 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based classification of user queries for medical consultancy with respect to expert specialization
Oct 02, 2023
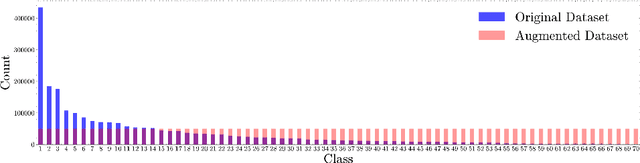
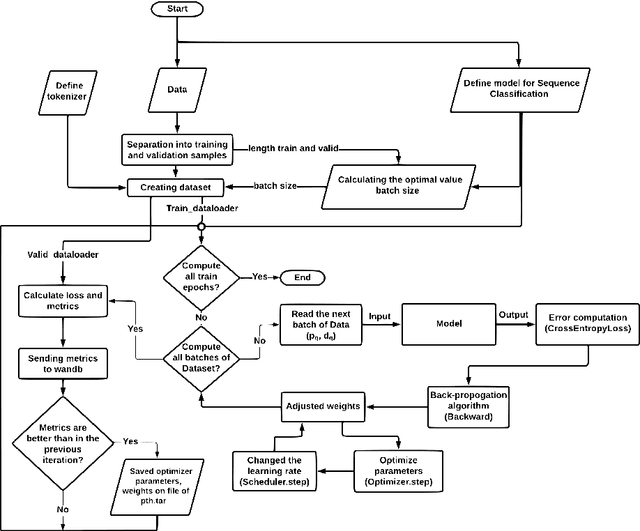
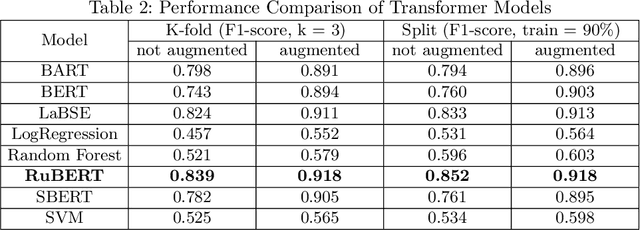
The need for skilled medical support is growing in the era of digital healthcare. This research presents an innovative strategy, utilizing the RuBERT model, for categorizing user inquiries in the field of medical consultation with a focus on expert specialization. By harnessing the capabilities of transformers, we fine-tuned the pre-trained RuBERT model on a varied dataset, which facilitates precise correspondence between queries and particular medical specialisms. Using a comprehensive dataset, we have demonstrated our approach's superior performance with an F1-score of over 92%, calculated through both cross-validation and the traditional split of test and train datasets. Our approach has shown excellent generalization across medical domains such as cardiology, neurology and dermatology. This methodology provides practical benefits by directing users to appropriate specialists for prompt and targeted medical advice. It also enhances healthcare system efficiency, reduces practitioner burden, and improves patient care quality. In summary, our suggested strategy facilitates the attainment of specific medical knowledge, offering prompt and precise advice within the digital healthcare field.
Training Deep SLAM on Single Frames
Dec 11, 2019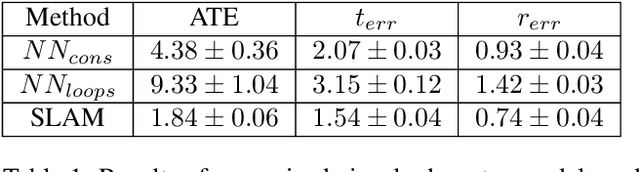
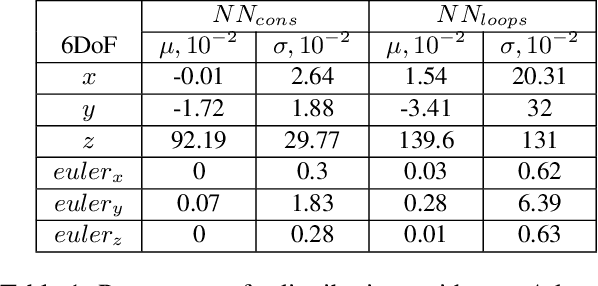
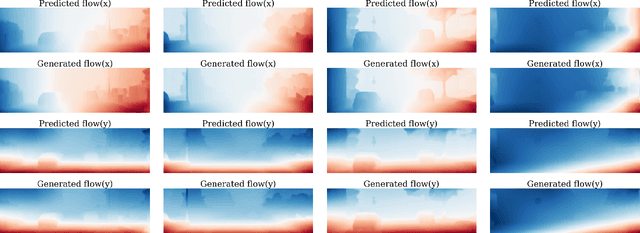

Learning-based visual odometry and SLAM methods demonstrate a steady improvement over past years. However, collecting ground truth poses to train these methods is difficult and expensive. This could be resolved by training in an unsupervised mode, but there is still a large gap between performance of unsupervised and supervised methods. In this work, we focus on generating synthetic data for deep learning-based visual odometry and SLAM methods that take optical flow as an input. We produce training data in a form of optical flow that corresponds to arbitrary camera movement between a real frame and a virtual frame. For synthesizing data we use depth maps either produced by a depth sensor or estimated from stereo pair. We train visual odometry model on synthetic data and do not use ground truth poses hence this model can be considered unsupervised. Also it can be classified as monocular as we do not use depth maps on inference. We also propose a simple way to convert any visual odometry model into a SLAM method based on frame matching and graph optimization. We demonstrate that both the synthetically-trained visual odometry model and the proposed SLAM method build upon this model yields state-of-the-art results among unsupervised methods on KITTI dataset and shows promising results on a challenging EuRoC dataset.
