 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship between Brain Hemisphere States and Frequency Bands through Deep Learning Optimization Techniques
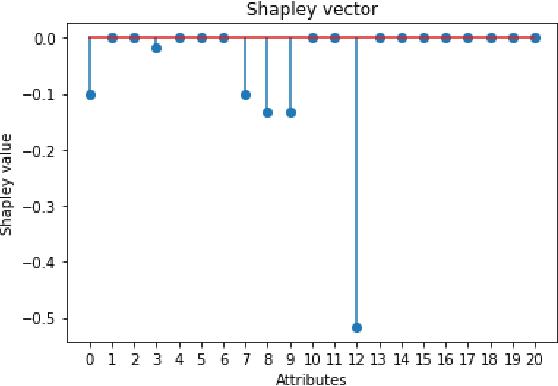
Sep 17, 2025This study investigates classifier performance across EEG frequency bands using various optimizers and evaluates efficient class prediction for the left and right hemispheres. Three neural network architectures - a deep dense network, a shallow three-layer network, and a convolutional neural network (CNN) - are implemented and compared using the TensorFlow and PyTorch frameworks. Results indicate that the Adagrad and RMSprop optimizers consistently perform well across different frequency bands, with Adadelta exhibiting robust performance in cross-model evaluations. Specifically, Adagrad excels in the beta band, while RMSprop achieves superior performance in the gamma band. Conversely, SGD and FTRL exhibit inconsistent performance. Among the models, the CNN demonstrates the second highest accuracy, particularly in capturing spatial features of EEG data. The deep dense network shows competitive performance in learning complex patterns, whereas the shallow three-layer network, sometimes being less accurate, provides computational efficiency. SHAP (Shapley Additive Explanations) plots are employed to identify efficient class prediction, revealing nuanced contributions of EEG frequency bands to model accuracy. Overall, the study highlights the importance of optimizer selection, model architecture, and EEG frequency band analysis in enhancing classifier performance and understanding feature importance in neuroimaging-based classification tasks.
Transformer-based classification of user queries for medical consultancy with respect to expert specialization
Oct 02, 2023
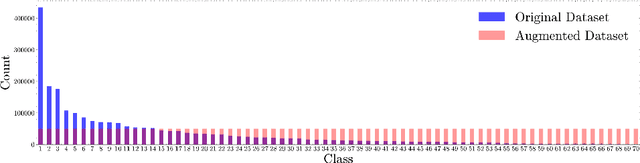
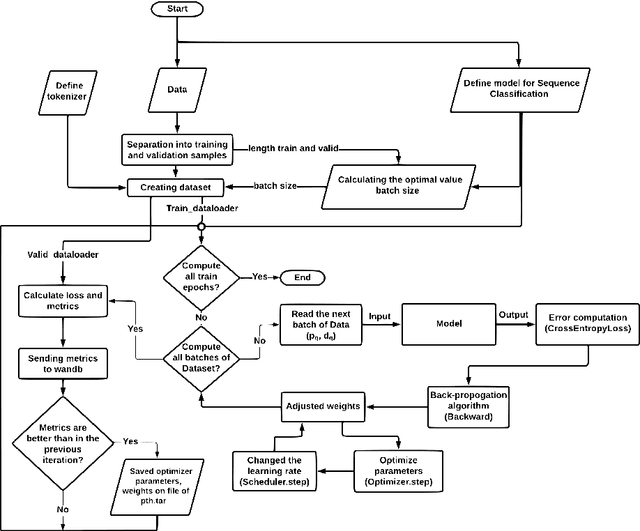
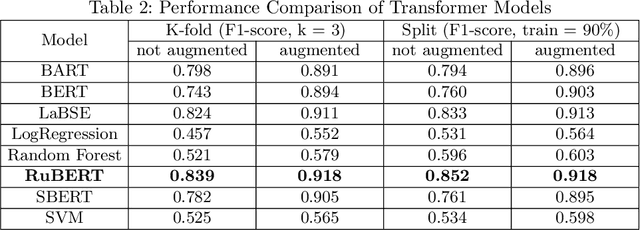
The need for skilled medical support is growing in the era of digital healthcare. This research presents an innovative strategy, utilizing the RuBERT model, for categorizing user inquiries in the field of medical consultation with a focus on expert specialization. By harnessing the capabilities of transformers, we fine-tuned the pre-trained RuBERT model on a varied dataset, which facilitates precise correspondence between queries and particular medical specialisms. Using a comprehensive dataset, we have demonstrated our approach's superior performance with an F1-score of over 92%, calculated through both cross-validation and the traditional split of test and train datasets. Our approach has shown excellent generalization across medical domains such as cardiology, neurology and dermatology. This methodology provides practical benefits by directing users to appropriate specialists for prompt and targeted medical advice. It also enhances healthcare system efficiency, reduces practitioner burden, and improves patient care quality. In summary, our suggested strategy facilitates the attainment of specific medical knowledge, offering prompt and precise advice within the digital healthcare field.
