 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning High-Resolution Domain-Specific Representations with a GAN Generator
Jun 18, 2020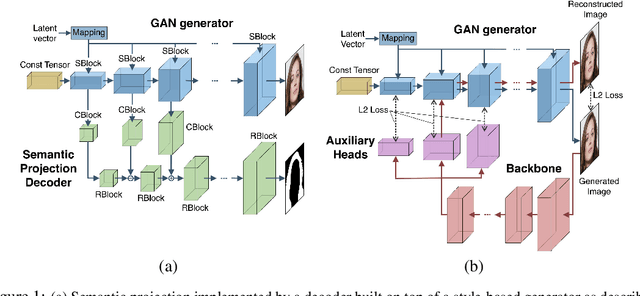


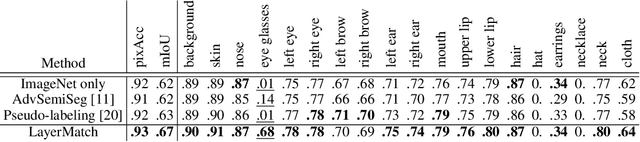
In recent years generative models of visual data have made a great progress, and now they are able to produce images of high quality and diversity. In this work we study representations learnt by a GAN generator. First, we show that these representations can be easily projected onto semantic segmentation map using a lightweight decoder. We find that such semantic projection can be learnt from just a few annotated images. Based on this finding, we propose LayerMatch scheme for approximating the representation of a GAN generator that can be used for unsupervised domain-specific pretraining. We consider the semi-supervised learning scenario when a small amount of labeled data is available along with a large unlabeled dataset from the same domain. We find that the use of LayerMatch-pretrained backbone leads to superior accuracy compared to standard supervised pretraining on ImageNet. Moreover, this simple approach also outperforms recent semi-supervised semantic segmentation methods that use both labeled and unlabeled data during training. Source code for reproducing our experiments will be available at the time of publication.
IterDet: Iterative Scheme for ObjectDetection in Crowded Environments
May 12, 2020
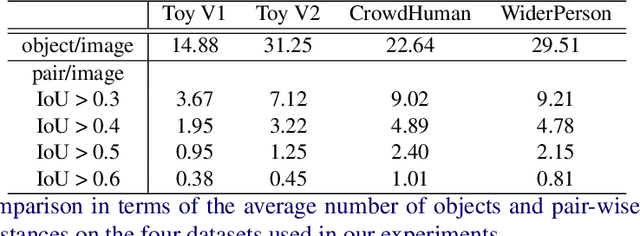
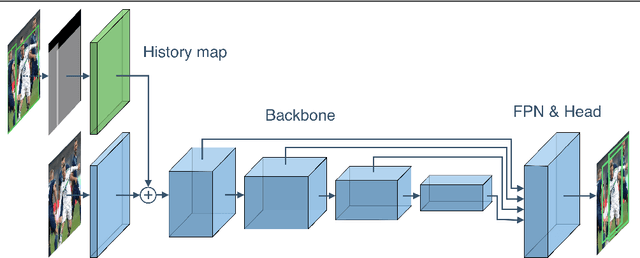
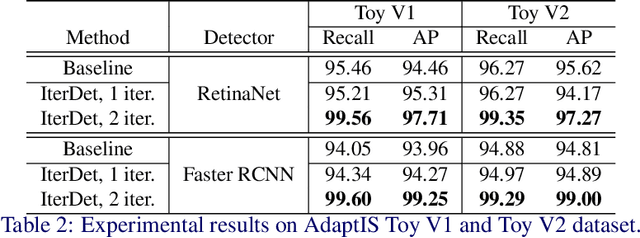
Deep learning-based detectors usually produce a redundant set of object bounding boxes including many duplicate detections of the same object. These boxes are then filtered using non-maximum suppression (NMS) in order to select exactly one bounding box per object of interest. This greedy scheme is simple and provides sufficient accuracy for isolated objects but often fails in crowded environments, since one needs to both preserve boxes for different objects and suppress duplicate detections. In this work we develop an alternative iterative scheme, where a new subset of objects is detected at each iteration. Detected boxes from the previous iterations are passed to the network at the following iterations to ensure that the same object would not be detected twice. This iterative scheme can be applied to both one-stage and two-stage object detectors with just minor modifications of the training and inference procedures. We perform extensive experiments with two different baseline detectors on four datasets and show significant improvement over the baseline, leading to state-of-the-art performance on CrowdHuman and WiderPerson datasets. The source code and the trained models are available at https://github.com/saic-vul/iterdet.
