 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviving Iterative Training with Mask Guidance for Interactive Segmentation
Feb 12, 2021


Recent works on click-based interactive segmentation have demonstrated state-of-the-art results by using various inference-time optimization schemes. These methods are considerably more computationally expensive compared to feedforward approaches, as they require performing backward passes through a network during inference and are hard to deploy on mobile frameworks that usually support only forward passes. In this paper, we extensively evaluate various design choices for interactive segmentation and discover that new state-of-the-art results can be obtained without any additional optimization schemes. Thus, we propose a simple feedforward model for click-based interactive segmentation that employs the segmentation masks from previous steps. It allows not only to segment an entirely new object, but also to start with an external mask and correct it. When analyzing the performance of models trained on different datasets, we observe that the choice of a training dataset greatly impacts the quality of interactive segmentation. We find that the models trained on a combination of COCO and LVIS with diverse and high-quality annotations show performance superior to all existing models. The code and trained models are available at https://github.com/saic-vul/ritm_interactive_segmentation.
Learning High-Resolution Domain-Specific Representations with a GAN Generator
Jun 18, 2020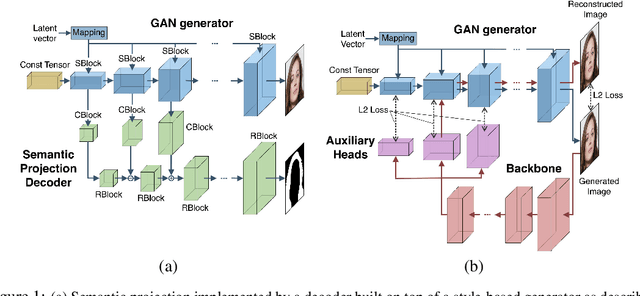


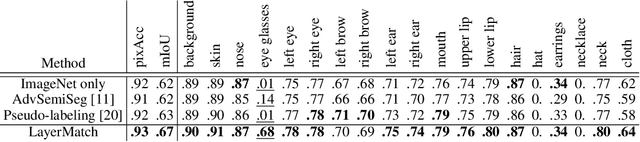
In recent years generative models of visual data have made a great progress, and now they are able to produce images of high quality and diversity. In this work we study representations learnt by a GAN generator. First, we show that these representations can be easily projected onto semantic segmentation map using a lightweight decoder. We find that such semantic projection can be learnt from just a few annotated images. Based on this finding, we propose LayerMatch scheme for approximating the representation of a GAN generator that can be used for unsupervised domain-specific pretraining. We consider the semi-supervised learning scenario when a small amount of labeled data is available along with a large unlabeled dataset from the same domain. We find that the use of LayerMatch-pretrained backbone leads to superior accuracy compared to standard supervised pretraining on ImageNet. Moreover, this simple approach also outperforms recent semi-supervised semantic segmentation methods that use both labeled and unlabeled data during training. Source code for reproducing our experiments will be available at the time of publication.
Foreground-aware Semantic Representations for Image Harmonization
Jun 01, 2020


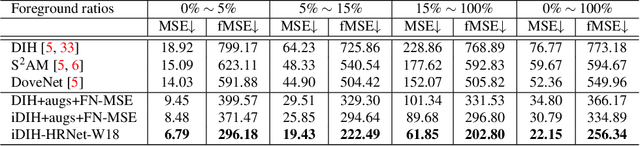
Image harmonization is an important step in photo editing to achieve visual consistency in composite images by adjusting the appearances of foreground to make it compatible with background. Previous approaches to harmonize composites are based on training of encoder-decoder networks from scratch, which makes it challenging for a neural network to learn a high-level representation of objects. We propose a novel architecture to utilize the space of high-level features learned by a pre-trained classification network. We create our models as a combination of existing encoder-decoder architectures and a pre-trained foreground-aware deep high-resolution network. We extensively evaluate the proposed method on existing image harmonization benchmark and set up a new state-of-the-art in terms of MSE and PSNR metrics. The code and trained models are available at \url{https://github.com/saic-vul/image_harmonization}.
