 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parallel Algorithm for Decomposing Hard CircuitSAT Instances
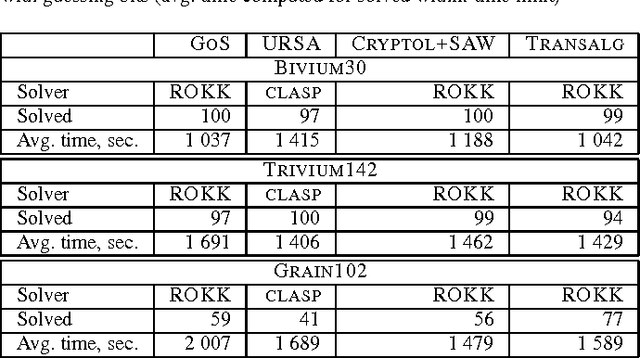
Feb 19, 2026We propose a novel parallel algorithm for decomposing hard CircuitSAT instances. The technique employs specialized constraints to partition an original SAT instance into a family of weakened formulas. Our approach is implemented as a parameterized parallel algorithm, where adjusting the parameters allows efficient identification of high-quality decompositions, guided by hardness estimations computed in parallel. We demonstrate the algorithm's practical efficacy on challenging CircuitSAT instances, including those encoding Logical Equivalence Checking of Boolean circuits and preimage attacks on cryptographic hash functions.
Decomposing Hard SAT Instances with Metaheuristic Optimization
Dec 16, 2023In the article, within the framework of the Boolean Satisfiability problem (SAT), the problem of estimating the hardness of specific Boolean formulas w.r.t. a specific complete SAT solving algorithm is considered. Based on the well-known Strong Backdoor Set (SBS) concept, we introduce the notion of decomposition hardness (d-hardness). If $B$ is an arbitrary subset of the set of variables occurring in a SAT formula $C$, and $A$ is an arbitrary complete SAT solver , then the d-hardness expresses an estimate of the hardness of $C$ w.r.t. $A$ and $B$. We show that the d-hardness of $C$ w.r.t. a particular $B$ can be expressed in terms of the expected value of a special random variable associated with $A$, $B$, and $C$. For its computational evaluation, algorithms based on the Monte Carlo method can be used. The problem of finding $B$ with the minimum value of d-hardness is formulated as an optimization problem for a pseudo-Boolean function whose values are calculated as a result of a probabilistic experiment. To minimize this function, we use evolutionary algorithms. In the experimental part, we demonstrate the applicability of the concept of d-hardness and the methods of its estimation to solving hard unsatisfiable SAT instances.
Estimating the hardness of SAT encodings for Logical Equivalence Checking of Boolean circuits
Oct 04, 2022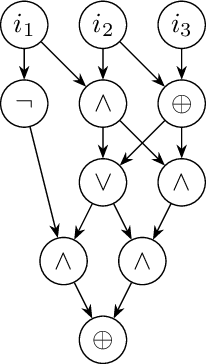
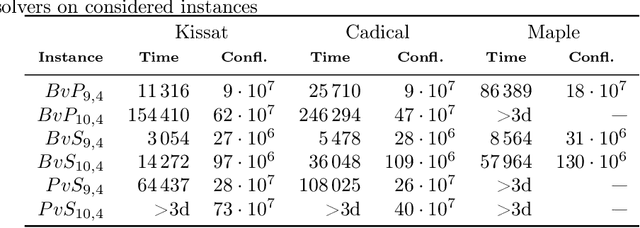
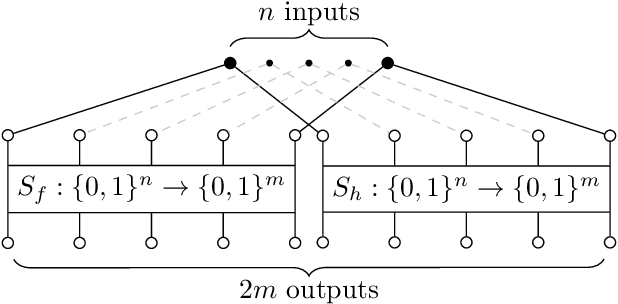