f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
Jan 28, 2020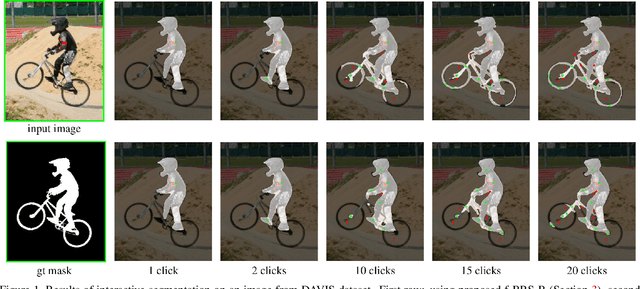
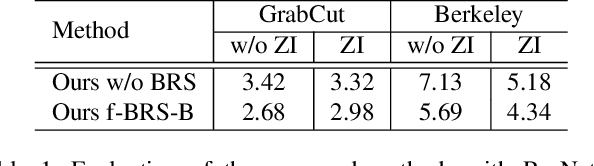
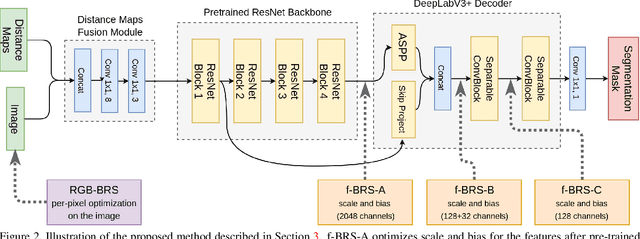
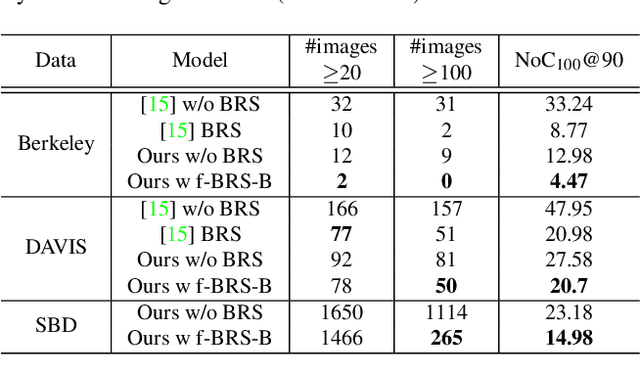
Deep neural networks have become a mainstream approach to interactive segmentation. As we show in our experiments, while for some images a trained network provides accurate segmentation result with just a few clicks, for some unknown objects it cannot achieve satisfactory result even with a large amount of user input. Recently proposed backpropagating refinement (BRS) scheme introduces an optimization problem for interactive segmentation that results in significantly better performance for the hard cases. At the same time, BRS requires running forward and backward pass through a deep network several times that leads to significantly increased computational budget per click compared to other methods. We propose f-BRS (feature backpropagating refinement scheme) that solves an optimization problem with respect to auxiliary variables instead of the network inputs, and requires running forward and backward pass just for a small part of a network. Experiments on GrabCut, Berkeley, DAVIS and SBD datasets set new state-of-the-art at an order of magnitude lower time per click compared to original BRS. The code and trained models are available at https://github.com/saic-vul/fbrs_interactive_segmentation .
Training Deep SLAM on Single Frames
Dec 11, 2019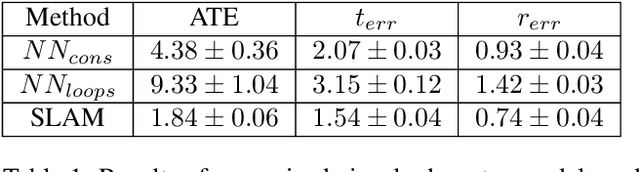

Learning-based visual odometry and SLAM methods demonstrate a steady improvement over past years. However, collecting ground truth poses to train these methods is difficult and expensive. This could be resolved by training in an unsupervised mode, but there is still a large gap between performance of unsupervised and supervised methods. In this work, we focus on generating synthetic data for deep learning-based visual odometry and SLAM methods that take optical flow as an input. We produce training data in a form of optical flow that corresponds to arbitrary camera movement between a real frame and a virtual frame. For synthesizing data we use depth maps either produced by a depth sensor or estimated from stereo pair. We train visual odometry model on synthetic data and do not use ground truth poses hence this model can be considered unsupervised. Also it can be classified as monocular as we do not use depth maps on inference. We also propose a simple way to convert any visual odometry model into a SLAM method based on frame matching and graph optimization. We demonstrate that both the synthetically-trained visual odometry model and the proposed SLAM method build upon this model yields state-of-the-art results among unsupervised methods on KITTI dataset and shows promising results on a challenging EuRoC dataset.