IterDet: Iterative Scheme for ObjectDetection in Crowded Environments
May 12, 2020
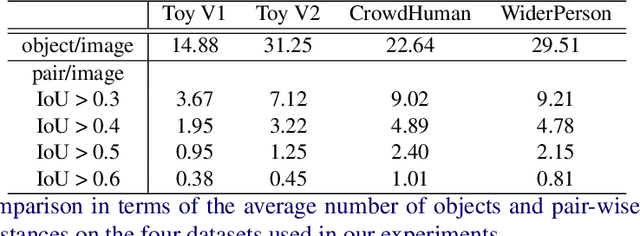
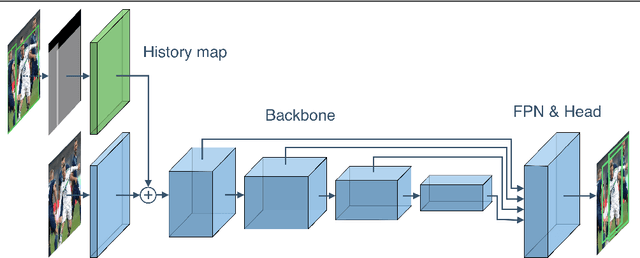
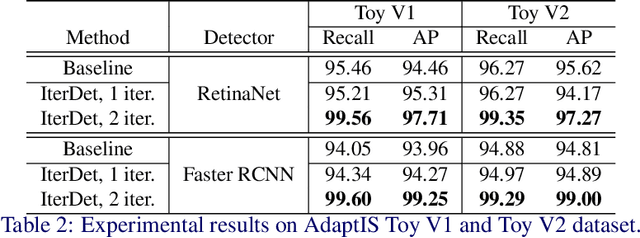
Deep learning-based detectors usually produce a redundant set of object bounding boxes including many duplicate detections of the same object. These boxes are then filtered using non-maximum suppression (NMS) in order to select exactly one bounding box per object of interest. This greedy scheme is simple and provides sufficient accuracy for isolated objects but often fails in crowded environments, since one needs to both preserve boxes for different objects and suppress duplicate detections. In this work we develop an alternative iterative scheme, where a new subset of objects is detected at each iteration. Detected boxes from the previous iterations are passed to the network at the following iterations to ensure that the same object would not be detected twice. This iterative scheme can be applied to both one-stage and two-stage object detectors with just minor modifications of the training and inference procedures. We perform extensive experiments with two different baseline detectors on four datasets and show significant improvement over the baseline, leading to state-of-the-art performance on CrowdHuman and WiderPerson datasets. The source code and the trained models are available at https://github.com/saic-vul/iterdet.
f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
Jan 28, 2020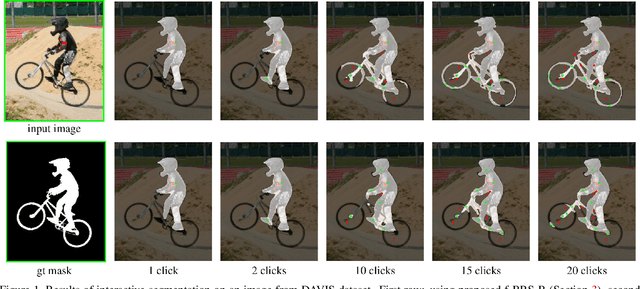
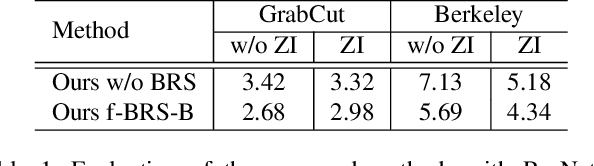
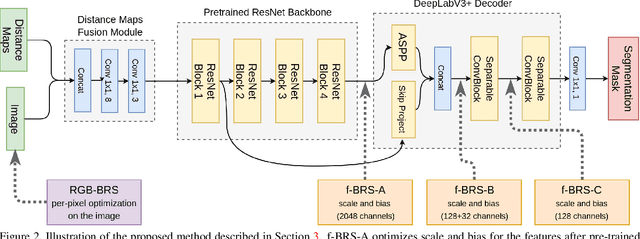
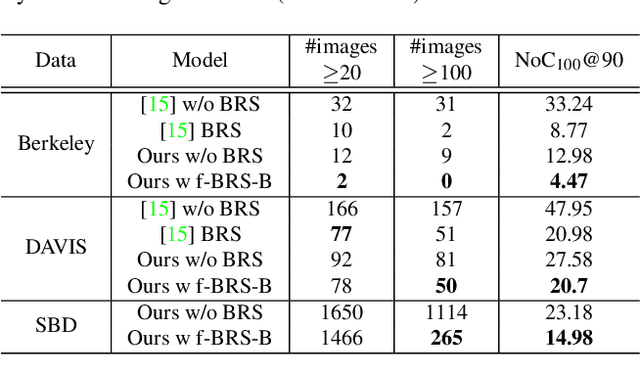
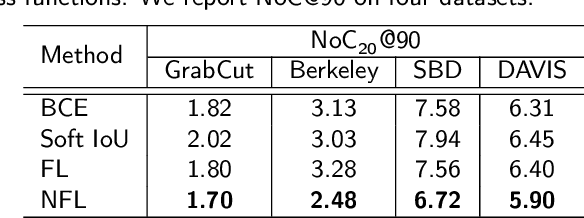