In this paper we investigate how to estimate the hardness of Boolean satisfiability (SAT) encodings for the Logical Equivalence Checking problem (LEC). Meaningful estimates of hardness are important in cases when a conventional SAT solver cannot solve a SAT instance in a reasonable time. We show that the hardness of SAT encodings for LEC instances can be estimated \textit{w.r.t.} some SAT partitioning. We also demonstrate the dependence of the accuracy of the resulting estimates on the probabilistic characteristics of a specially defined random variable associated with the considered partitioning. The paper proposes several methods for constructing partitionings, which, when used in practice, allow one to estimate the hardness of SAT encodings for LEC with good accuracy. In the experimental part we propose a class of scalable LEC tests that give extremely complex instances with a relatively small input size $n$ of the considered circuits. For example, for $n = 40$, none of the state-of-the-art SAT solvers can cope with the considered tests in a reasonable time. However, these tests can be solved in parallel using the proposed partitioning methods.
Who will stay? Using Deep Learning to predict engagement of citizen scientists
Apr 28, 2022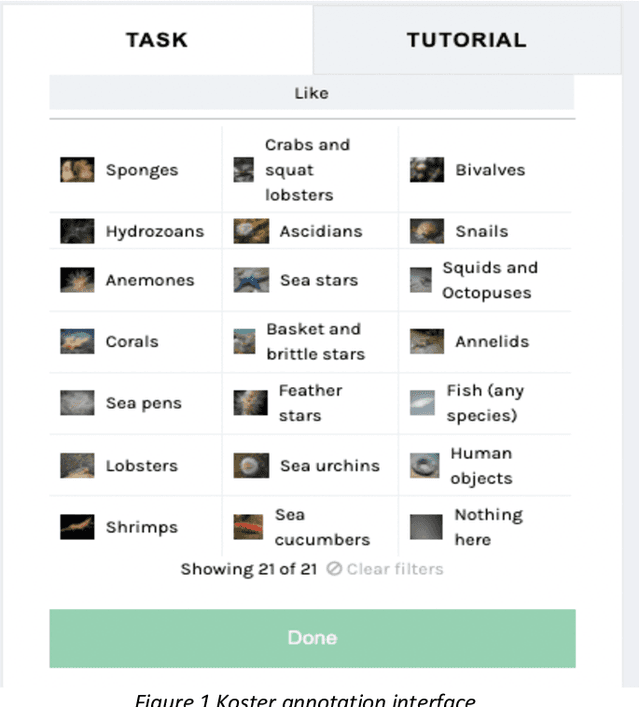
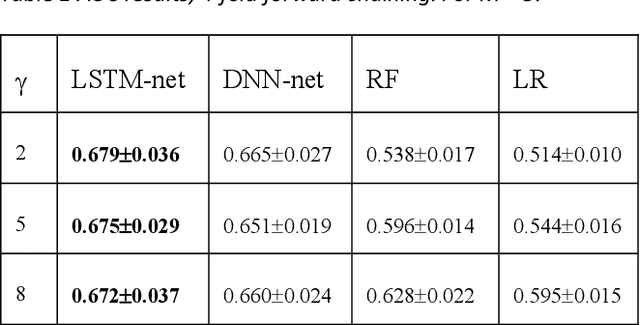
Citizen science and machine learning should be considered for monitoring the coastal and ocean environment due to the scale of threats posed by climate change and the limited resources to fill knowledge gaps. Using data from the annotation activity of citizen scientists in a Swedish marine project, we constructed Deep Neural Network models to predict forthcoming engagement. We tested the models to identify patterns in annotation engagement. Based on the results, it is possible to predict whether an annotator will remain active in future sessions. Depending on the goals of individual citizen science projects, it may also be necessary to identify either those volunteers who will leave or those who will continue annotating. This can be predicted by varying the threshold for the prediction. The engagement metrics used to construct the models are based on time and activity and can be used to infer latent characteristics of volunteers and predict their task interest based on their activity patterns. They can estimate if volunteers can accomplish a given number of tasks in a certain amount of time, identify early on who is likely to become a top contributor or identify who is likely to quit and provide them with targeted interventions. The novelty of our predictive models lies in the use of Deep Neural Networks and the sequence of volunteer annotations. A limitation of our models is that they do not use embeddings constructed from user profiles as input data, as many recommender systems do. We expect that including user profiles would improve prediction performance.