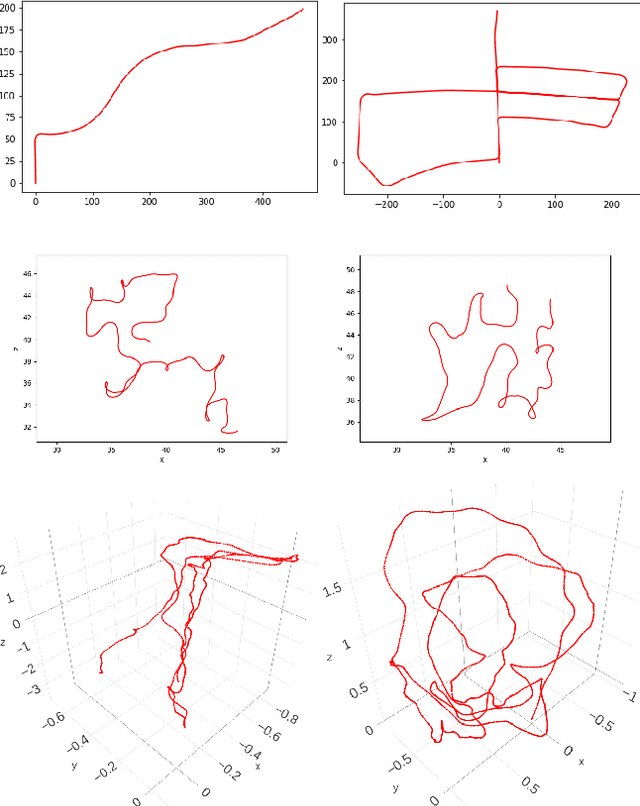
Measuring robustness of Visual SLAM
Oct 10, 2019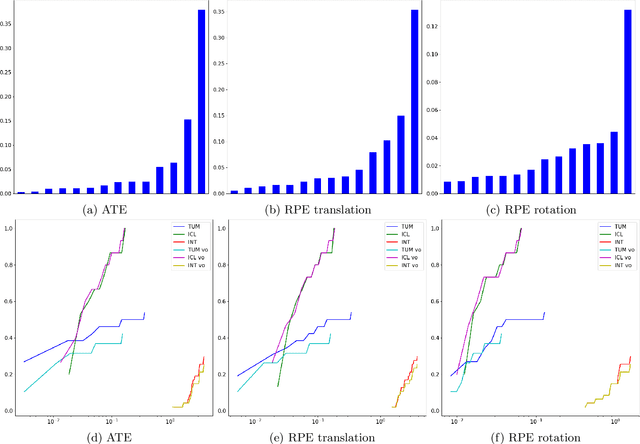
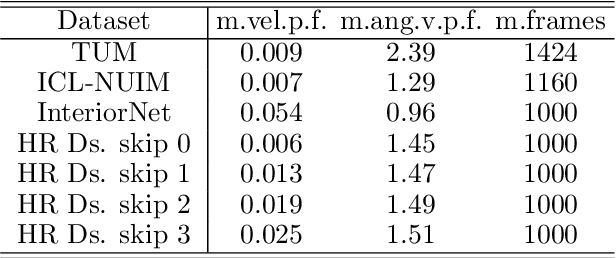
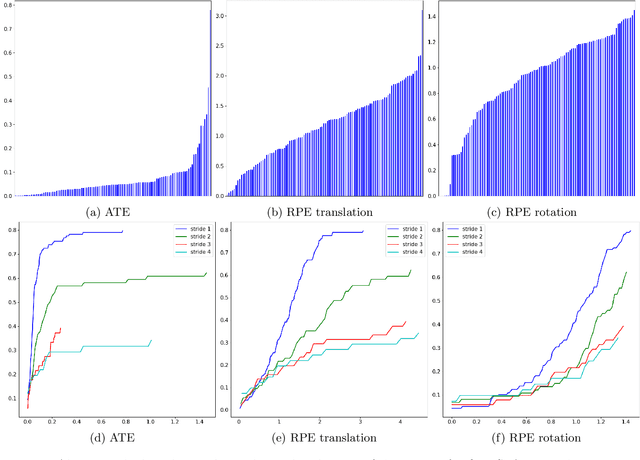
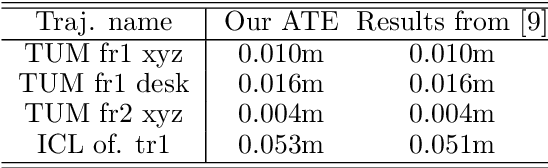
Simultaneous localization and mapping (SLAM) is an essential component of robotic systems. In this work we perform a feasibility study of RGB-D SLAM for the task of indoor robot navigation. Recent visual SLAM methods, e.g. ORBSLAM2 \cite{mur2017orb}, demonstrate really impressive accuracy, but the experiments in the papers are usually conducted on just a few sequences, that makes it difficult to reason about the robustness of the methods. Another problem is that all available RGB-D datasets contain the trajectories with very complex camera motions. In this work we extensively evaluate ORBSLAM2 to better understand the state-of-the-art. First, we conduct experiments on the popular publicly available datasets for RGB-D SLAM across the conventional metrics. We perform statistical analysis of the results and find correlations between the metrics and the attributes of the trajectories. Then, we introduce a new large and diverse HomeRobot dataset where we model the motions of a simple home robot. Our dataset is created using physically-based rendering with realistic lighting and contains the scenes composed by human designers. It includes thousands of sequences, that is two orders of magnitude greater than in previous works. We find that while in many cases the accuracy of SLAM is very good, the robustness is still an issue.
