 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDONUT-hole: DONUT Sparsification by Harnessing Knowledge and Optimizing Learning Efficiency
Nov 09, 2023This paper introduces DONUT-hole, a sparse OCR-free visual document understanding (VDU) model that addresses the limitations of its predecessor model, dubbed DONUT. The DONUT model, leveraging a transformer architecture, overcoming the challenges of separate optical character recognition (OCR) and visual semantic understanding (VSU) components. However, its deployment in production environments and edge devices is hindered by high memory and computational demands, particularly in large-scale request services. To overcome these challenges, we propose an optimization strategy based on knowledge distillation and model pruning. Our paradigm to produce DONUT-hole, reduces the model denisty by 54\% while preserving performance. We also achieve a global representational similarity index between DONUT and DONUT-hole based on centered kernel alignment (CKA) metric of 0.79. Moreover, we evaluate the effectiveness of DONUT-hole in the document image key information extraction (KIE) task, highlighting its potential for developing more efficient VDU systems for logistic companies.
Joint Registration and Segmentation via Multi-Task Learning for Adaptive Radiotherapy of Prostate Cancer
May 05, 2021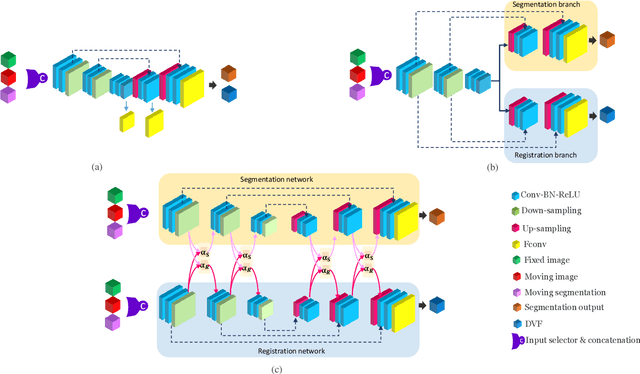
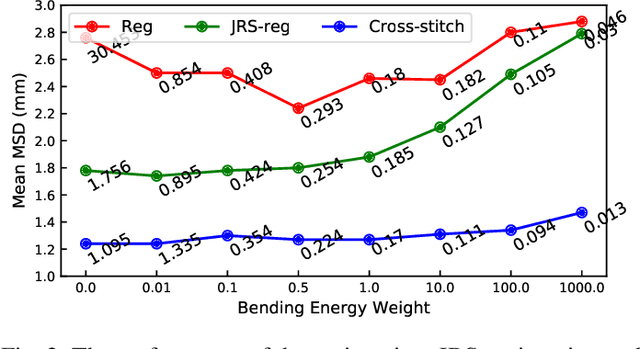
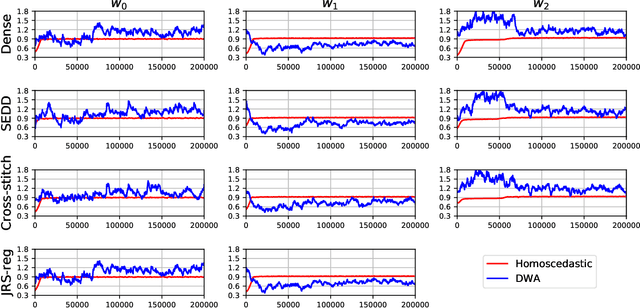
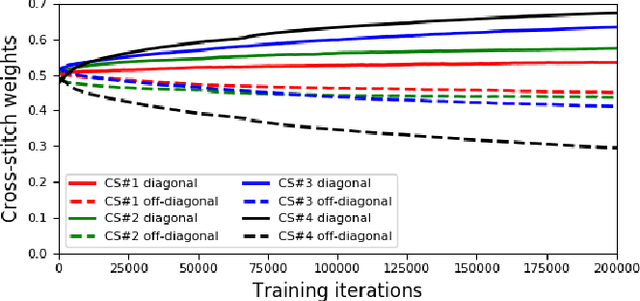
Medical image registration and segmentation are two of the most frequent tasks in medical image analysis. As these tasks are complementary and correlated, it would be beneficial to apply them simultaneously in a joint manner. In this paper, we formulate registration and segmentation as a joint problem via a Multi-Task Learning (MTL) setting, allowing these tasks to leverage their strengths and mitigate their weaknesses through the sharing of beneficial information. We propose to merge these tasks not only on the loss level, but on the architectural level as well. We studied this approach in the context of adaptive image-guided radiotherapy for prostate cancer, where planning and follow-up CT images as well as their corresponding contours are available for training. The study involves two datasets from different manufacturers and institutes. The first dataset was divided into training (12 patients) and validation (6 patients), and was used to optimize and validate the methodology, while the second dataset (14 patients) was used as an independent test set. We carried out an extensive quantitative comparison between the quality of the automatically generated contours from different network architectures as well as loss weighting methods. Moreover, we evaluated the quality of the generated deformation vector field (DVF). We show that MTL algorithms outperform their Single-Task Learning (STL) counterparts and achieve better generalization on the independent test set. The best algorithm achieved a mean surface distance of $1.06 \pm 0.3$ mm, $1.27 \pm 0.4$ mm, $0.91 \pm 0.4$ mm, and $1.76 \pm 0.8$ mm on the validation set for the prostate, seminal vesicles, bladder, and rectum, respectively. The high accuracy of the proposed method combined with the fast inference speed, makes it a promising method for automatic re-contouring of follow-up scans for adaptive radiotherapy.
ASL to PET Translation by a Semi-supervised Residual-based Attention-guided Convolutional Neural Network
Mar 08, 2021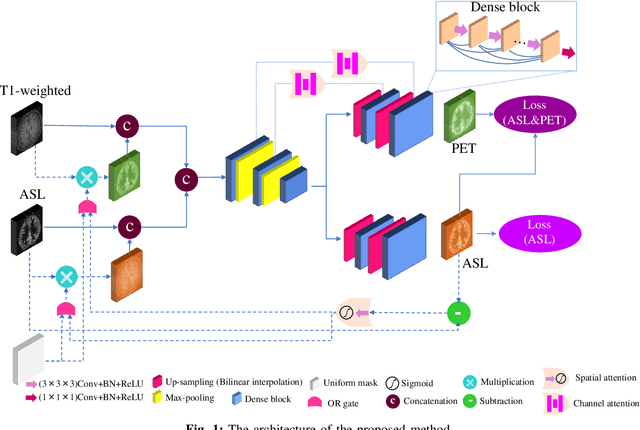
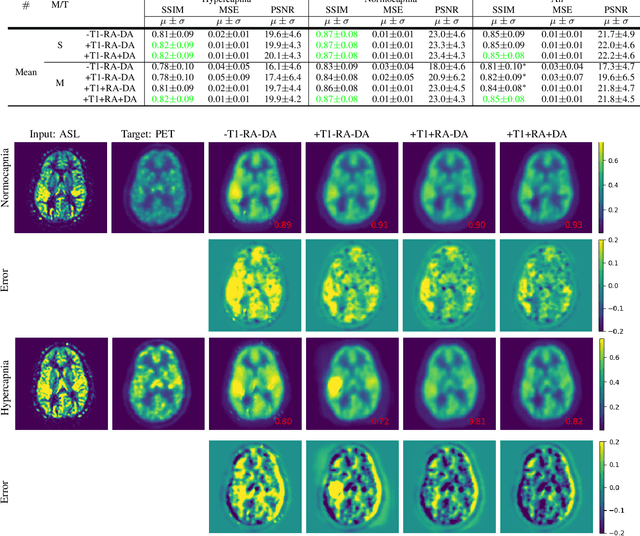
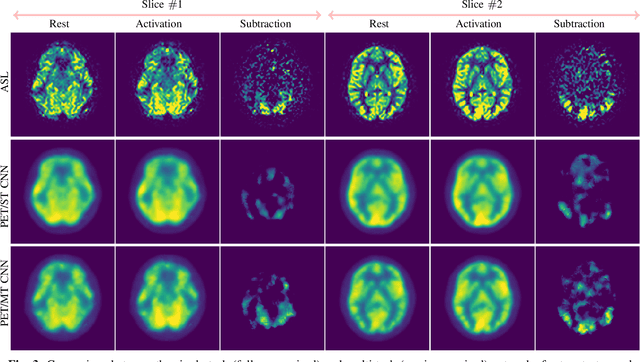
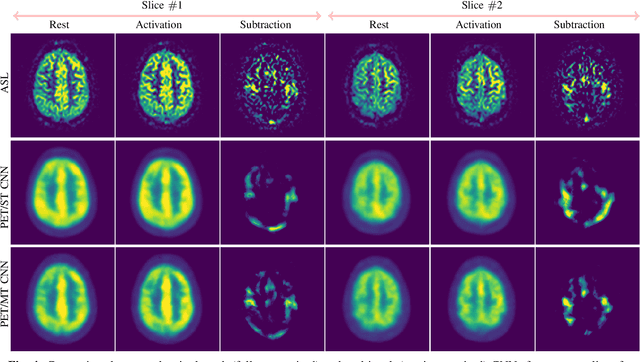
