis. We start from the basic definitions and facts of algorithmic complexity theory and analyze the complexity of various tools of data analysis we consider. The tools and methods of data analysis, like computing taxonomies, groups of similar objects (concepts and n-clusters), dependencies in data, classification, etc., are illustrated with applications in particular subject domains, from chemoinformatics to text mining and natural language processing.
On interestingness measures of formal concepts
Apr 19, 2017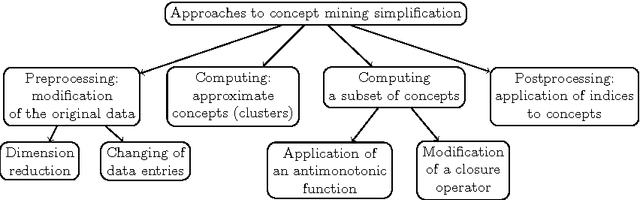

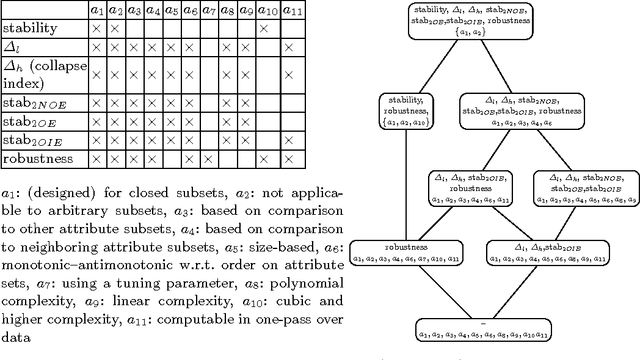
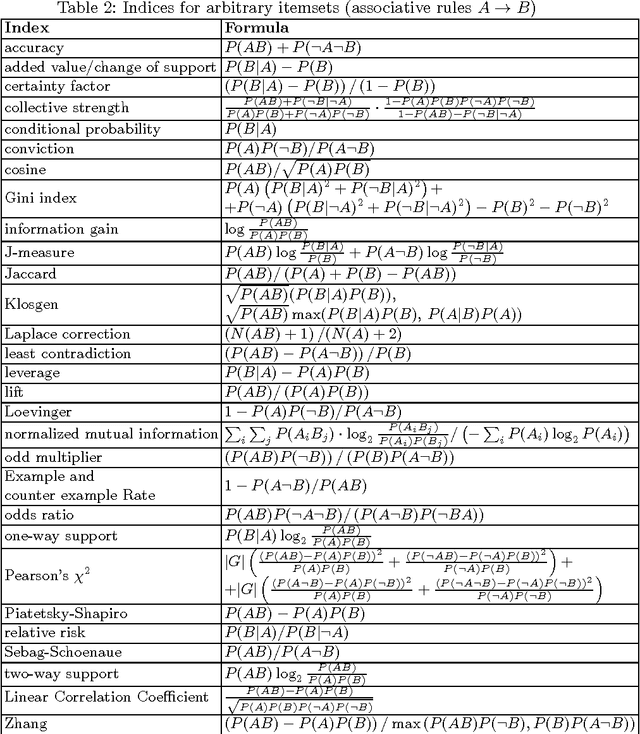
Formal concepts and closed itemsets proved to be of big importance for knowledge discovery, both as a tool for concise representation of association rules and a tool for clustering and constructing domain taxonomies and ontologies. Exponential explosion makes it difficult to consider the whole concept lattice arising from data, one needs to select most useful and interesting concepts. In this paper interestingness measures of concepts are considered and compared with respect to various aspects, such as efficiency of computation and applicability to noisy data and performing ranking correlation.