DISCOMAN: Dataset of Indoor SCenes for Odometry, Mapping And Navigation
Sep 26, 2019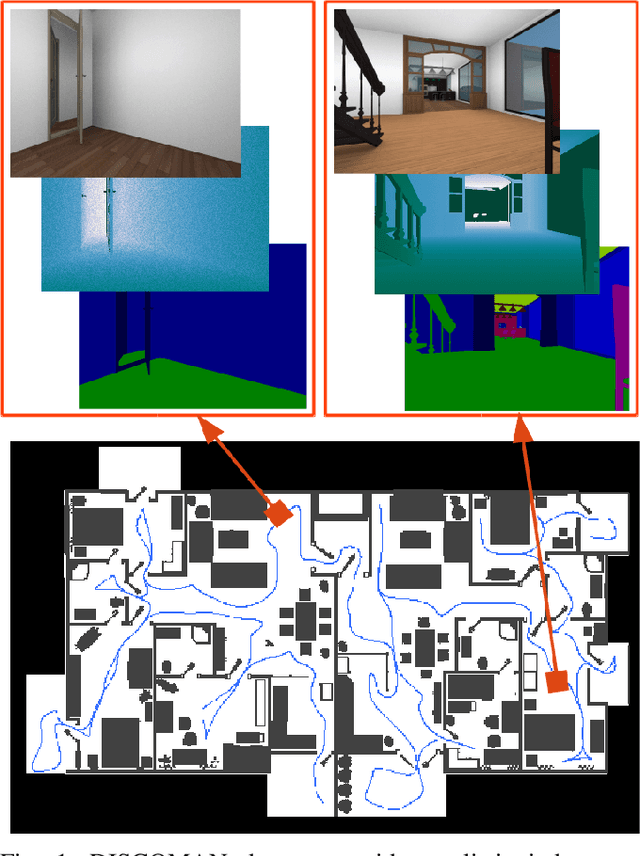

We present a novel dataset for training and benchmarking semantic SLAM methods. The dataset consists of 200 long sequences, each one containing 3000-5000 data frames. We generate the sequences using realistic home layouts. For that we sample trajectories that simulate motions of a simple home robot, and then render the frames along the trajectories. Each data frame contains a) RGB images generated using physically-based rendering, b) simulated depth measurements, c) simulated IMU readings and d) ground truth occupancy grid of a house. Our dataset serves a wider range of purposes compared to existing datasets and is the first large-scale benchmark focused on the mapping component of SLAM. The dataset is split into train/validation/test parts sampled from different sets of virtual houses. We present benchmarking results forboth classical geometry-based and recent learning-based SLAM algorithms, a baseline mapping method, semantic segmentation and panoptic segmentation.
