 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMidpoint Generative Models
May 28, 2026We introduce Midpoint Generative Models (MGM), a principled framework for training one-step generative models. MGM is based on a simple symmetry of Flow Matching with linear interpolation: when the two endpoint distributions coincide, the corresponding drift field vanishes at the midpoint time, $t=1/2$. We show that the norm of this field defines a valid discrepancy between distributions, which we call the Midpoint Divergence. We extend this discrepancy beyond the midpoint by introducing randomly flipped interpolations and further generalize it by replacing deterministic linear Flow Matching interpolations with symmetric stochastic interpolants, yielding a generalized Midpoint Divergence. Finally, we derive a variational formulation of our generalized divergence, yielding a tractable objective for training a one-step generator. The resulting MGM algorithm offers an effective and theoretically grounded approach to generative modeling, achieving competitive performance against existing one-step generative modeling methods.
Unlocking the Duality between Flow and Field Matching
Feb 02, 2026Conditional Flow Matching (CFM) unifies conventional generative paradigms such as diffusion models and flow matching. Interaction Field Matching (IFM) is a newer framework that generalizes Electrostatic Field Matching (EFM) rooted in Poisson Flow Generative Models (PFGM). While both frameworks define generative dynamics, they start from different objects: CFM specifies a conditional probability path in data space, whereas IFM specifies a physics-inspired interaction field in an augmented data space. This raises a basic question: are CFM and IFM genuinely different, or are they two descriptions of the same underlying dynamics? We show that they coincide for a natural subclass of IFM that we call forward-only IFM. Specifically, we construct a bijection between CFM and forward-only IFM. We further show that general IFM is strictly more expressive: it includes EFM and other interaction fields that cannot be realized within the standard CFM formulation. Finally, we highlight how this duality can benefit both frameworks: it provides a probabilistic interpretation of forward-only IFM and yields novel, IFM-driven techniques for CFM.
Overclocking Electrostatic Generative Models
Sep 26, 2025



Electrostatic generative models such as PFGM++ have recently emerged as a powerful framework, achieving state-of-the-art performance in image synthesis. PFGM++ operates in an extended data space with auxiliary dimensionality $D$, recovering the diffusion model framework as $D\to\infty$, while yielding superior empirical results for finite $D$. Like diffusion models, PFGM++ relies on expensive ODE simulations to generate samples, making it computationally costly. To address this, we propose Inverse Poisson Flow Matching (IPFM), a novel distillation framework that accelerates electrostatic generative models across all values of $D$. Our IPFM reformulates distillation as an inverse problem: learning a generator whose induced electrostatic field matches that of the teacher. We derive a tractable training objective for this problem and show that, as $D \to \infty$, our IPFM closely recovers Score Identity Distillation (SiD), a recent method for distilling diffusion models. Empirically, our IPFM produces distilled generators that achieve near-teacher or even superior sample quality using only a few function evaluations. Moreover, we observe that distillation converges faster for finite $D$ than in the $D \to \infty$ (diffusion) limit, which is consistent with prior findings that finite-$D$ PFGM++ models exhibit more favorable optimization and sampling properties.
HOTA: Hamiltonian framework for Optimal Transport Advection
Jul 23, 2025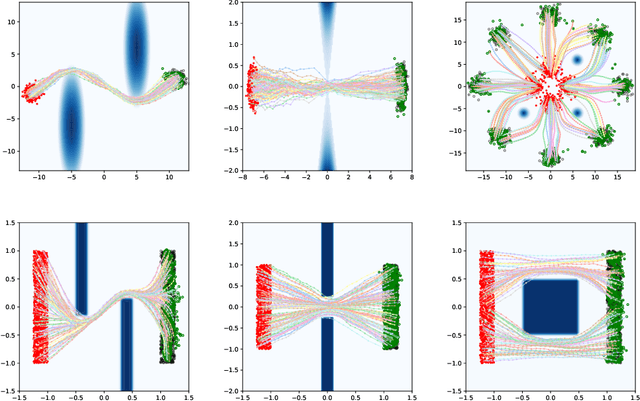
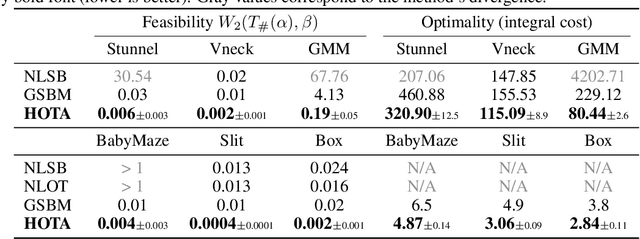
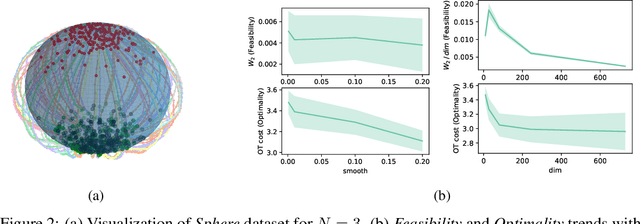
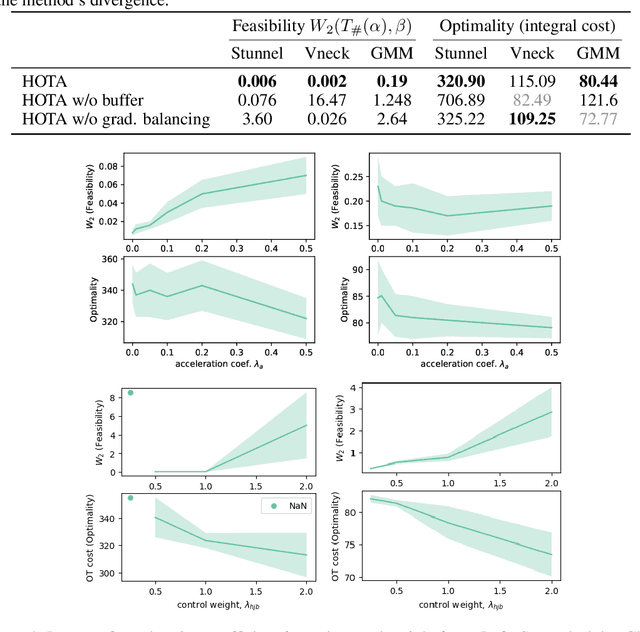
Optimal transport (OT) has become a natural framework for guiding the probability flows. Yet, the majority of recent generative models assume trivial geometry (e.g., Euclidean) and rely on strong density-estimation assumptions, yielding trajectories that do not respect the true principles of optimality in the underlying manifold. We present Hamiltonian Optimal Transport Advection (HOTA), a Hamilton-Jacobi-Bellman based method that tackles the dual dynamical OT problem explicitly through Kantorovich potentials, enabling efficient and scalable trajectory optimization. Our approach effectively evades the need for explicit density modeling, performing even when the cost functionals are non-smooth. Empirically, HOTA outperforms all baselines in standard benchmarks, as well as in custom datasets with non-differentiable costs, both in terms of feasibility and optimality.
Does Diffusion Beat GAN in Image Super Resolution?
May 27, 2024