On Interpretability and Similarity in Concept-Based Machine Learning
Feb 25, 2021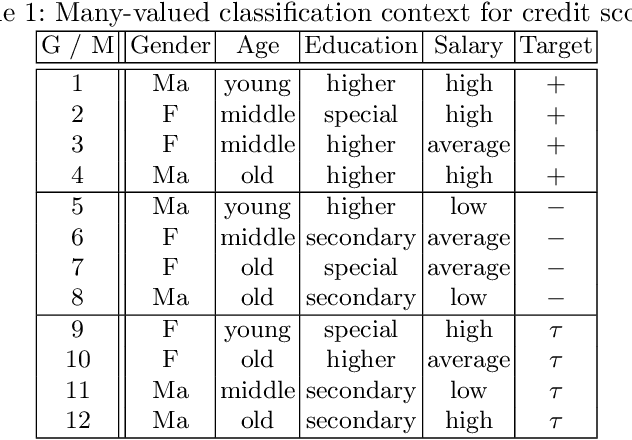
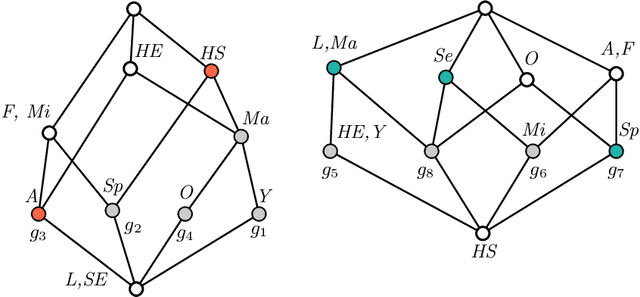
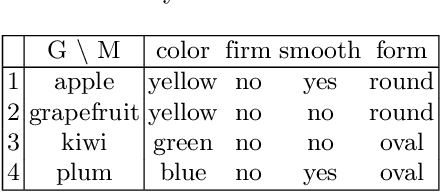
Machine Learning (ML) provides important techniques for classification and predictions. Most of these are black-box models for users and do not provide decision-makers with an explanation. For the sake of transparency or more validity of decisions, the need to develop explainable/interpretable ML-methods is gaining more and more importance. Certain questions need to be addressed: How does an ML procedure derive the class for a particular entity? Why does a particular clustering emerge from a particular unsupervised ML procedure? What can we do if the number of attributes is very large? What are the possible reasons for the mistakes for concrete cases and models? For binary attributes, Formal Concept Analysis (FCA) offers techniques in terms of intents of formal concepts, and thus provides plausible reasons for model prediction. However, from the interpretable machine learning viewpoint, we still need to provide decision-makers with the importance of individual attributes to the classification of a particular object, which may facilitate explanations by experts in various domains with high-cost errors like medicine or finance. We discuss how notions from cooperative game theory can be used to assess the contribution of individual attributes in classification and clustering processes in concept-based machine learning. To address the 3rd question, we present some ideas on how to reduce the number of attributes using similarities in large contexts.