Positron Emission Tomography (PET) is an imaging method that can assess physiological function rather than structural disturbances by measuring cerebral perfusion or glucose consumption. However, this imaging technique relies on injection of radioactive tracers and is expensive. On the contrary, Arterial Spin Labeling (ASL) MRI is a non-invasive, non-radioactive, and relatively cheap imaging technique for brain hemodynamic measurements, which allows quantification to some extent. In this paper we propose a convolutional neural network (CNN) based model for translating ASL to PET images, which could benefit patients as well as the healthcare system in terms of expenses and adverse side effects. However, acquiring a sufficient number of paired ASL-PET scans for training a CNN is prohibitive for many reasons. To tackle this problem, we present a new semi-supervised multitask CNN which is trained on both paired data, i.e. ASL and PET scans, and unpaired data, i.e. only ASL scans, which alleviates the problem of training a network on limited paired data. Moreover, we present a new residual-based-attention guided mechanism to improve the contextual features during the training process. Also, we show that incorporating T1-weighted scans as an input, due to its high resolution and availability of anatomical information, improves the results. We performed a two-stage evaluation based on quantitative image metrics by conducting a 7-fold cross validation followed by a double-blind observer study. The proposed network achieved structural similarity index measure (SSIM), mean squared error (MSE) and peak signal-to-noise ratio (PSNR) values of $0.85\pm0.08$, $0.01\pm0.01$, and $21.8\pm4.5$ respectively, for translating from 2D ASL and T1-weighted images to PET data. The proposed model is publicly available via https://github.com/yousefis/ASL2PET.