Mining Best Closed Itemsets for Projection-antimonotonic Constraints in Polynomial Time
Mar 28, 2017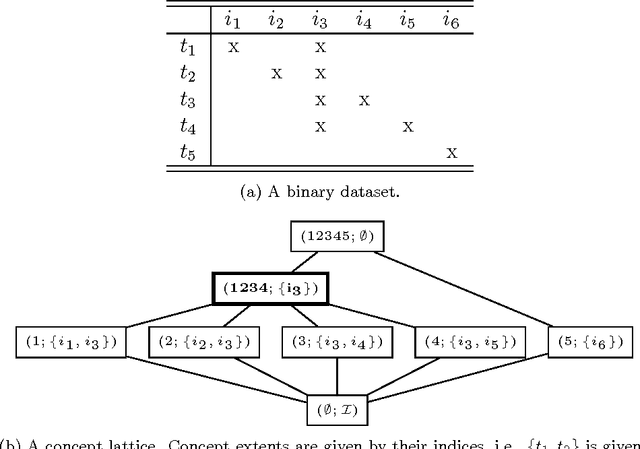
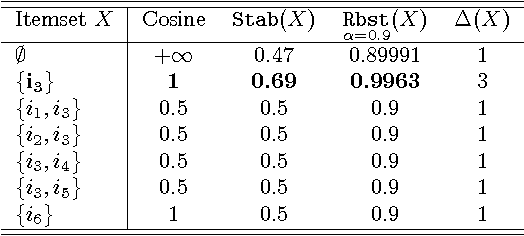
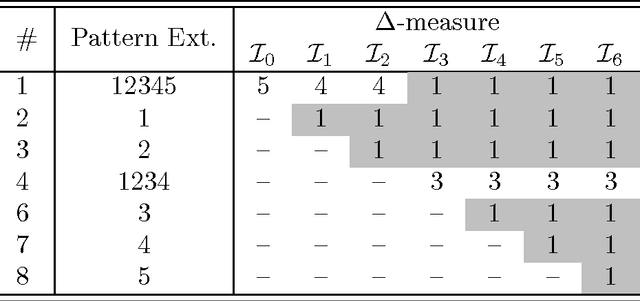
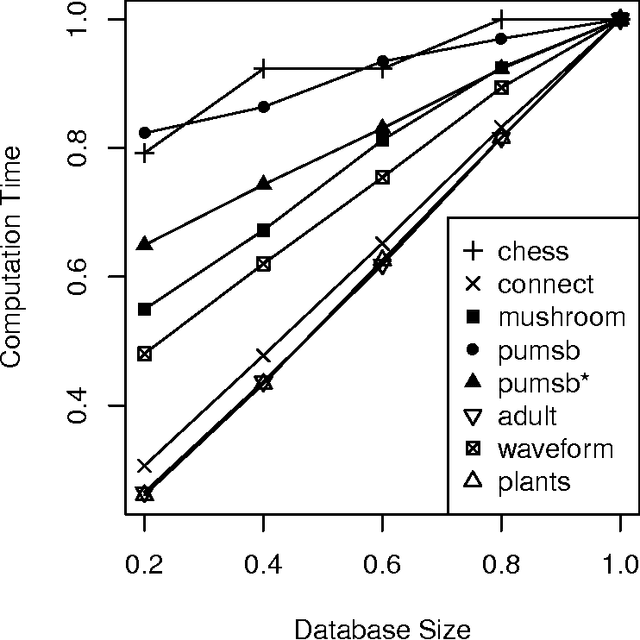
The exponential explosion of the set of patterns is one of the main challenges in pattern mining. This challenge is approached by introducing a constraint for pattern selection. One of the first constraints proposed in pattern mining is support (frequency) of a pattern in a dataset. Frequency is an anti-monotonic function, i.e., given an infrequent pattern, all its superpatterns are not frequent. However, many other constraints for pattern selection are neither monotonic nor anti-monotonic, which makes it difficult to generate patterns satisfying these constraints. In order to deal with nonmonotonic constraints we introduce the notion of "projection antimonotonicity" and SOFIA algorithm that allow generating best patterns for a class of nonmonotonic constraints. Cosine interest, robustness, stability of closed itemsets, and the associated delta-measure are among these constraints. SOFIA starts from light descriptions of transactions in dataset (a small set of items in the case of itemset description) and then iteratively adds more information to these descriptions (more items with indication of tidsets they describe).