There is a prevalent opinion in the recent literature that Diffusion-based models outperform GAN-based counterparts on the Image Super Resolution (ISR) problem. However, in most studies, Diffusion-based ISR models were trained longer and utilized larger networks than the GAN baselines. This raises the question of whether the superiority of Diffusion models is due to the Diffusion paradigm being better suited for the ISR task or if it is a consequence of the increased scale and computational resources used in contemporary studies. In our work, we compare Diffusion-based and GAN-based Super Resolution under controlled settings, where both approaches are matched in terms of architecture, model and dataset size, and computational budget. We show that a GAN-based model can achieve results comparable to a Diffusion-based model. Additionally, we explore the impact of design choices such as text conditioning and augmentation on the performance of ISR models, showcasing their effect on several downstream tasks. We will release the inference code and weights of our scaled GAN.
YaART: Yet Another ART Rendering Technology
Apr 08, 2024



In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Jul 26, 2023
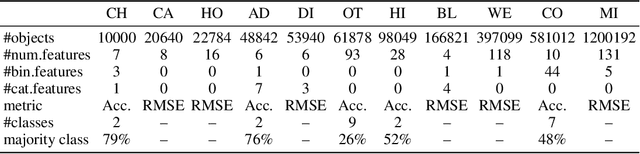
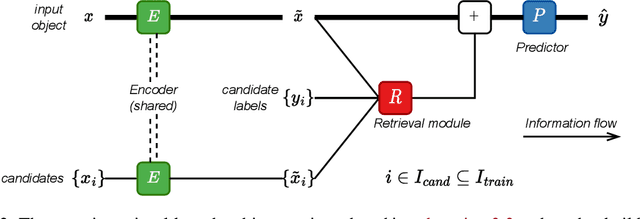

Deep learning (DL) models for tabular data problems are receiving increasingly more attention, while the algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution. Following the recent trends in other domains, such as natural language processing and computer vision, several retrieval-augmented tabular DL models have been recently proposed. For a given target object, a retrieval-based model retrieves other relevant objects, such as the nearest neighbors, from the available (training) data and uses their features or even labels to make a better prediction. However, we show that the existing retrieval-based tabular DL solutions provide only minor, if any, benefits over the properly tuned simple retrieval-free baselines. Thus, it remains unclear whether the retrieval-based approach is a worthy direction for tabular DL. In this work, we give a strong positive answer to this question. We start by incrementally augmenting a simple feed-forward architecture with an attention-like retrieval component similar to those of many (tabular) retrieval-based models. Then, we highlight several details of the attention mechanism that turn out to have a massive impact on the performance on tabular data problems, but that were not explored in prior work. As a result, we design TabR -- a simple retrieval-based tabular DL model which, on a set of public benchmarks, demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed ``GBDT-friendly'' benchmark (see the first figure).