Measuring robustness of Visual SLAM
Oct 10, 2019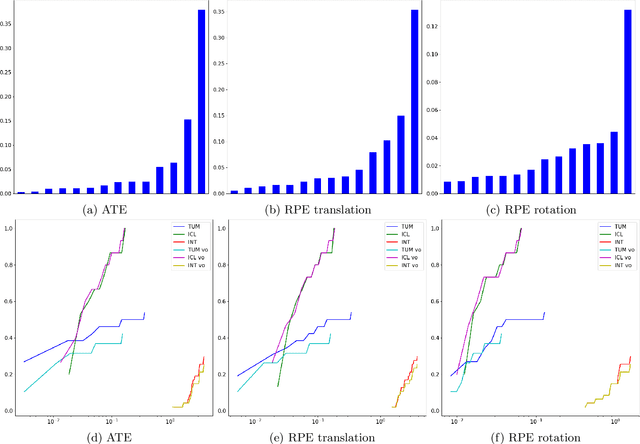
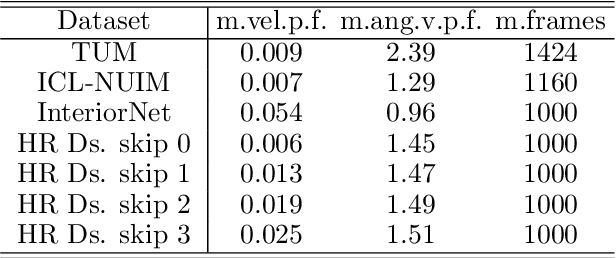
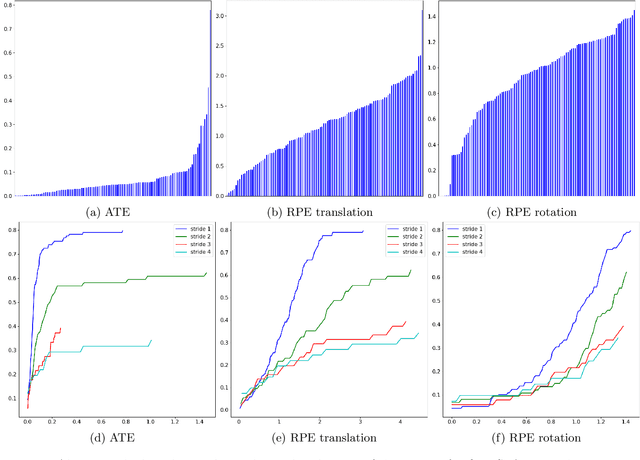
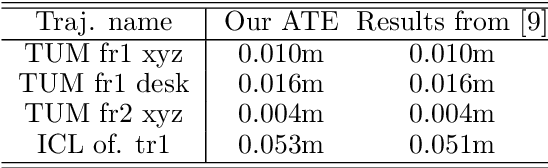
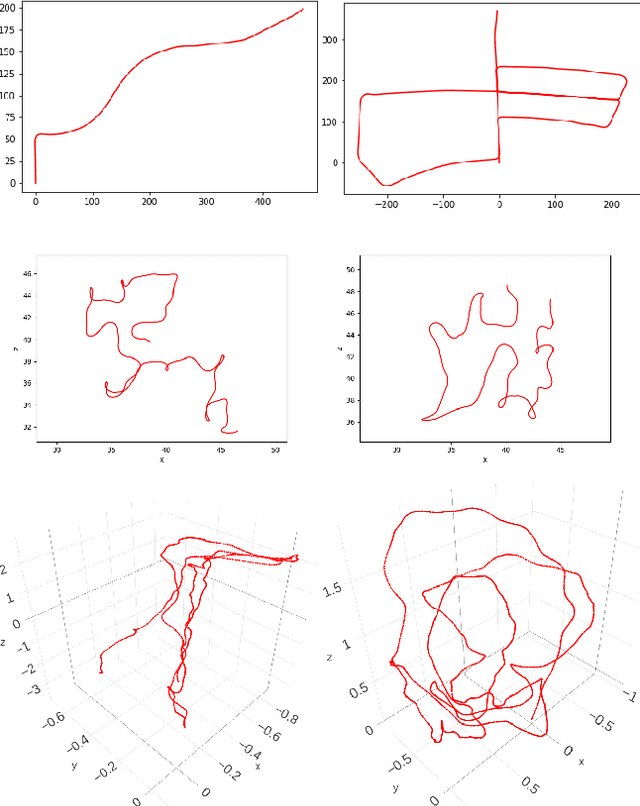
Simultaneous localization and mapping (SLAM) is an essential component of robotic systems. In this work we perform a feasibility study of RGB-D SLAM for the task of indoor robot navigation. Recent visual SLAM methods, e.g. ORBSLAM2 \cite{mur2017orb}, demonstrate really impressive accuracy, but the experiments in the papers are usually conducted on just a few sequences, that makes it difficult to reason about the robustness of the methods. Another problem is that all available RGB-D datasets contain the trajectories with very complex camera motions. In this work we extensively evaluate ORBSLAM2 to better understand the state-of-the-art. First, we conduct experiments on the popular publicly available datasets for RGB-D SLAM across the conventional metrics. We perform statistical analysis of the results and find correlations between the metrics and the attributes of the trajectories. Then, we introduce a new large and diverse HomeRobot dataset where we model the motions of a simple home robot. Our dataset is created using physically-based rendering with realistic lighting and contains the scenes composed