Esophageal Tumor Segmentation in CT Images using Dilated Dense Attention Unet (DDAUnet)
Dec 20, 2020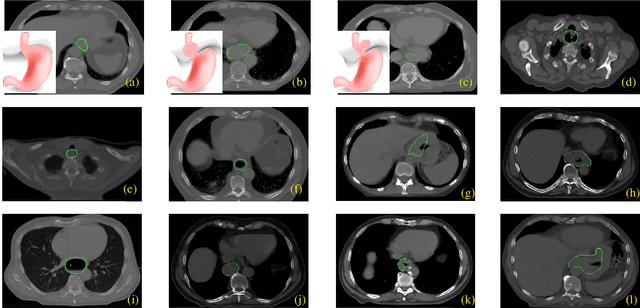
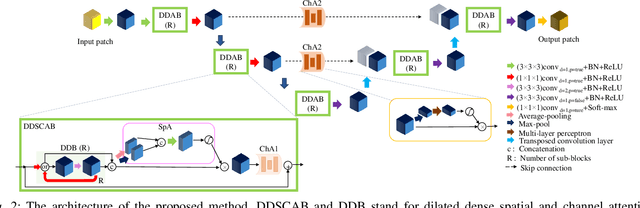
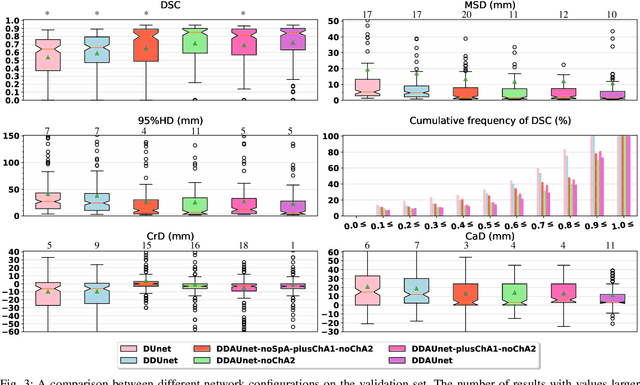

Manual or automatic delineation of the esophageal tumor in CT images is known to be very challenging. This is due to the low contrast between the tumor and adjacent tissues, the anatomical variation of the esophagus, as well as the occasional presence of foreign bodies (e.g. feeding tubes). Physicians therefore usually exploit additional knowledge such as endoscopic findings, clinical history, additional imaging modalities like PET scans. Achieving his additional information is time-consuming, while the results are error-prone and might lead to non-deterministic results. In this paper we aim to investigate if and to what extent a simplified clinical workflow based on CT alone, allows one to automatically segment the esophageal tumor with sufficient quality. For this purpose, we present a fully automatic end-to-end esophageal tumor segmentation method based on convolutional neural networks (CNNs). The proposed network, called Dilated Dense Attention Unet (DDAUnet), leverages spatial and channel attention gates in each dense block to selectively concentrate on determinant feature maps and regions. Dilated convolutional layers are used to manage GPU memory and increase the network receptive field. We collected a dataset of 792 scans from 288 distinct patients including varying anatomies with \mbox{air pockets}, feeding tubes and proximal tumors. Repeatability and reproducibility studies were conducted for three distinct splits of training and validation sets. The proposed network achieved a $\mathrm{DSC}$ value of $0.79 \pm 0.20$, a mean surface distance of $5.4 \pm 20.2mm$ and $95\%$ Hausdorff distance of $14.7 \pm 25.0mm$ for 287 test scans, demonstrating promising results with a simplified clinical workflow based on CT alone. Our code is publicly available via \url{https://github.com/yousefis/DenseUnet_Esophagus_Segmentation}.