Multidimensional Assignment Problem for multipartite entity resolution
Dec 06, 2021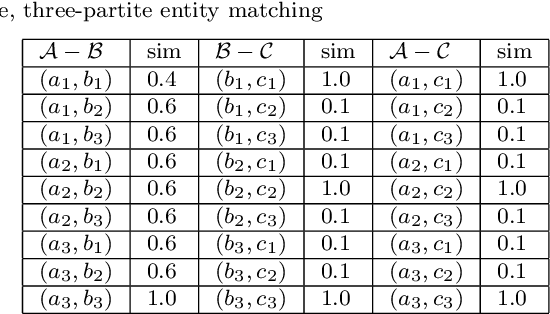
Multipartite entity resolution aims at integrating records from multiple datasets into one entity. We derive a mathematical formulation for a general class of record linkage problems in multipartite entity resolution across many datasets as a combinatorial optimization problem known as the multidimensional assignment problem. As a motivation for our approach, we illustrate the advantage of multipartite entity resolution over sequential bipartite matching. Because the optimization problem is NP-hard, we apply two heuristic procedures, a Greedy algorithm and very large scale neighborhood search, to solve the assignment problem and find the most likely matching of records from multiple datasets into a single entity. We evaluate and compare the performance of these algorithms and their modifications on synthetically generated data. We perform computational experiments to compare performance of recent heuristic, the very large-scale neighborhood search, with a Greedy algorithm, another heuristic for the MAP, as well as with two versions of genetic algorithm, a general metaheuristic. Importantly, we perform experiments to compare two alternative methods of re-starting the search for the former heuristic, specifically a random-sampling multi-start and a deterministic design-based multi-start. We find evidence that design-based multi-start can be more efficient as the size of databases grow large. In addition, we show that very large scale search, especially its multi-start version, outperforms simple Greedy heuristic. Hybridization of Greedy search with very large scale neighborhood search improves the performance. Using multi-start with as few as three additional runs of very large scale search offers some improvement in the performance of the very large scale search procedure. Last, we propose an approach to evaluating complexity of the very large-scale neighborhood search.
