 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Finetuning Tabular Foundation Models
Jun 11, 2025



Foundation models are an emerging research direction in tabular deep learning. Notably, TabPFNv2 recently claimed superior performance over traditional GBDT-based methods on small-scale datasets using an in-context learning paradigm, which does not adapt model parameters to target datasets. However, the optimal finetuning approach for adapting tabular foundational models, and how this adaptation reshapes their internal mechanisms, remains underexplored. While prior works studied finetuning for earlier foundational models, inconsistent findings and TabPFNv2's unique architecture necessitate fresh investigation. To address these questions, we first systematically evaluate various finetuning strategies on diverse datasets. Our findings establish full finetuning as the most practical solution for TabPFNv2 in terms of time-efficiency and effectiveness. We then investigate how finetuning alters TabPFNv2's inner mechanisms, drawing an analogy to retrieval-augmented models. We reveal that the success of finetuning stems from the fact that after gradient-based adaptation, the dot products of the query-representations of test objects and the key-representations of in-context training objects more accurately reflect their target similarity. This improved similarity allows finetuned TabPFNv2 to better approximate target dependency by appropriately weighting relevant in-context samples, improving the retrieval-based prediction logic. From the practical perspective, we managed to finetune TabPFNv2 on datasets with up to 50K objects, observing performance improvements on almost all tasks. More precisely, on academic datasets with I.I.D. splits, finetuning allows TabPFNv2 to achieve state-of-the-art results, while on datasets with gradual temporal shifts and rich feature sets, TabPFNv2 is less stable and prior methods remain better.
TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling
Oct 31, 2024
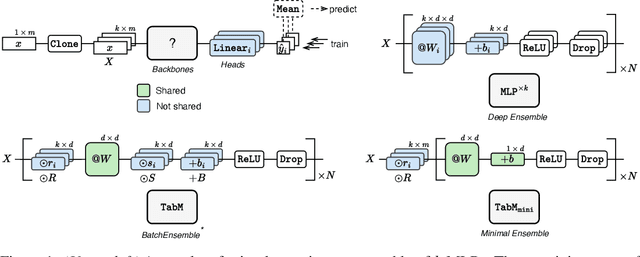
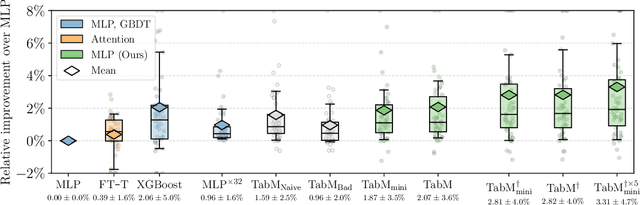

Deep learning architectures for supervised learning on tabular data range from simple multilayer perceptrons (MLP) to sophisticated Transformers and retrieval-augmented methods. This study highlights a major, yet so far overlooked opportunity for substantially improving tabular MLPs: namely, parameter-efficient ensembling -- a paradigm for implementing an ensemble of models as one model producing multiple predictions. We start by developing TabM -- a simple model based on MLP and our variations of BatchEnsemble (an existing technique). Then, we perform a large-scale evaluation of tabular DL architectures on public benchmarks in terms of both task performance and efficiency, which renders the landscape of tabular DL in a new light. Generally, we show that MLPs, including TabM, form a line of stronger and more practical models compared to attention- and retrieval-based architectures. In particular, we find that TabM demonstrates the best performance among tabular DL models. Lastly, we conduct an empirical analysis on the ensemble-like nature of TabM. For example, we observe that the multiple predictions of TabM are weak individually, but powerful collectively. Overall, our work brings an impactful technique to tabular DL, analyses its behaviour, and advances the performance-efficiency trade-off with TabM -- a simple and powerful baseline for researchers and practitioners.
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Jul 26, 2023
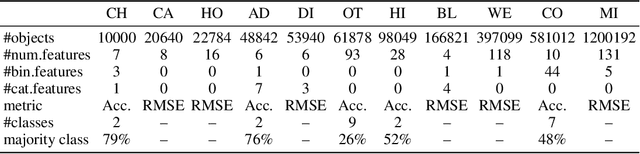
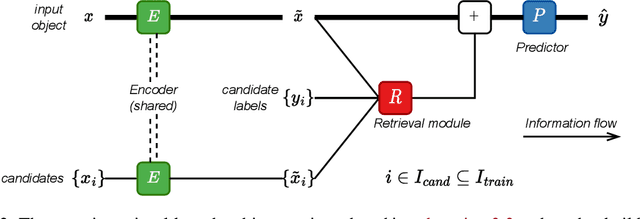