Deep neural networks have become a mainstream approach to interactive segmentation. As we show in our experiments, while for some images a trained network provides accurate segmentation result with just a few clicks, for some unknown objects it cannot achieve satisfactory result even with a large amount of user input. Recently proposed backpropagating refinement (BRS) scheme introduces an optimization problem for interactive segmentation that results in significantly better performance for the hard cases. At the same time, BRS requires running forward and backward pass through a deep network several times that leads to significantly increased computational budget per click compared to other methods. We propose f-BRS (feature backpropagating refinement scheme) that solves an optimization problem with respect to auxiliary variables instead of the network inputs, and requires running forward and backward pass just for a small part of a network. Experiments on GrabCut, Berkeley, DAVIS and SBD datasets set new state-of-the-art at an order of magnitude lower time per click compared to original BRS. The code and trained models are available at https://github.com/saic-vul/fbrs_interactive_segmentation .
DISCOMAN: Dataset of Indoor SCenes for Odometry, Mapping And Navigation
Sep 26, 2019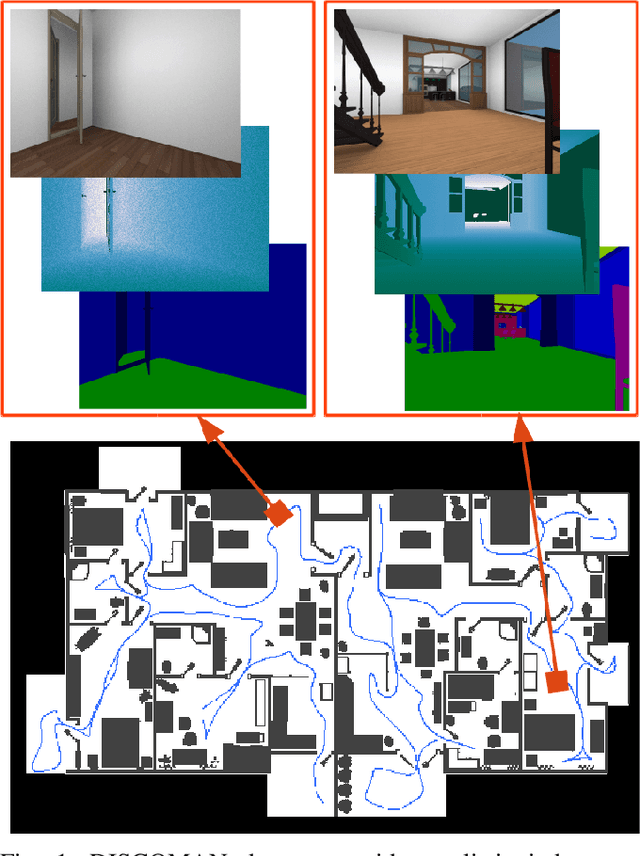
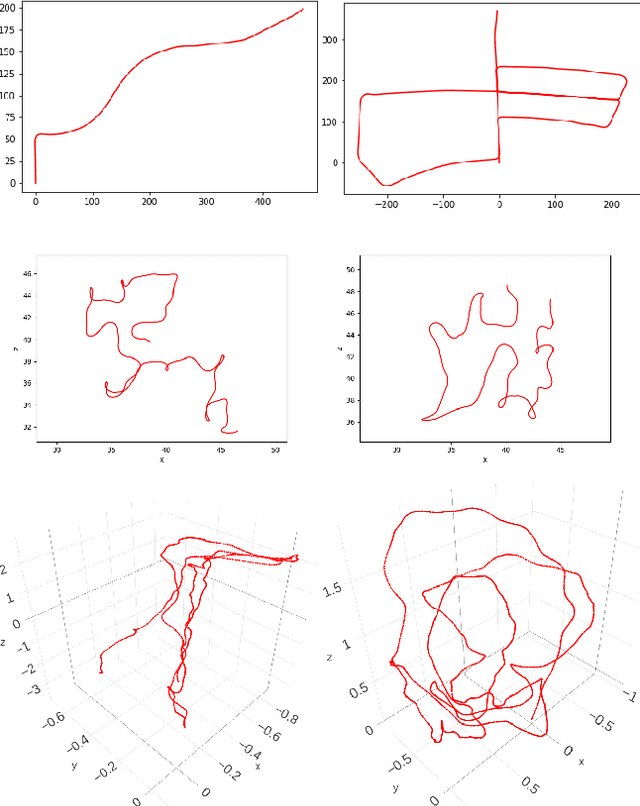
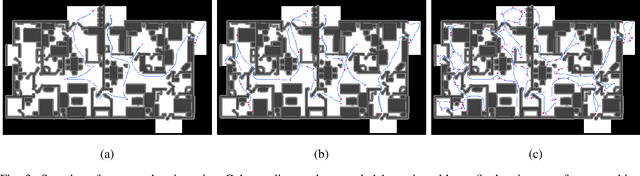

We present a novel dataset for training and benchmarking semantic SLAM methods. The dataset consists of 200 long sequences, each one containing 3000-5000 data frames. We generate the sequences using realistic home layouts. For that we sample trajectories that simulate motions of a simple home robot, and then render the frames along the trajectories. Each data frame contains a) RGB