by human designers. It includes thousands of sequences, that is two orders of magnitude greater than in previous works. We find that while in many cases the accuracy of SLAM is very good, the robustness is still an issue.
DISCOMAN: Dataset of Indoor SCenes for Odometry, Mapping And Navigation
Sep 26, 2019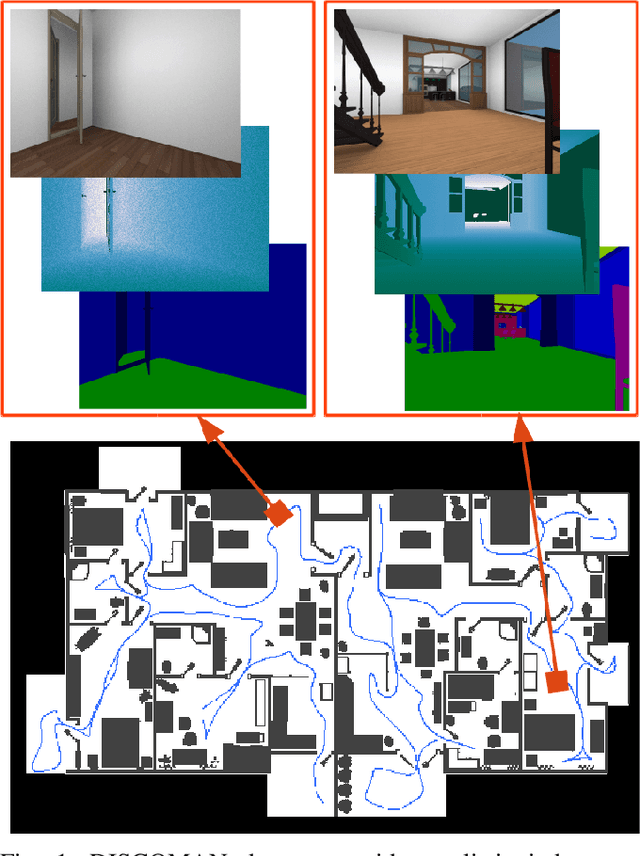
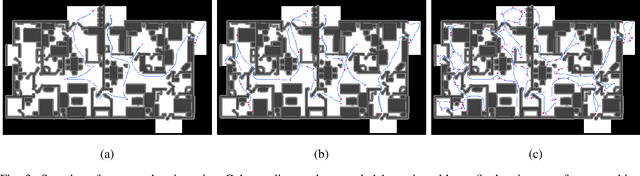

We present a novel dataset for training and benchmarking semantic SLAM methods. The dataset consists of 200 long sequences, each one containing 3000-5000 data frames. We generate the sequences using realistic home layouts. For that we sample trajectories that simulate motions of a simple home robot, and then render the frames along the trajectories. Each data frame contains a) RGB images generated using physically-based rendering, b) simulated depth measurements, c) simulated IMU readings and d) ground truth occupancy grid of a house. Our dataset serves a wider range of purposes compared to existing datasets and is the first large-scale benchmark focused on the mapping component of SLAM. The dataset is split into train/validation/test parts sampled from different sets of virtual houses. We present benchmarking results forboth classical geometry-based and recent learning-based SLAM algorithms, a baseline mapping method, semantic segmentation and panoptic segmentation.