 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour-based Interactive Segmentation
Feb 13, 2023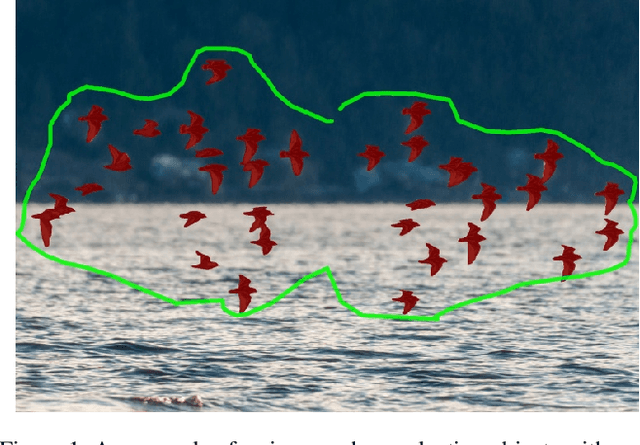
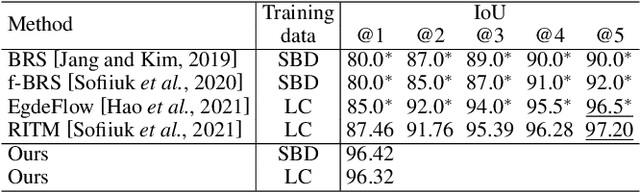
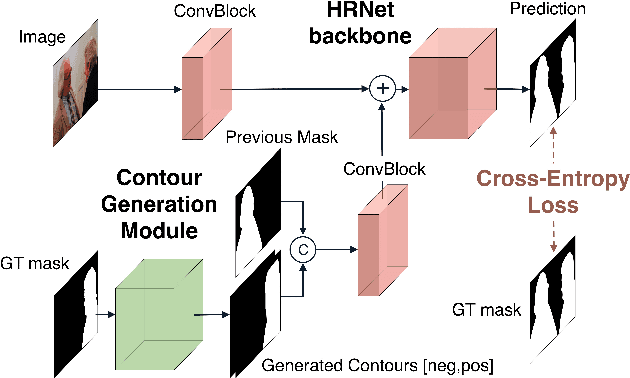
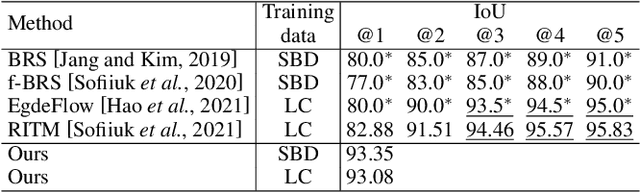
Recent advances in interactive segmentation (IS) allow speeding up and simplifying image editing and labeling greatly. The majority of modern IS approaches accept user input in the form of clicks. However, using clicks may require too many user interactions, especially when selecting small objects, minor parts of an object, or a group of objects of the same type. In this paper, we consider such a natural form of user interaction as a loose contour, and introduce a contour-based IS method. We evaluate the proposed method on the standard segmentation benchmarks, our novel UserContours dataset, and its subset UserContours-G containing difficult segmentation cases. Through experiments, we demonstrate that a single contour provides the same accuracy as multiple clicks, thus reducing the required amount of user interactions.
Learning High-Resolution Domain-Specific Representations with a GAN Generator
Jun 18, 2020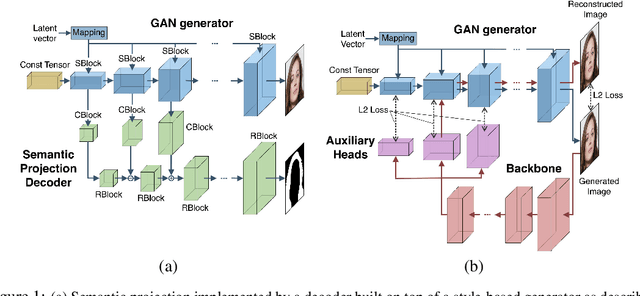


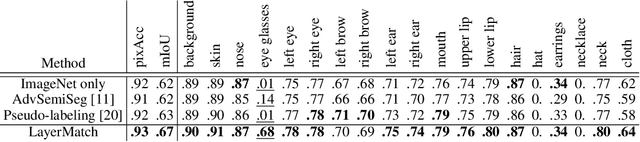
In recent years generative models of visual data have made a great progress, and now they are able to produce images of high quality and diversity. In this work we study representations learnt by a GAN generator. First, we show that these representations can be easily projected onto semantic segmentation map using a lightweight decoder. We find that such semantic projection can be learnt from just a few annotated images. Based on this finding, we propose LayerMatch scheme for approximating the representation of a GAN generator that can be used for unsupervised domain-specific pretraining. We consider the semi-supervised learning scenario when a small amount of labeled data is available along with a large unlabeled dataset from the same domain. We find that the use of LayerMatch-pretrained backbone leads to superior accuracy compared to standard supervised pretraining on ImageNet. Moreover, this simple approach also outperforms recent semi-supervised semantic segmentation methods that use both labeled and unlabeled data during training. Source code for reproducing our experiments will be available at the time of publication.