Object-Attribute Biclustering for Elimination of Missing Genotypes in Ischemic Stroke Genome-Wide Data
Oct 25, 2020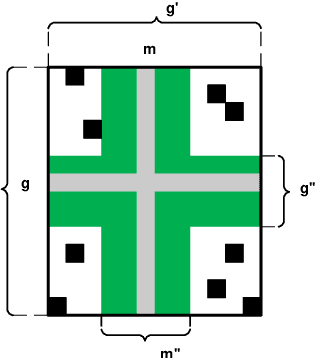



Missing genotypes can affect the efficacy of machine learning approaches to identify the risk genetic variants of common diseases and traits. The problem occurs when genotypic data are collected from different experiments with different DNA microarrays, each being characterised by its pattern of uncalled (missing) genotypes. This can prevent the machine learning classifier from assigning the classes correctly. To tackle this issue, we used well-developed notions of object-attribute biclusters and formal concepts that correspond to dense subrelations in the binary relation $\textit{patients} \times \textit{SNPs}$. The paper contains experimental results on applying a biclustering algorithm to a large real-world dataset collected for studying the genetic bases of ischemic stroke. The algorithm could identify large dense biclusters in the genotypic matrix for further processing, which in return significantly improved the quality of machine learning classifiers. The proposed algorithm was also able to generate biclusters for the whole dataset without size constraints in comparison to the In-Close4 algorithm for generation of formal concepts.
* Accepted to AIST 2020
Triclustering in Big Data Setting
Oct 24, 2020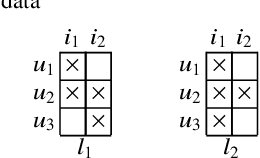
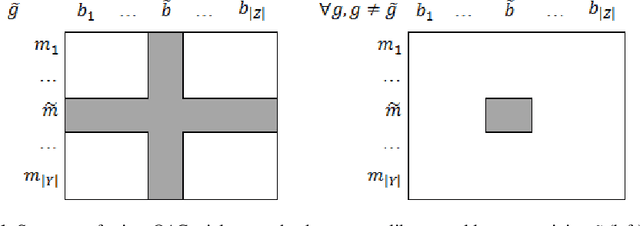
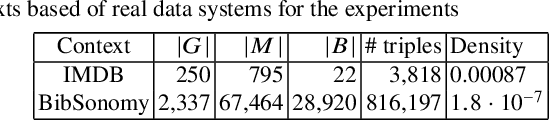
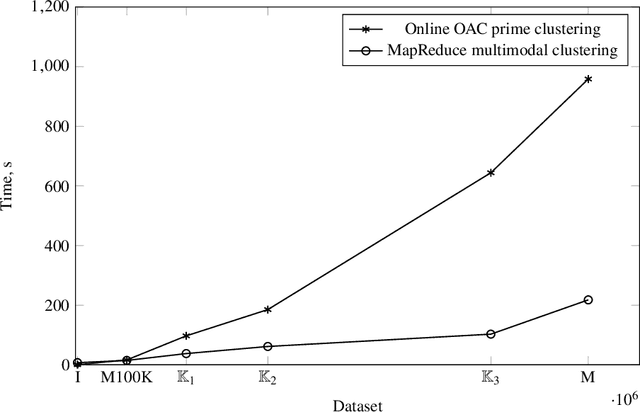
In this paper, we describe versions of triclustering algorithms adapted for efficient calculations in distributed environments with MapReduce model or parallelisation mechanism provided by modern programming languages. OAC-family of triclustering algorithms shows good parallelisation capabilities due to the independent processing of triples of a triadic formal context. We provide the time and space complexity of the algorithms and justify their relevance. We also compare performance gain from using a distributed system and scalability.
* The paper contains an extended version of the prior work presented at the workshop on FCA in the Big Data Era held on June 25, 2019 at Frankfurt University of Applied Sciences, Frankfurt, Germany
DaNetQA: a yes/no Question Answering Dataset for the Russian Language
Oct 15, 2020

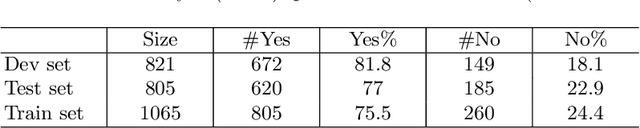

DaNetQA, a new question-answering corpus, follows (Clark et. al, 2019) design: it comprises natural yes/no questions. Each question is paired with a paragraph from Wikipedia and an answer, derived from the paragraph. The task is to take both the question and a paragraph as input and come up with a yes/no answer, i.e. to produce a binary output. In this paper, we present a reproducible approach to DaNetQA creation and investigate transfer learning methods for task and language transferring. For task transferring we leverage three similar sentence modelling tasks: 1) a corpus of paraphrases, Paraphraser, 2) an NLI task, for which we use the Russian part of XNLI, 3) another question answering task, SberQUAD. For language transferring we use English to Russian translation together with multilingual language fine-tuning.