Translation of Algorithmic Descriptions of Discrete Functions to SAT with Applications to Cryptanalysis Problems
May 17, 2018

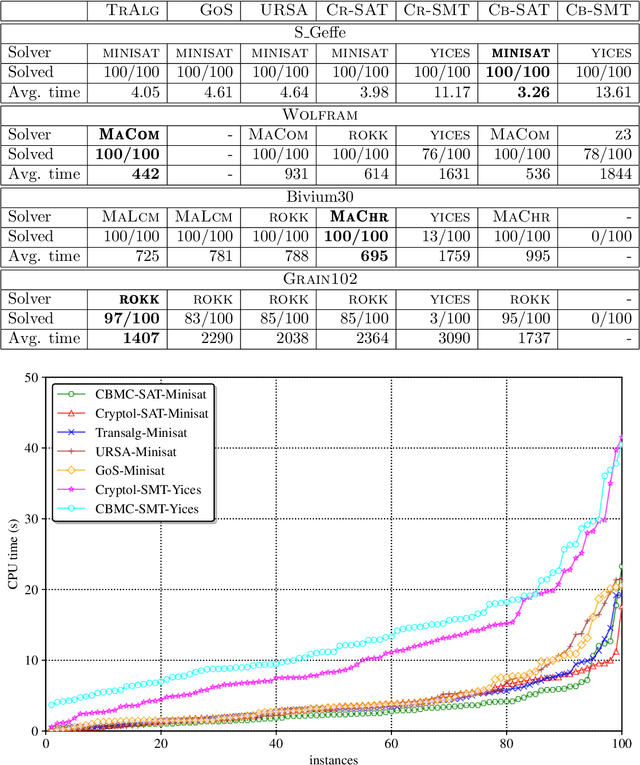
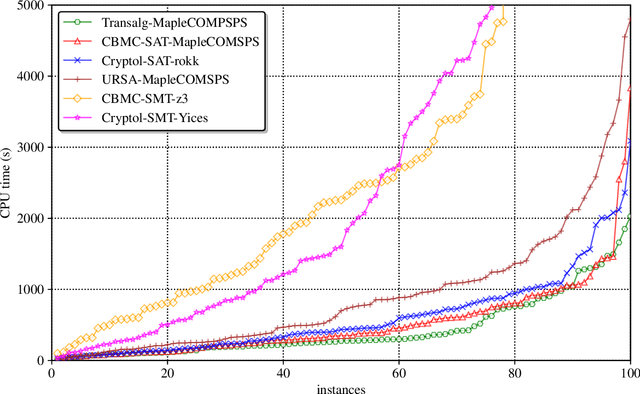
In the present paper we describe the technology for translating algorithmic descriptions of discrete functions to SAT. The proposed methods and algorithms of translation are aimed at application to the problems of SAT-based cryptanalysis. In the theoretical part of the paper we justify the main principles of general reduction to SAT for discrete functions from a class containing the majority of functions employed in cryptography. Based on these principles we describe the Transalg software system, developed with SAT-based cryptanalysis specifics in mind. We show the results of applications of Transalg to construction of a number of attacks on various cryptographic functions. Some of the corresponding attacks are state of the art. In the paper we also present the vast experimental data, obtained using the SAT-solvers that took first places at the SAT-competitions in the recent several years.
On Cryptographic Attacks Using Backdoors for SAT
Mar 13, 2018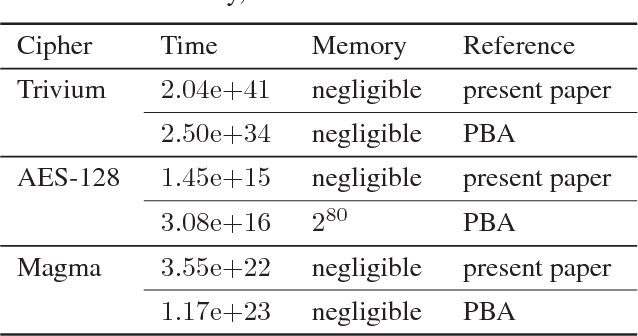
Propositional satisfiability (SAT) is at the nucleus of state-of-the-art approaches to a variety of computationally hard problems, one of which is cryptanalysis. Moreover, a number of practical applications of SAT can only be tackled efficiently by identifying and exploiting a subset of formula's variables called backdoor set (or simply backdoors). This paper proposes a new class of backdoor sets for SAT used in the context of cryptographic attacks, namely guess-and-determine attacks. The idea is to identify the best set of backdoor variables subject to a statistically estimated hardness of the guess-and-determine attack using a SAT solver. Experimental results on weakened variants of the renowned encryption algorithms exhibit advantage of the proposed approach compared to the state of the art in terms of the estimated hardness of the resulting guess-and-determine attacks.