IterDet: Iterative Scheme for ObjectDetection in Crowded Environments
May 12, 2020
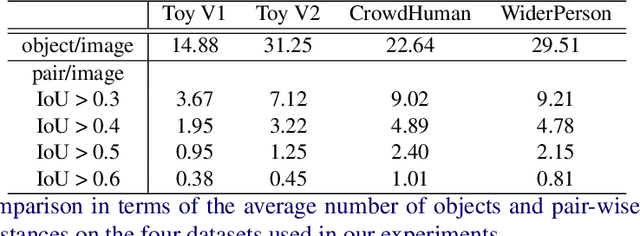
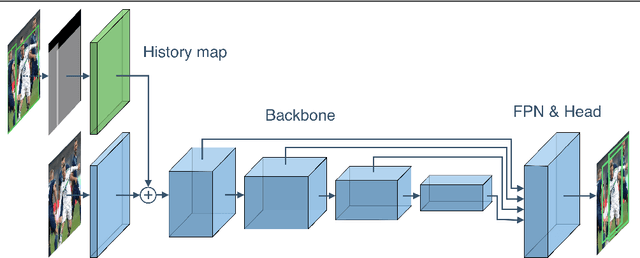
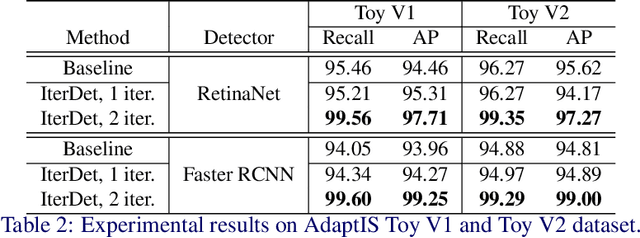
Deep learning-based detectors usually produce a redundant set of object bounding boxes including many duplicate detections of the same object. These boxes are then filtered using non-maximum suppression (NMS) in order to select exactly one bounding box per object of interest. This greedy scheme is simple and provides sufficient accuracy for isolated objects but often fails in crowded environments, since one needs to both preserve boxes for different objects and suppress duplicate detections. In this work we develop an alternative iterative scheme, where a new subset of objects is detected at each iteration. Detected boxes from the previous iterations are passed to the network at the following iterations to ensure that the same object would not be detected twice. This iterative scheme can be applied to both one-stage and two-stage object detectors with just minor modifications of the training and inference procedures. We perform extensive experiments with two different baseline detectors on four datasets and show significant improvement over the baseline, leading to state-of-the-art performance on CrowdHuman and WiderPerson datasets. The source code and the trained models are available at https://github.com/saic-vul/iterdet.
MixMatch Domain Adaptaion: Prize-winning solution for both tracks of VisDA 2019 challenge
Oct 09, 2019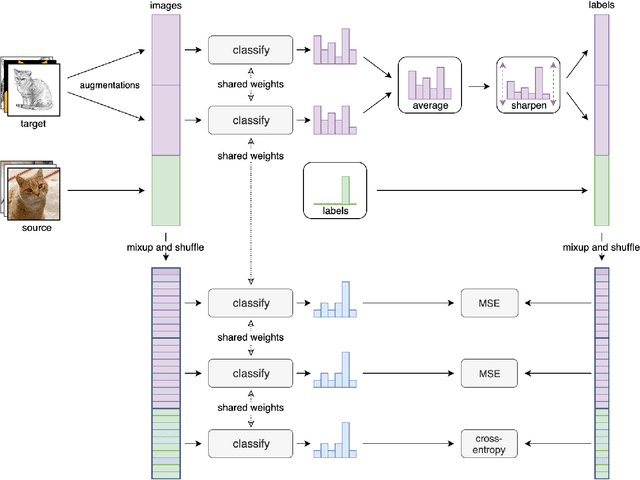

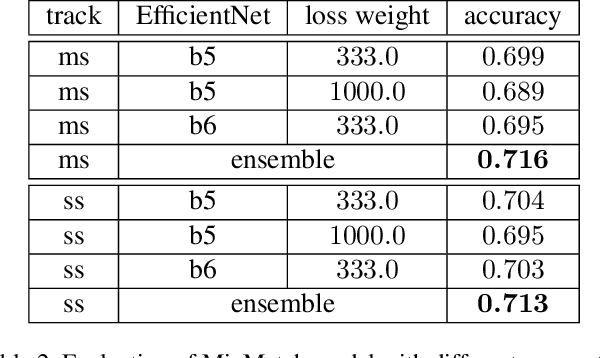
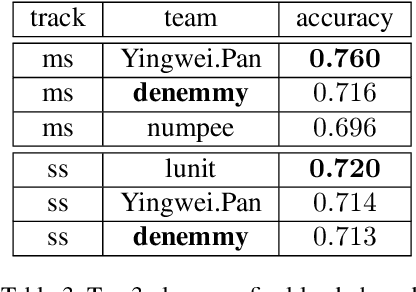
We present a domain adaptation (DA) system that can be used in multi-source and semi-supervised settings. Using the proposed method we achieved 2nd place on multi-source track and 3rd place on semi-supervised track of the VisDA 2019 challenge (http://ai.bu.edu/visda-2019/). The source code of the method is available at https://github.com/filaPro/visda2019.