 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Diffusion Beat GAN in Image Super Resolution?
May 27, 2024



There is a prevalent opinion in the recent literature that Diffusion-based models outperform GAN-based counterparts on the Image Super Resolution (ISR) problem. However, in most studies, Diffusion-based ISR models were trained longer and utilized larger networks than the GAN baselines. This raises the question of whether the superiority of Diffusion models is due to the Diffusion paradigm being better suited for the ISR task or if it is a consequence of the increased scale and computational resources used in contemporary studies. In our work, we compare Diffusion-based and GAN-based Super Resolution under controlled settings, where both approaches are matched in terms of architecture, model and dataset size, and computational budget. We show that a GAN-based model can achieve results comparable to a Diffusion-based model. Additionally, we explore the impact of design choices such as text conditioning and augmentation on the performance of ISR models, showcasing their effect on several downstream tasks. We will release the inference code and weights of our scaled GAN.
YaART: Yet Another ART Rendering Technology
Apr 08, 2024In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 20, 2024



This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.
PyTorch Image Quality: Metrics for Image Quality Assessment
Aug 31, 2022
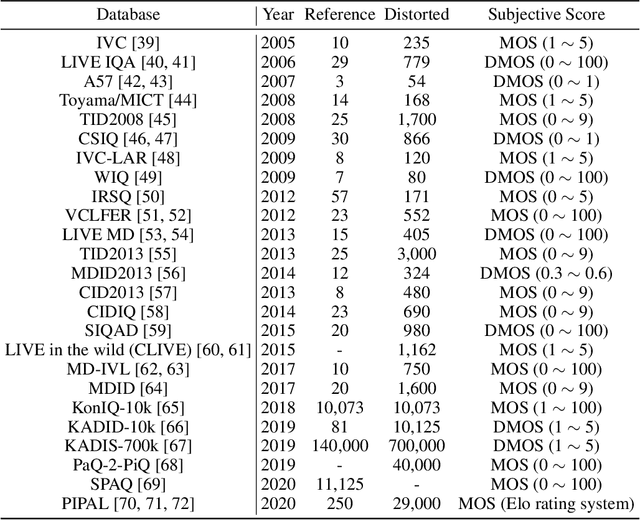
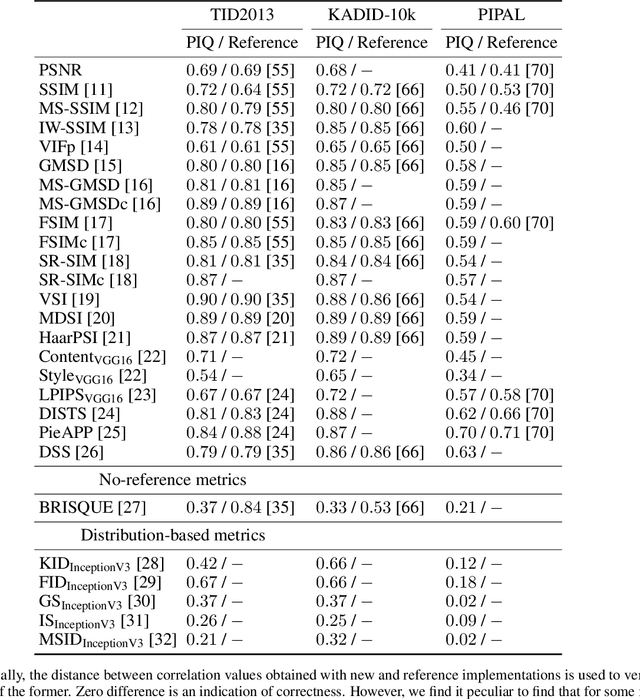
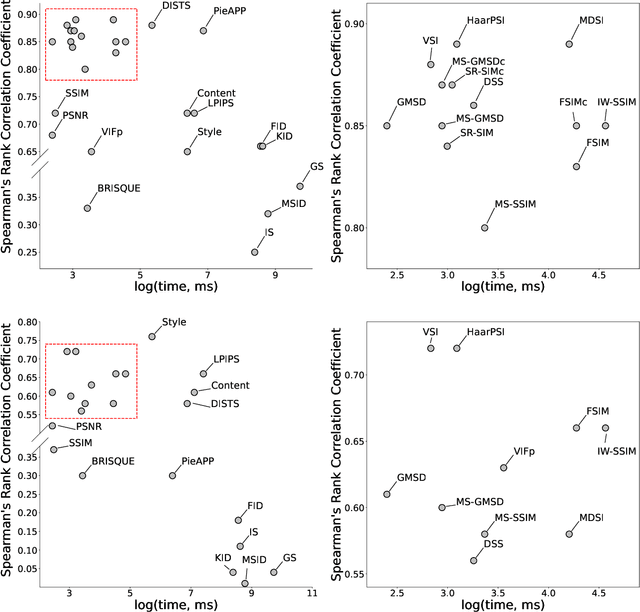
Image Quality Assessment (IQA) metrics are widely used to quantitatively estimate the extent of image degradation following some forming, restoring, transforming, or enhancing algorithms. We present PyTorch Image Quality (PIQ), a usability-centric library that contains the most popular modern IQA algorithms, guaranteed to be correctly implemented according to their original propositions and thoroughly verified. In this paper, we detail the principles behind the foundation of the library, describe the evaluation strategy that makes it reliable, provide the benchmarks that showcase the performance-time trade-offs, and underline the benefits of GPU acceleration given the library is used within the PyTorch backend. PyTorch Image Quality is an open source software: https://github.com/photosynthesis-team/piq/.
Towards Ultrafast MRI via Extreme k-Space Undersampling and Superresolution
Mar 04, 2021
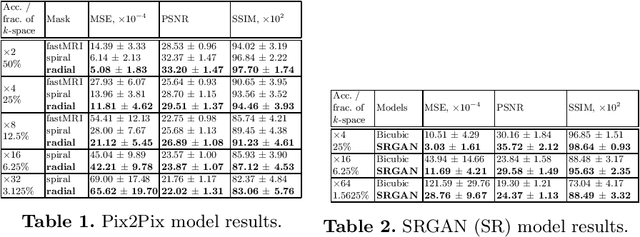
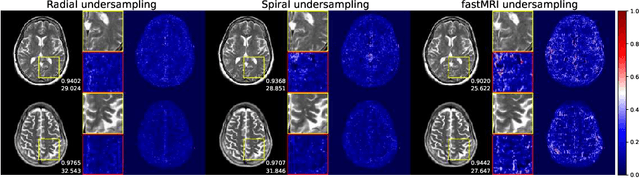

