 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep SLAM on Single Frames
Dec 11, 2019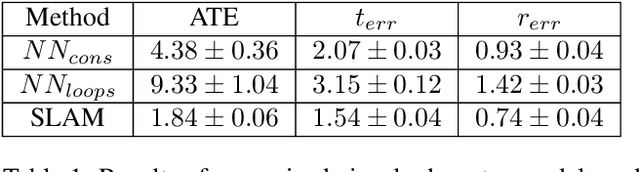
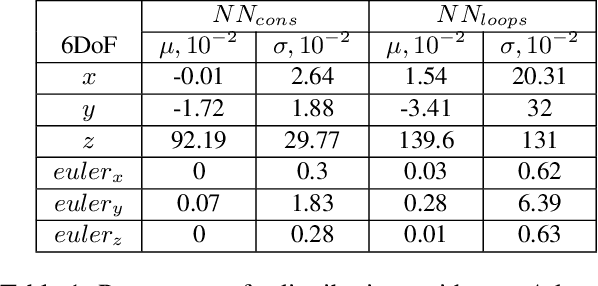

Learning-based visual odometry and SLAM methods demonstrate a steady improvement over past years. However, collecting ground truth poses to train these methods is difficult and expensive. This could be resolved by training in an unsupervised mode, but there is still a large gap between performance of unsupervised and supervised methods. In this work, we focus on generating synthetic data for deep learning-based visual odometry and SLAM methods that take optical flow as an input. We produce training data in a form of optical flow that corresponds to arbitrary camera movement between a real frame and a virtual frame. For synthesizing data we use depth maps either produced by a depth sensor or estimated from stereo pair. We train visual odometry model on synthetic data and do not use ground truth poses hence this model can be considered unsupervised. Also it can be classified as monocular as we do not use depth maps on inference. We also propose a simple way to convert any visual odometry model into a SLAM method based on frame matching and graph optimization. We demonstrate that both the synthetically-trained visual odometry model and the proposed SLAM method build upon this model yields state-of-the-art results among unsupervised methods on KITTI dataset and shows promising results on a challenging EuRoC dataset.
DISCOMAN: Dataset of Indoor SCenes for Odometry, Mapping And Navigation
Sep 26, 2019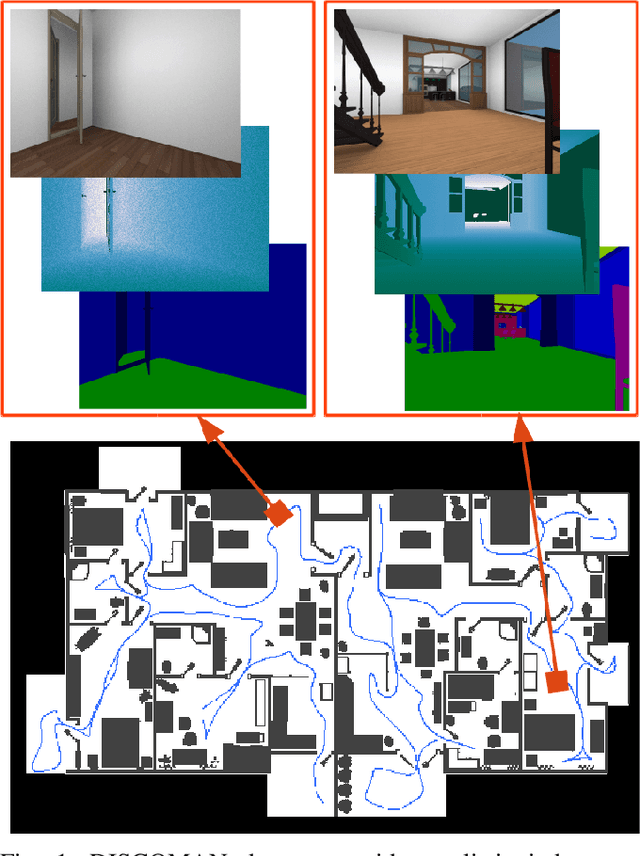
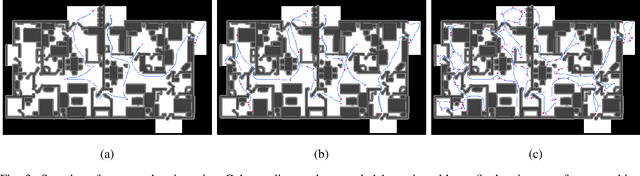