images generated using physically-based rendering, b) simulated depth measurements, c) simulated IMU readings and d) ground truth occupancy grid of a house. Our dataset serves a wider range of purposes compared to existing datasets and is the first large-scale benchmark focused on the mapping component of SLAM. The dataset is split into train/validation/test parts sampled from different sets of virtual houses. We present benchmarking results forboth classical geometry-based and recent learning-based SLAM algorithms, a baseline mapping method, semantic segmentation and panoptic segmentation.
AdaptIS: Adaptive Instance Selection Network
Sep 17, 2019
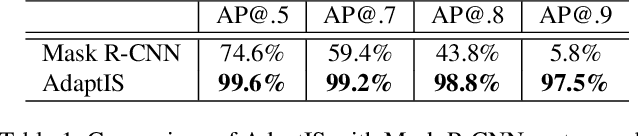

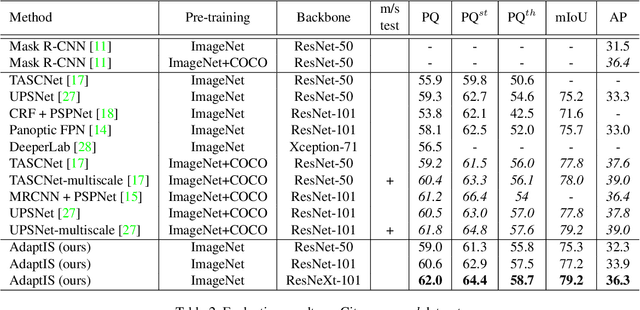
We present Adaptive Instance Selection network architecture for class-agnostic instance segmentation. Given an input image and a point $(x, y)$, it generates a mask for the object located at $(x, y)$. The network adapts to the input point with a help of AdaIN layers, thus producing different masks for different objects on the same image. AdaptIS generates pixel-accurate object masks, therefore it accurately segments objects of complex shape or severely occluded ones. AdaptIS can be easily combined with standard semantic segmentation pipeline to perform panoptic segmentation. To illustrate the idea, we perform experiments on a challenging toy problem with difficult occlusions. Then we extensively evaluate the method on panoptic segmentation benchmarks. We obtain state-of-the-art results on Cityscapes and Mapillary even without pretraining on COCO, and show competitive results on a challenging COCO dataset. The source code of the method and the trained models are available at https://github.com/saic-vul/adaptis.