An Adaptive Intelligence Algorithm for Undersampled Knee MRI Reconstruction: Application to the 2019 fastMRI Challenge
Apr 15, 2020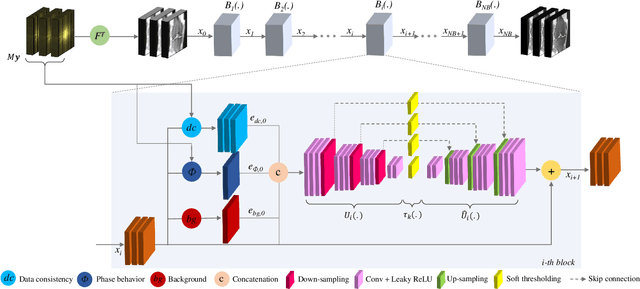
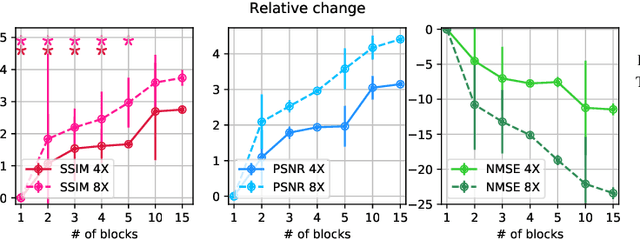
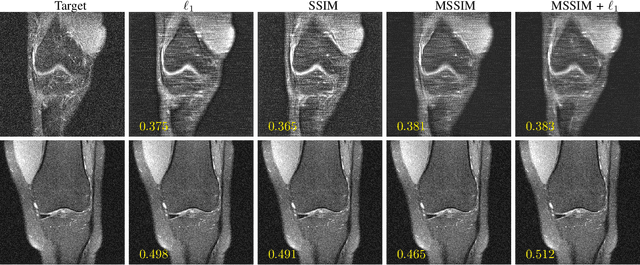

Adaptive intelligence aims at empowering machine learning techniques with the additional use of domain knowledge. In this work, we present the application of adaptive intelligence to accelerate MR acquisition. Starting from undersampled k-space data, an iterative learning-based reconstruction scheme inspired by compressed sensing theory is used to reconstruct the images. We adopt deep neural networks to refine and correct prior reconstruction assumptions given the training data. The network was trained and tested on a knee MRI dataset from the 2019 fastMRI challenge organized by Facebook AI Research and NYU Langone Health. All submissions to the challenge were initially ranked based on similarity with a known groundtruth, after which the top 4 submissions were evaluated radiologically. Our method was evaluated by the fastMRI organizers on an independent challenge dataset. It ranked #1, shared #1, and #3 on respectively the 8x accelerated multi-coil, the 4x multi-coil, and the 4x single-coil track. This demonstrates the superior performance and wide applicability of the method.
Fast Dynamic Perfusion and Angiography Reconstruction using an end-to-end 3D Convolutional Neural Network
Sep 04, 2019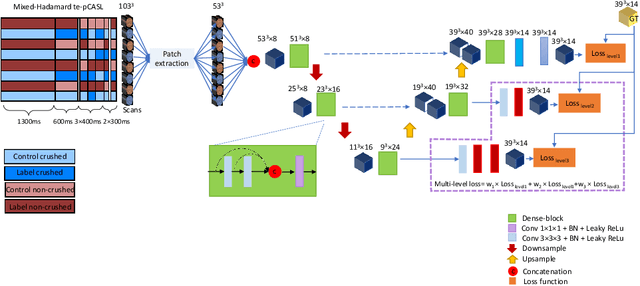
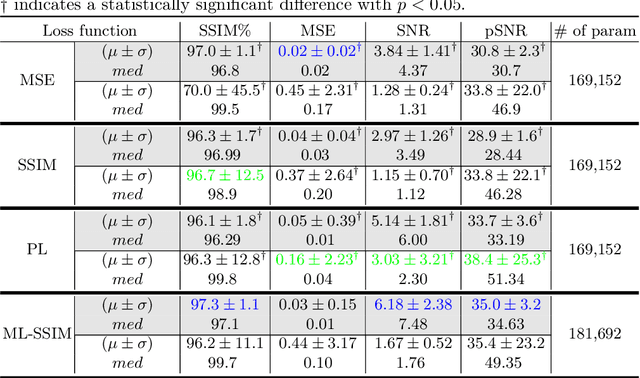

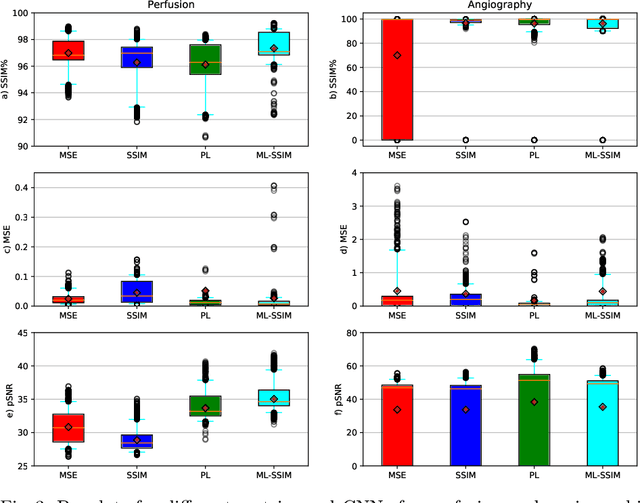
Hadamard time-encoded pseudo-continuous arterial spin labeling (te-pCASL) is a signal-to-noise ratio (SNR)-efficient MRI technique for acquiring dynamic pCASL signals that encodes the temporal information into the labeling according to a Hadamard matrix. In the decoding step, the contribution of each sub-bolus can be isolated resulting in dynamic perfusion scans. When acquiring te-ASL both with and without