We went below the MRI acceleration factors (a.k.a., k-space undersampling) reported by all published papers that reference the original fastMRI challenge, and then considered powerful deep learning based image enhancement methods to compensate for the underresolved images. We thoroughly study the influence of the sampling patterns, the undersampling and the downscaling factors, as well as the recovery models on the final image quality for both the brain and the knee fastMRI benchmarks. The quality of the reconstructed images surpasses that of the other methods, yielding an MSE of 0.00114, a PSNR of 29.6 dB, and an SSIM of 0.956 at x16 acceleration factor. More extreme undersampling factors of x32 and x64 are also investigated, holding promise for certain clinical applications such as computer-assisted surgery or radiation planning. We survey 5 expert radiologists to assess 100 pairs of images and show that the recovered undersampled images statistically preserve their diagnostic value.
An Adaptive Intelligence Algorithm for Undersampled Knee MRI Reconstruction: Application to the 2019 fastMRI Challenge
Apr 15, 2020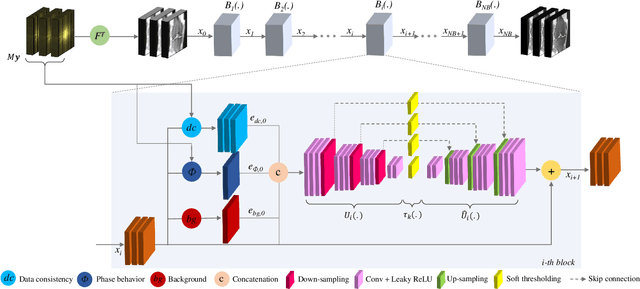
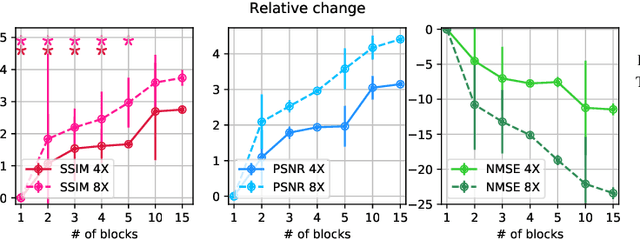
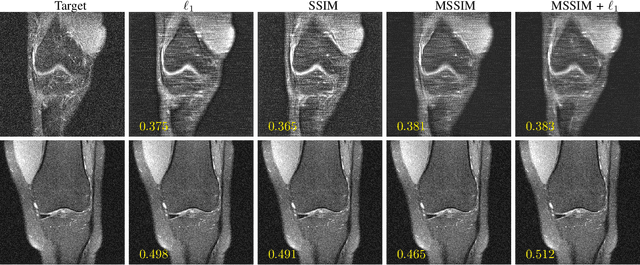

Adaptive intelligence aims at empowering machine learning techniques with the additional use of domain knowledge. In this work, we present the application of adaptive intelligence to accelerate MR acquisition. Starting from undersampled k-space data, an iterative learning-based reconstruction scheme inspired by compressed sensing theory is used to reconstruct the images. We adopt deep neural networks to refine and correct prior reconstruction assumptions given the training data. The network was trained and tested on a knee MRI dataset from the 2019 fastMRI challenge organized by Facebook AI Research and NYU Langone Health. All submissions to the challenge were initially ranked based on similarity with a known groundtruth, after which the top 4 submissions were evaluated radiologically. Our method was evaluated by the fastMRI organizers on an independent challenge dataset. It ranked #1, shared #1, and #3 on respectively the 8x accelerated multi-coil, the 4x multi-coil, and the 4x single-coil track. This demonstrates the superior performance and wide applicability of the method.