 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAPS: Rethinking Image Similarity for Virtual Staining
May 19, 2026Virtual staining of histopathology images (e.g., H&E-IHC) is an emerging tool in digital pathology, enabling faster and cheaper workflows by synthesizing target stains from routinely acquired slides. Yet, the quality of virtual staining models is still predominantly assessed with generic metrics such as SSIM, PSNR, and LPIPS. Originally developed for natural images, these metrics are inherently misaligned with the domain-specific characteristics of histological data, failing to capture tissue morphology preservation and biomarker expression patterns. Consequently, a robust, domain-specific standard for quantifying similarity across diverse histological modalities remains a critical gap in the field. In this work, we formalize histology image similarity as a standalone problem and systematically evaluate a broad set of full-reference metrics against a dataset of H&E-IHC patch pairs annotated with expert similarity scores. We further analyze metrics sensitivity to controlled geometric distortions (shifts, rotations and non-rigid deformations) that mimic realistic registration errors between serial sections. Guided by these observations, we propose the Histology-Aware Perceptual Similarity (HAPS) metric. HAPS computes distances in the feature space of a frozen encoder pretrained on histopathology data, adding a linear head to aggregate feature-level differences into a final score that aligns with expert assessments. Finally, we demonstrate the practical value of HAPS for quality control of training data. By quantifying the similarity of training pairs in the MIST dataset and filtering low-scoring samples, we create a cleaner training set. Virtual staining models trained on this refined data outperform those trained on the original, unfiltered dataset.
YaART: Yet Another ART Rendering Technology
Apr 08, 2024



In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
Single-Stage 3D Geometry-Preserving Depth Estimation Model Training on Dataset Mixtures with Uncalibrated Stereo Data
Jun 05, 2023



Nowadays, robotics, AR, and 3D modeling applications attract considerable attention to single-view depth estimation (SVDE) as it allows estimating scene geometry from a single RGB image. Recent works have demonstrated that the accuracy of an SVDE method hugely depends on the diversity and volume of the training data. However, RGB-D datasets obtained via depth capturing or 3D reconstruction are typically small, synthetic datasets are not photorealistic enough, and all these datasets lack diversity. The large-scale and diverse data can be sourced from stereo images or stereo videos from the web. Typically being uncalibrated, stereo data provides disparities up to unknown shift (geometrically incomplete data), so stereo-trained SVDE methods cannot recover 3D geometry. It was recently shown that the distorted point clouds obtained with a stereo-trained SVDE method can be corrected with additional point cloud modules (PCM) separately trained on the geometrically complete data. On the contrary, we propose GP$^{2}$, General-Purpose and Geometry-Preserving training scheme, and show that conventional SVDE models can learn correct shifts themselves without any post-processing, benefiting from using stereo data even in the geometry-preserving setting. Through experiments on different dataset mixtures, we prove that GP$^{2}$-trained models outperform methods relying on PCM in both accuracy and speed, and report the state-of-the-art results in the general-purpose geometry-preserving SVDE. Moreover, we show that SVDE models can learn to predict geometrically correct depth even when geometrically complete data comprises the minor part of the training set.
Towards General Purpose and Geometry Preserving Single-View Depth Estimation
Sep 25, 2020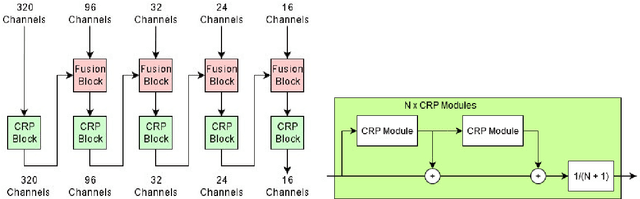
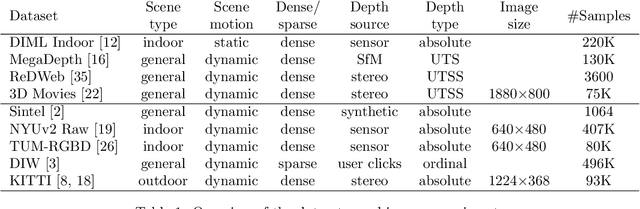
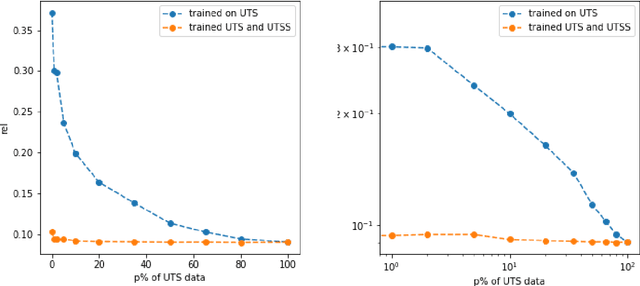