Concept Stability for Constructing Taxonomies of Web-site Users
Nov 24, 2016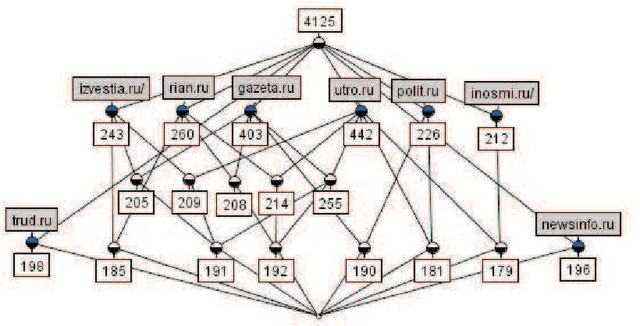
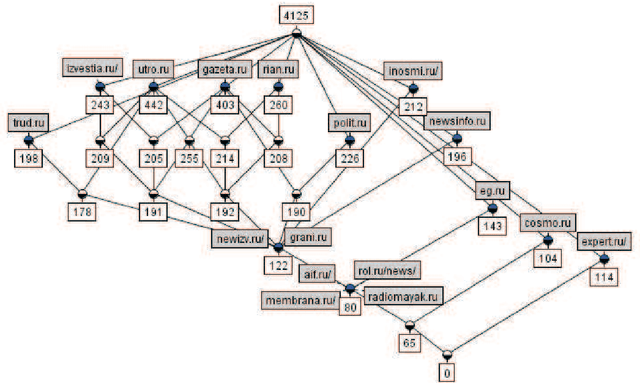
Owners of a web-site are often interested in analysis of groups of users of their site. Information on these groups can help optimizing the structure and contents of the site. In this paper we use an approach based on formal concepts for constructing taxonomies of user groups. For decreasing the huge amount of concepts that arise in applications, we employ stability index of a concept, which describes how a group given by a concept extent differs from other such groups. We analyze resulting taxonomies of user groups for three target websites.
Fast Generation of Best Interval Patterns for Nonmonotonic Constraints
Jun 16, 2015

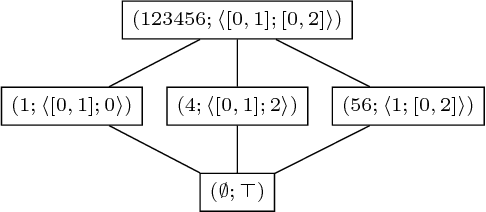
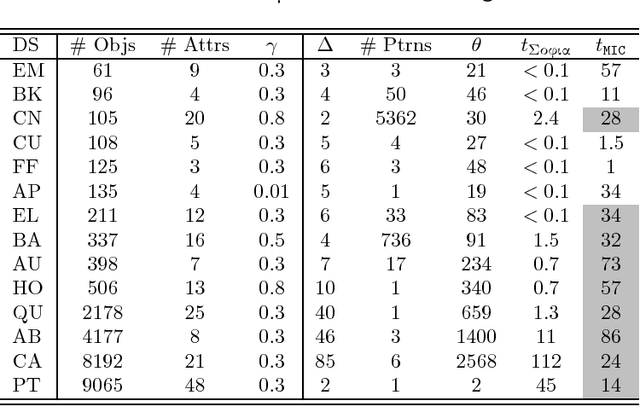
In pattern mining, the main challenge is the exponential explosion of the set of patterns. Typically, to solve this problem, a constraint for pattern selection is introduced. One of the first constraints proposed in pattern mining is support (frequency) of a pattern in a dataset. Frequency is an anti-monotonic function, i.e., given an infrequent pattern, all its superpatterns are not frequent. However, many other constraints for pattern selection are not (anti-)monotonic, which makes it difficult to generate patterns satisfying these constraints. In this paper we introduce the notion of projection-antimonotonicity and $\theta$-$\Sigma\o\phi\iota\alpha$ algorithm that allows efficient generation of the best patterns for some nonmonotonic constraints. In this paper we consider stability and $\Delta$-measure, which are nonmonotonic constraints, and apply them to interval tuple datasets. In the experiments, we compute best interval tuple patterns w.r.t. these measures and show the advantage of our approach over postfiltering approaches. KEYWORDS: Pattern mining, nonmonotonic constraints, interval tuple data