Mixed Integer Programming for Searching Maximum Quasi-Bicliques
Feb 23, 2020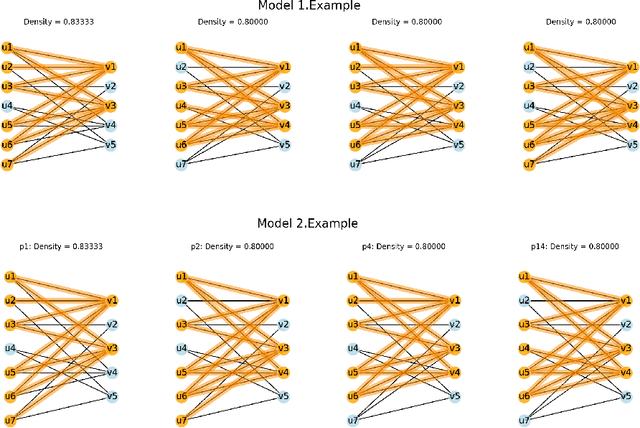
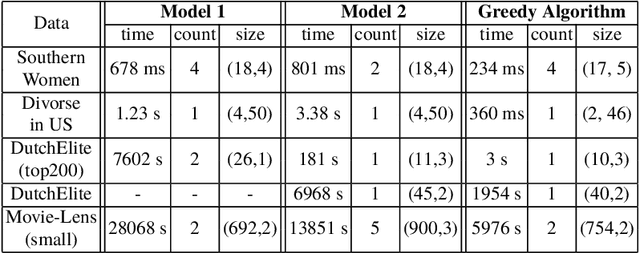
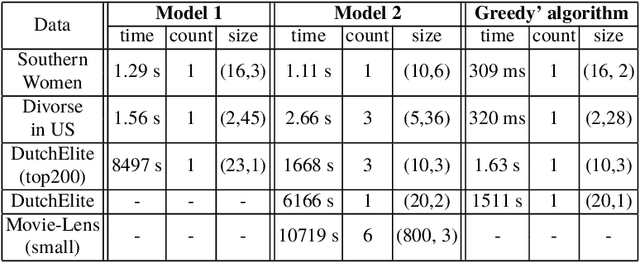
This paper is related to the problem of finding the maximal quasi-bicliques in a bipartite graph (bigraph). A quasi-biclique in the bigraph is its "almost" complete subgraph. The relaxation of completeness can be understood variously; here, we assume that the subgraph is a $\gamma$-quasi-biclique if it lacks a certain number of edges to form a biclique such that its density is at least $\gamma \in (0,1]$. For a bigraph and fixed $\gamma$, the problem of searching for the maximal quasi-biclique consists of finding a subset of vertices of the bigraph such that the induced subgraph is a quasi-biclique and its size is maximal for a given graph. Several models based on Mixed Integer Programming (MIP) to search for a quasi-biclique are proposed and tested for working efficiency. An alternative model inspired by biclustering is formulated and tested; this model simultaneously maximizes both the size of the quasi-biclique and its density, using the least-square criterion similar to the one exploited by triclustering \textsc{TriBox}.