Single-view depth estimation plays a crucial role in scene understanding for AR applications and 3D modelling as it allows to retrieve the geometry of a scene. However, it is only possible if the inverse depth estimates are unbiased, i.e. they are either absolute or Up-to-Scale (UTS). In recent years, great progress has been made in general-purpose single-view depth estimation. Nevertheless, the latest general-purpose models were trained using ranking or on Up-to-Shift-Scale (UTSS) data. As a result, they provide UTSS predictions that cannot be used to reconstruct scene geometry. In this work, we strive to build a general-purpose single-view UTS depth estimation model. Following Ranftl et. al., we train our model on a mixture of datasets and test it on several previously unseen datasets. We show that our method outperforms previous state-of-the-art UTS models. We train several light-weight models following the proposed training scheme and prove that our ideas are applicable for computationally efficient depth estimation.
Learning High-Resolution Domain-Specific Representations with a GAN Generator
Jun 18, 2020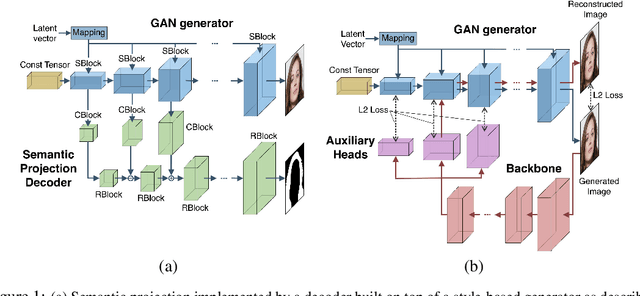


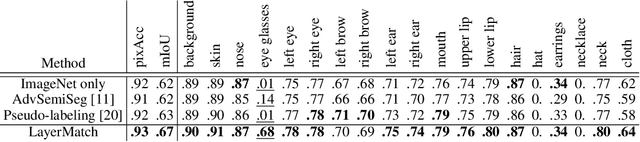
In recent years generative models of visual data have made a great progress, and now they are able to produce images of high quality and diversity. In this work we study representations learnt by a GAN generator. First, we show that these representations can be easily projected onto semantic segmentation map using a lightweight decoder. We find that such semantic projection can be learnt from just a few annotated images. Based on this finding, we propose LayerMatch scheme for approximating the representation of a GAN generator that can be used for unsupervised domain-specific pretraining. We consider the semi-supervised learning scenario when a small amount of labeled data is available along with a large unlabeled dataset from the same domain. We find that the use of LayerMatch-pretrained backbone leads to superior accuracy compared to standard supervised pretraining on ImageNet. Moreover, this simple approach also outperforms recent semi-supervised semantic segmentation methods that use both labeled and unlabeled data during training. Source code for reproducing our experiments will be available at the time of publication.
Double Refinement Network for Efficient Indoor Monocular Depth Estimation
Nov 20, 2018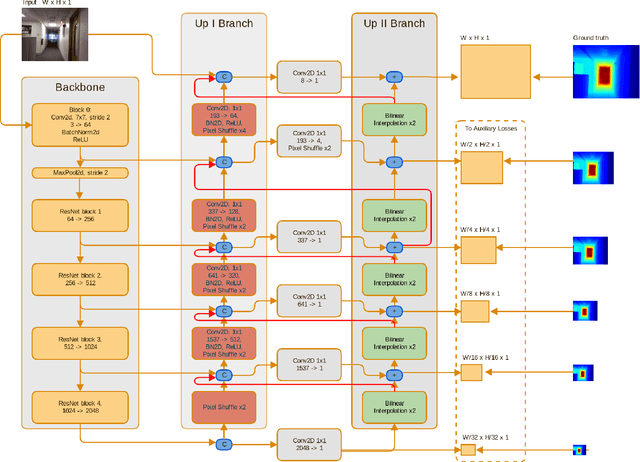

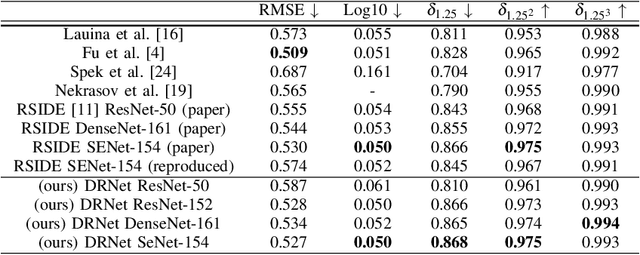
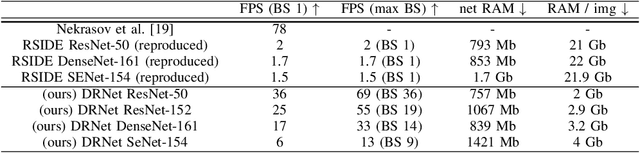
Monocular Depth Estimation is an important problem of Computer Vision that may be solved with Neural Networks and Deep Learning nowadays. Though recent works in this area have shown significant improvement in accuracy, state-of-the-art methods require large memory and time resources. The main purpose of this paper is to improve performance of the latest solutions with no decrease in accuracy. To achieve this, we propose a Double Refinement Network architecture. We evaluate the results using the standard benchmark RGB-D dataset NYU Depth v2. The results are equal to the current state-of-the-art, while frames per second rate of our approach is significantly higher (up to 15 times speedup per image with batch size 1), RAM per image is significantly lower.