Multimodal Clustering for Community Detection
Feb 27, 2017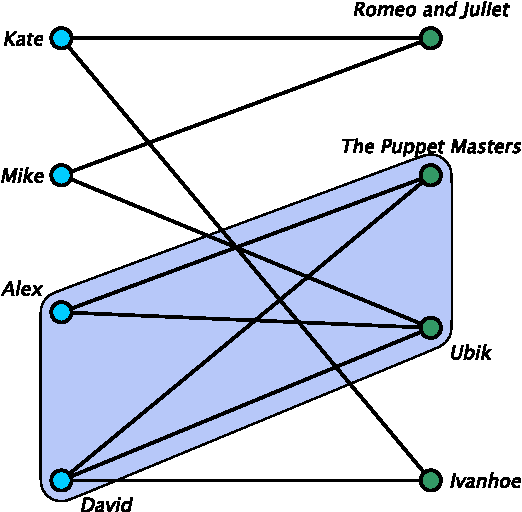
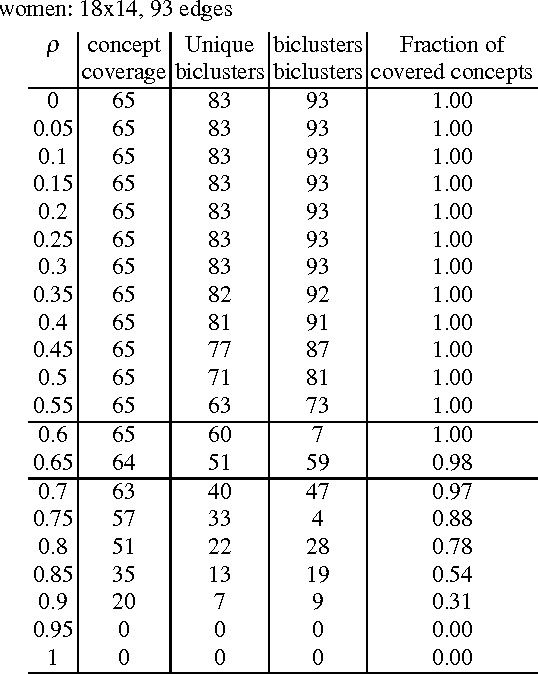
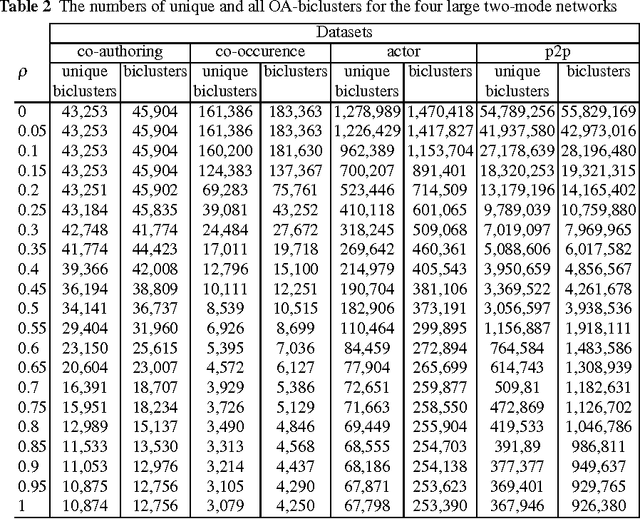
Multimodal clustering is an unsupervised technique for mining interesting patterns in $n$-adic binary relations or $n$-mode networks. Among different types of such generalized patterns one can find biclusters and formal concepts (maximal bicliques) for 2-mode case, triclusters and triconcepts for 3-mode case, closed $n$-sets for $n$-mode case, etc. Object-attribute biclustering (OA-biclustering) for mining large binary datatables (formal contexts or 2-mode networks) arose by the end of the last decade due to intractability of computation problems related to formal concepts; this type of patterns was proposed as a meaningful and scalable approximation of formal concepts. In this paper, our aim is to present recent advance in OA-biclustering and its extensions to mining multi-mode communities in SNA setting. We also discuss connection between clustering coefficients known in SNA community for 1-mode and 2-mode networks and OA-bicluster density, the main quality measure of an OA-bicluster. Our experiments with 2-, 3-, and 4-mode large real-world networks show that this type of patterns is suitable for community detection in multi-mode cases within reasonable time even though the number of corresponding $n$-cliques is still unknown due to computation difficulties. An interpretation of OA-biclusters for 1-mode networks is provided as well.