* This paper draft is stored here for self-archiving purposes
Compression of Recurrent Neural Networks for Efficient Language Modeling
Feb 06, 2019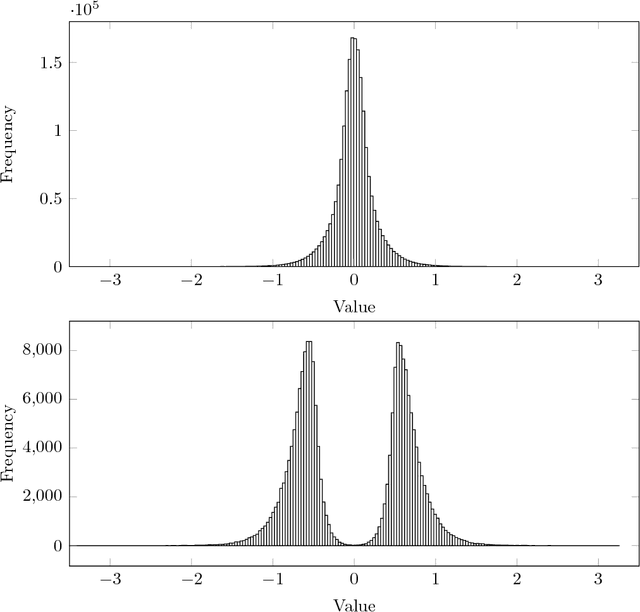
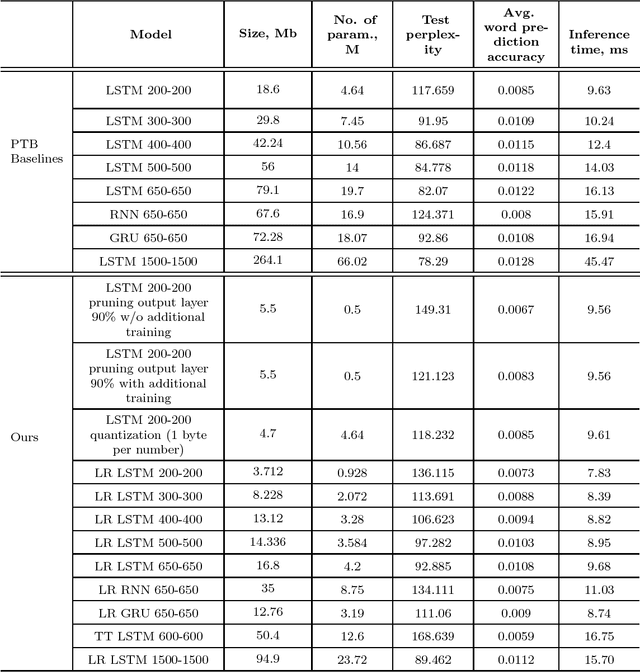
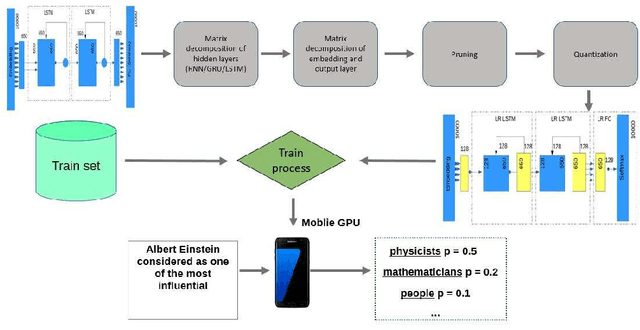
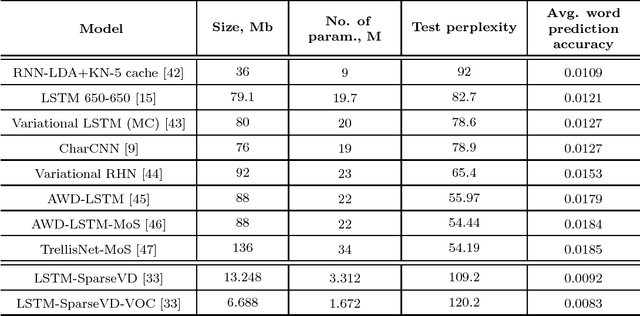
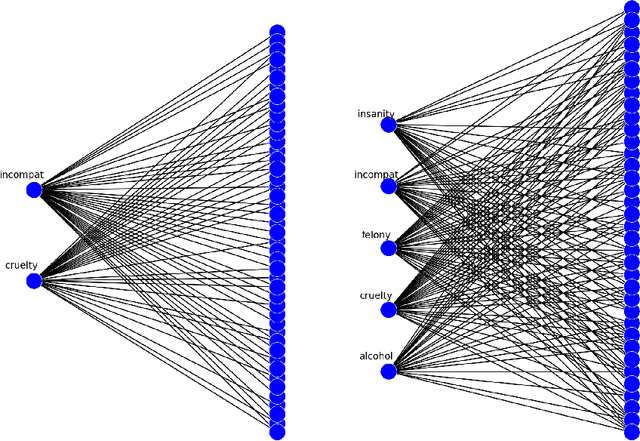
Recurrent neural networks have proved to be an effective method for statistical language modeling. However, in practice their memory and run-time complexity are usually too large to be implemented in real-time offline mobile applications. In this paper we consider several compression techniques for recurrent neural networks including Long-Short Term Memory models. We make particular attention to the high-dimensional output problem caused by the very large vocabulary size. We focus on effective compression methods in the context of their exploitation on devices: pruning, quantization, and matrix decomposition approaches (low-rank factorization and tensor train decomposition, in particular). For each model we investigate the trade-off between its size, suitability for fast inference and perplexity. We propose a general pipeline for applying the most suitable methods to compress recurrent neural networks for language modeling. It has been shown in the experimental study with the Penn Treebank (PTB) dataset that the most efficient results in terms of speed and compression-perplexity balance are obtained by matrix decomposition techniques.