flow-crushing, the ASL-signal in the arteries can be isolated resulting in 4D-angiographic information. However, obtaining multi-timepoint perfusion and angiographic data requires two acquisitions. In this study, we propose a 3D Dense-Unet convolutional neural network with a multi-level loss function for reconstructing multi-timepoint perfusion and angiographic information from an interleaved $50\%$-sampled crushed and $50\%$-sampled non-crushed data, thereby negating the additional scan time. We present a framework to generate dynamic pCASL training and validation data, based on models of the intravascular and extravascular te-pCASL signals. The proposed network achieved SSIM values of $97.3 \pm 1.1$ and $96.2 \pm 11.1$ respectively for 4D perfusion and angiographic data reconstruction for 313 test data-sets.
3D Convolutional Neural Networks Image Registration Based on Efficient Supervised Learning from Artificial Deformations
Aug 27, 2019
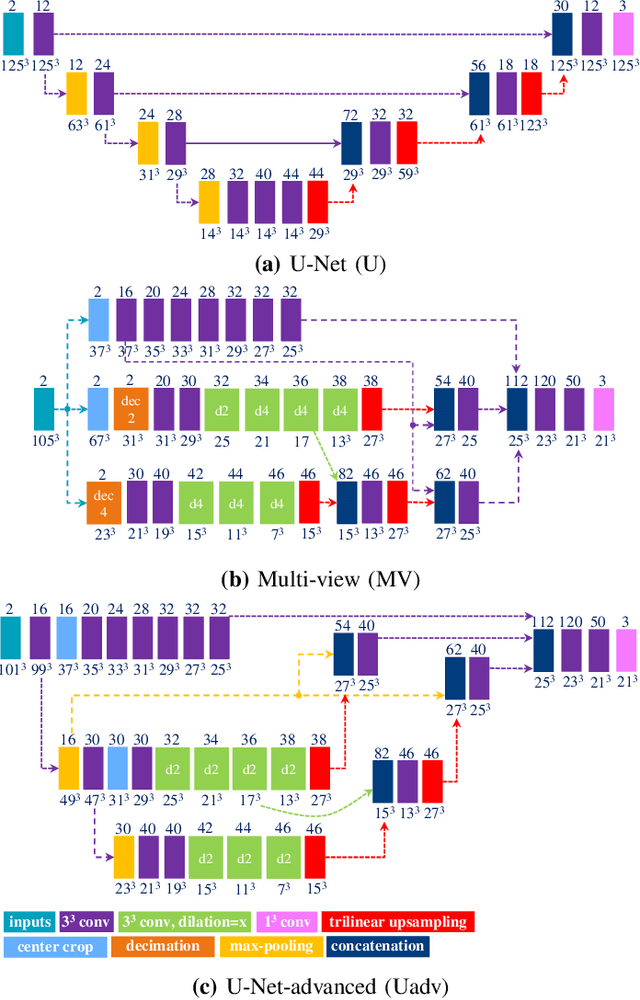
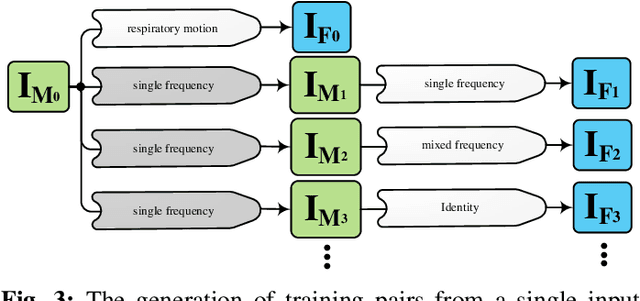

We propose a supervised nonrigid image registration method, trained using artificial displacement vector fields (DVF), for which we propose and compare three network architectures. The artificial DVFs allow training in a fully supervised and voxel-wise dense manner, but without the cost usually associated with the creation of densely labeled data. We propose a scheme to artificially generate DVFs, and for chest CT registration augment these with simulated respiratory motion. The proposed architectures are embedded in a multi-stage approach, to increase the capture range of the proposed networks in order to more accurately predict larger displacements. The proposed method, RegNet, is evaluated on multiple databases of chest CT scans and achieved a target registration error of 2.32 $\pm$ 5.33 mm and 1.86 $\pm$ 2.12 mm on SPREAD and DIR-Lab-4DCT studies, respectively. The average inference time of RegNet with two stages is about 2.2 s.