Encoding Cryptographic Functions to SAT Using Transalg System
Jul 04, 2016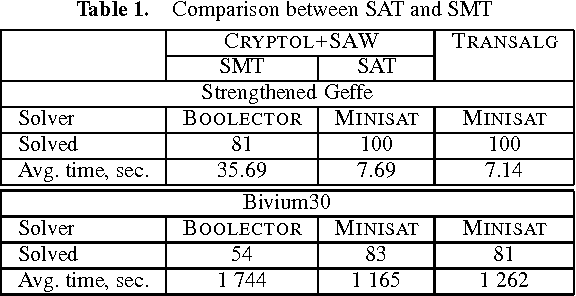
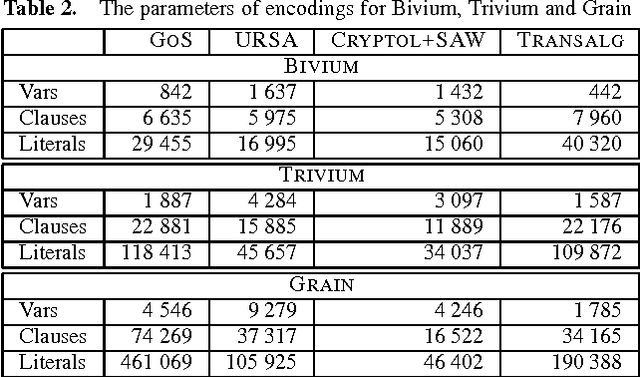

In this paper we propose the technology for constructing propositional encodings of discrete functions. It is aimed at solving inversion problems of considered functions using state-of-the-art SAT solvers. We implemented this technology in the form of the software system called Transalg, and used it to construct SAT encodings for a number of cryptanalysis problems. By applying SAT solvers to these encodings we managed to invert several cryptographic functions. In particular, we used the SAT encodings produced by Transalg to construct the family of two-block MD5 collisions in which the first 10 bytes are zeros. Also we used Transalg encoding for the widely known A5/1 keystream generator to solve several dozen of its cryptanalysis instances in a distributed computing environment. In the paper we compare in detail the functionality of Transalg with that of similar software systems.
Transalg: a Tool for Translating Procedural Descriptions of Discrete Functions to SAT
Oct 29, 2015
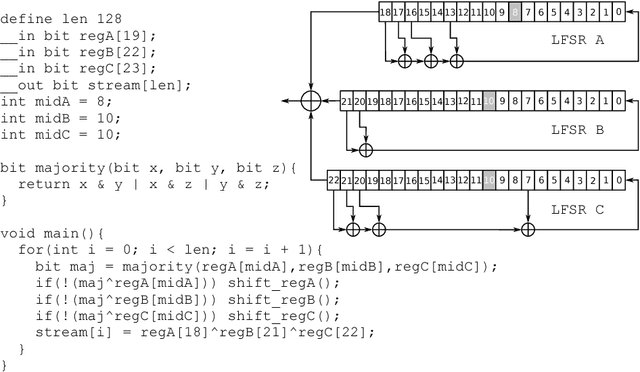
In this paper we present the Transalg system, designed to produce SAT encodings for discrete functions, written as programs in a specific language. Translation of such programs to SAT is based on propositional encoding methods for formal computing models and on the concept of symbolic execution. We used the Transalg system to make SAT encodings for a number of cryptographic functions.