Neural Networks Compression for Language Modeling
Aug 20, 2017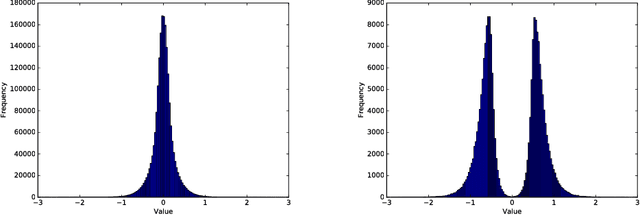
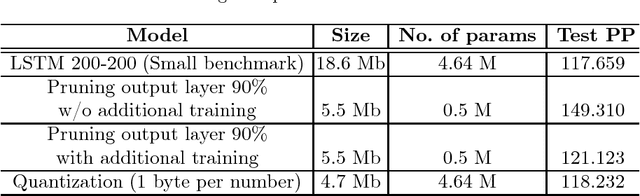
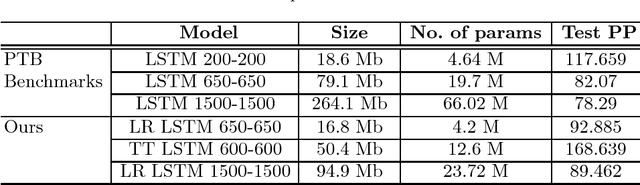
In this paper, we consider several compression techniques for the language modeling problem based on recurrent neural networks (RNNs). It is known that conventional RNNs, e.g, LSTM-based networks in language modeling, are characterized with either high space complexity or substantial inference time. This problem is especially crucial for mobile applications, in which the constant interaction with the remote server is inappropriate. By using the Penn Treebank (PTB) dataset we compare pruning, quantization, low-rank factorization, tensor train decomposition for LSTM networks in terms of model size and suitability for fast inference.
Introduction to Formal Concept Analysis and Its Applications in Information Retrieval and Related Fields
Mar 08, 2017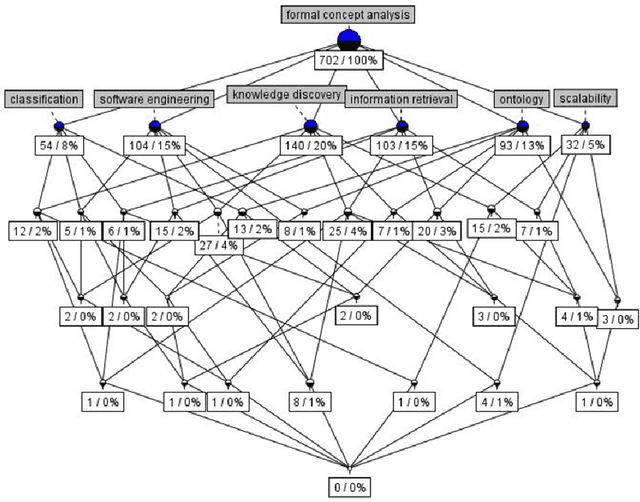

This paper is a tutorial on Formal Concept Analysis (FCA) and its applications. FCA is an applied branch of Lattice Theory, a mathematical discipline which enables formalisation of concepts as basic units of human thinking and analysing data in the object-attribute form. Originated in early 80s, during the last three decades, it became a popular human-centred tool for knowledge representation and data analysis with numerous applications. Since the tutorial was specially prepared for RuSSIR 2014, the covered FCA topics include Information Retrieval with a focus on visualisation aspects, Machine Learning, Data Mining and Knowledge Discovery, Text Mining and several others.