A Fully Bayesian Infinite Generative Model for Dynamic Texture Segmentation
Jan 13, 2019

Generative dynamic texture models (GDTMs) are widely used for dynamic texture (DT) segmentation in the video sequences. GDTMs represent DTs as a set of linear dynamical systems (LDSs). A major limitation of these models concerns the automatic selection of a proper number of DTs. Dirichlet process mixture (DPM) models which have appeared recently as the cornerstone of the non-parametric Bayesian statistics, is an optimistic candidate toward resolving this issue. Under this motivation to resolve the aforementioned drawback, we propose a novel non-parametric fully Bayesian approach for DT segmentation, formulated on the basis of a joint DPM and GDTM construction. This interaction causes the algorithm to overcome the problem of automatic segmentation properly. We derive the Variational Bayesian Expectation-Maximization (VBEM) inference for the proposed model. Moreover, in the E-step of inference, we apply Rauch-Tung-Striebel smoother (RTSS) algorithm on Variational Bayesian LDSs. Ultimately, experiments on different video sequences are performed. Experiment results indicate that the proposed algorithm outperforms the previous methods in efficiency and accuracy noticeably.
A Novel Motion Detection Method Resistant to Severe Illumination Changes
Mar 15, 2018

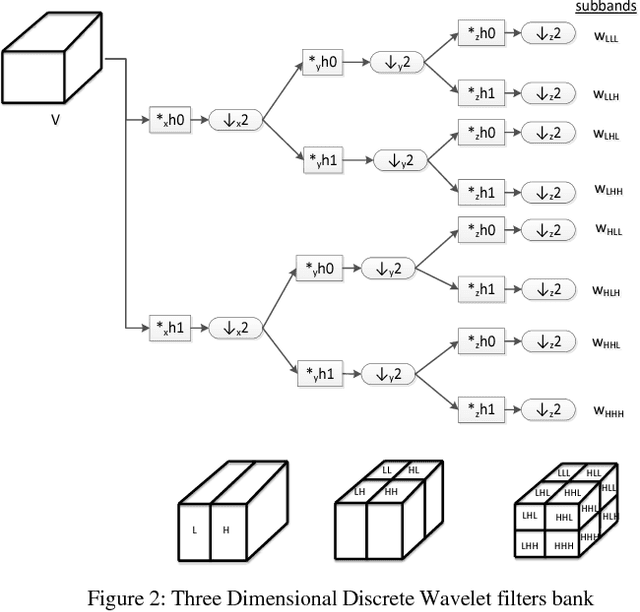
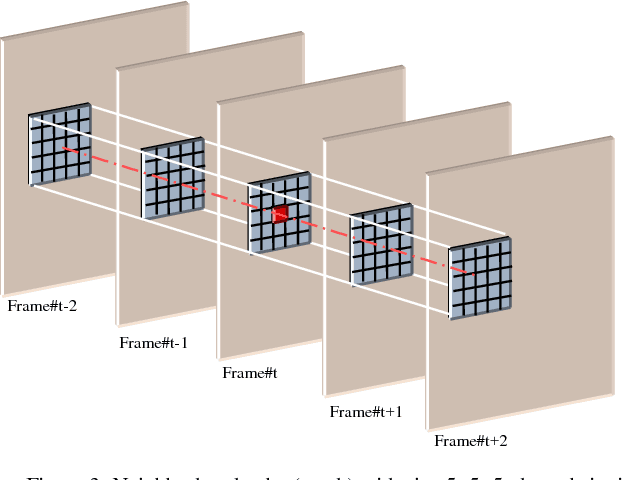
Recently, there has been a considerable attention given to the motion detection problem due to the explosive growth of its applications in video analysis and surveillance systems. While the previous approaches can produce good results, an accurate detection of motion remains a challenging task due to the difficulties raised by illumination variations, occlusion, camouflage, burst physical motion, dynamic texture, and environmental changes such as those on climate changes, sunlight changes during a day, etc. In this paper, we propose a novel per-pixel motion descriptor for both motion