AdaptIS: Adaptive Instance Selection Network
Sep 17, 2019
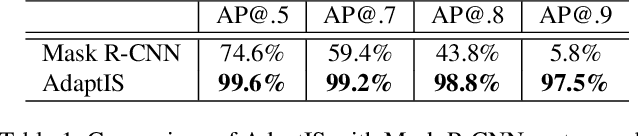

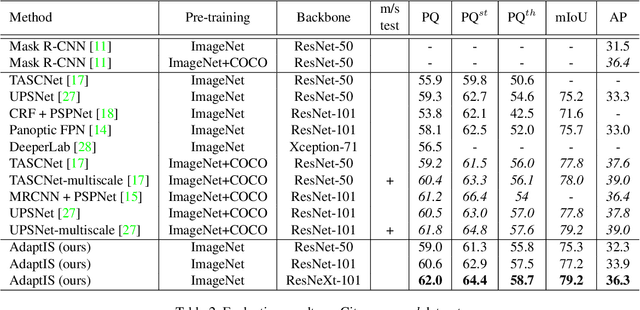
We present Adaptive Instance Selection network architecture for class-agnostic instance segmentation. Given an input image and a point $(x, y)$, it generates a mask for the object located at $(x, y)$. The network adapts to the input point with a help of AdaIN layers, thus producing different masks for different objects on the same image. AdaptIS generates pixel-accurate object masks, therefore it accurately segments objects of complex shape or severely occluded ones. AdaptIS can be easily combined with standard semantic segmentation pipeline to perform panoptic segmentation. To illustrate the idea, we perform experiments on a challenging toy problem with difficult occlusions. Then we extensively evaluate the method on panoptic segmentation benchmarks. We obtain state-of-the-art results on Cityscapes and Mapillary even without pretraining on COCO, and show competitive results on a challenging COCO dataset. The source code of the method and the trained models are available at https://github.com/saic-vul/adaptis.
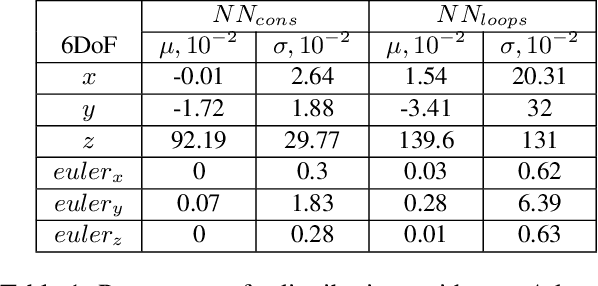
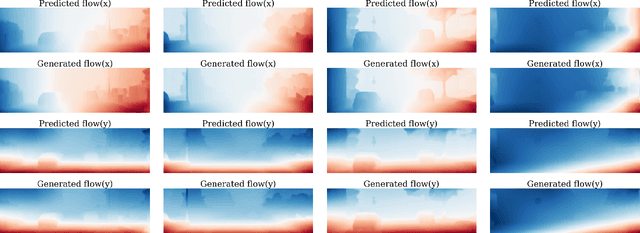
Scene Motion Decomposition for Learnable Visual Odometry
Jul 16, 2019
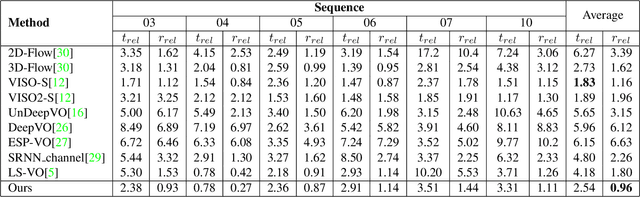
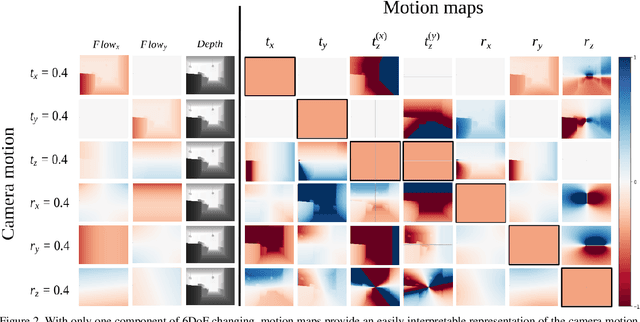

Optical Flow (OF) and depth are commonly used for visual odometry since they provide sufficient information about camera ego-motion in a rigid scene. We reformulate the problem of ego-motion estimation as a problem of motion estimation of a 3D-scene with respect to a static camera. The entire scene motion can be represented as a combination of motions of its visible points. Using OF and depth we estimate a motion of each point in terms of 6DoF and represent results in the form of motion maps, each one addressing single degree of freedom. In this work we provide motion maps as inputs to a deep neural network that predicts 6DoF of scene motion. Through our evaluation on outdoor and indoor datasets we show that utilizing motion maps leads to accuracy improvement in comparison with naive stacking of depth and OF. Another contribution of our work is a novel network architecture that efficiently exploits motion maps and outperforms learnable RGB/RGB-D baselines.