We present a novel dataset for training and benchmarking semantic SLAM methods. The dataset consists of 200 long sequences, each one containing 3000-5000 data frames. We generate the sequences using realistic home layouts. For that we sample trajectories that simulate motions of a simple home robot, and then render the frames along the trajectories. Each data frame contains a) RGB images generated using physically-based rendering, b) simulated depth measurements, c) simulated IMU readings and d) ground truth occupancy grid of a house. Our dataset serves a wider range of purposes compared to existing datasets and is the first large-scale benchmark focused on the mapping component of SLAM. The dataset is split into train/validation/test parts sampled from different sets of virtual houses. We present benchmarking results forboth classical geometry-based and recent learning-based SLAM algorithms, a baseline mapping method, semantic segmentation and panoptic segmentation.
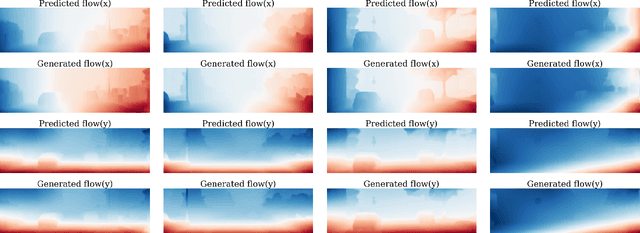
Scene Motion Decomposition for Learnable Visual Odometry
Jul 16, 2019
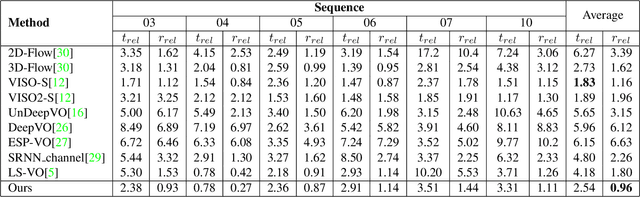
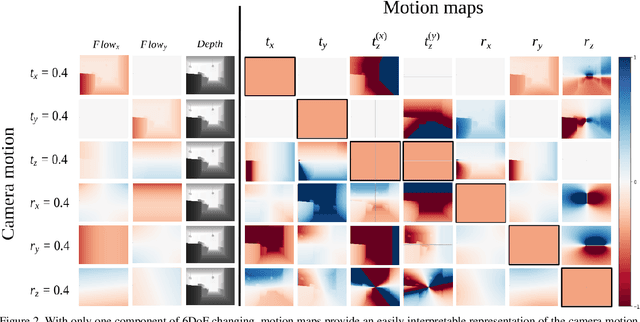

Optical Flow (OF) and depth are commonly used for visual odometry since they provide sufficient information about camera ego-motion in a rigid scene. We reformulate the problem of ego-motion estimation as a problem of motion estimation of a 3D-scene with respect to a static camera. The entire scene motion can be represented as a combination of motions of its visible points. Using OF and depth we estimate a motion of each point in terms of 6DoF and represent results in the form of motion maps, each one addressing single degree of freedom. In this work we provide motion maps as inputs to a deep neural network that predicts 6DoF of scene motion. Through our evaluation on outdoor and indoor datasets we show that utilizing motion maps leads to accuracy improvement in comparison with naive stacking of depth and OF. Another contribution of our work is a novel network architecture that efficiently exploits motion maps and outperforms learnable RGB/RGB-D baselines.