detection and dynamic texture segmentation which outperforms the current methods in the literature particularly in severe scenarios. The proposed descriptor is based on two complementary three-dimensional-discrete wavelet transform (3D-DWT) and three-dimensional wavelet leader. In this approach, a feature vector is extracted for each pixel by applying a novel three dimensional wavelet-based motion descriptor. Then, the extracted features are clustered by a clustering method such as well-known k-means algorithm or Gaussian Mixture Model (GMM). The experimental results demonstrate the effectiveness of our proposed method compared to the other motion detection approaches from the literature. The application of the proposed method and additional experimental results for the different datasets are available at (http://dspl.ce.sharif.edu/motiondetector.html).
Gender Recognition Based on Sift Features
Aug 06, 2011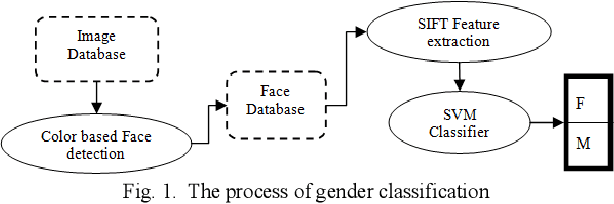


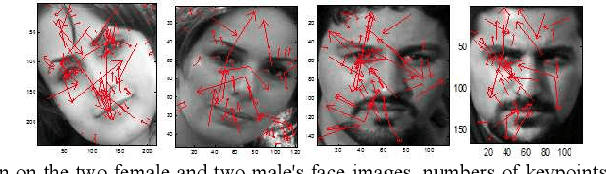
This paper proposes a robust approach for face detection and gender classification in color images. Previous researches about gender recognition suppose an expensive computational and time-consuming pre-processing step in order to alignment in which face images are aligned so that facial landmarks like eyes, nose, lips, chin are placed in uniform locations in image. In this paper, a novel technique based on mathematical analysis is represented in three stages that eliminates alignment step. First, a new color based face detection method is represented with a better result and more robustness in complex backgrounds. Next, the features which are invariant to affine transformations are extracted from each face using scale invariant feature transform (SIFT) method. To evaluate the performance of the proposed algorithm, experiments have been conducted by employing a SVM classifier on a database of face images which contains 500 images from distinct people with equal ratio of male and female.