Deep learning (DL) models for tabular data problems are receiving increasingly more attention, while the algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution. Following the recent trends in other domains, such as natural language processing and computer vision, several retrieval-augmented tabular DL models have been recently proposed. For a given target object, a retrieval-based model retrieves other relevant objects, such as the nearest neighbors, from the available (training) data and uses their features or even labels to make a better prediction. However, we show that the existing retrieval-based tabular DL solutions provide only minor, if any, benefits over the properly tuned simple retrieval-free baselines. Thus, it remains unclear whether the retrieval-based approach is a worthy direction for tabular DL. In this work, we give a strong positive answer to this question. We start by incrementally augmenting a simple feed-forward architecture with an attention-like retrieval component similar to those of many (tabular) retrieval-based models. Then, we highlight several details of the attention mechanism that turn out to have a massive impact on the performance on tabular data problems, but that were not explored in prior work. As a result, we design TabR -- a simple retrieval-based tabular DL model which, on a set of public benchmarks, demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed ``GBDT-friendly'' benchmark (see the first figure).
TabDDPM: Modelling Tabular Data with Diffusion Models
Sep 30, 2022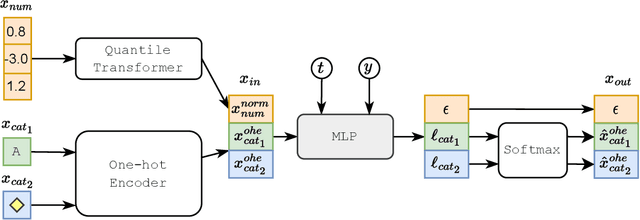
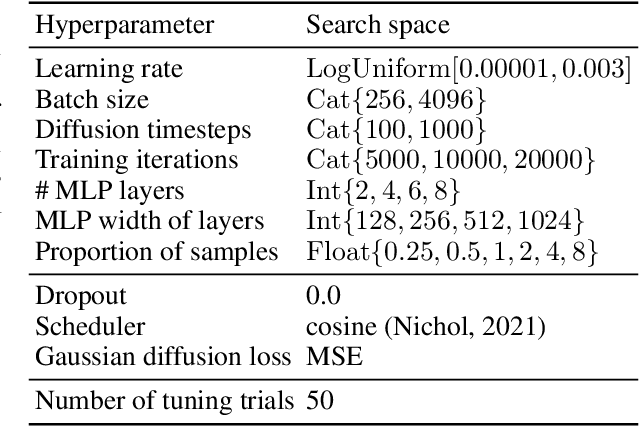
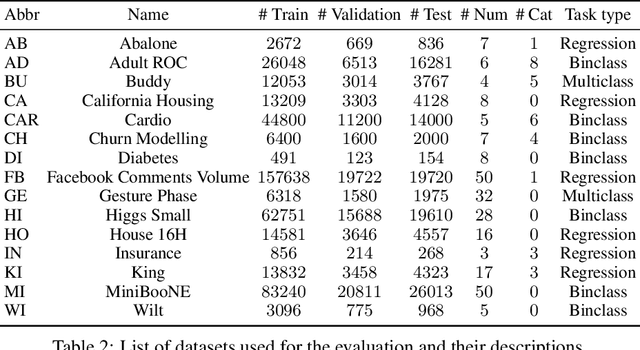
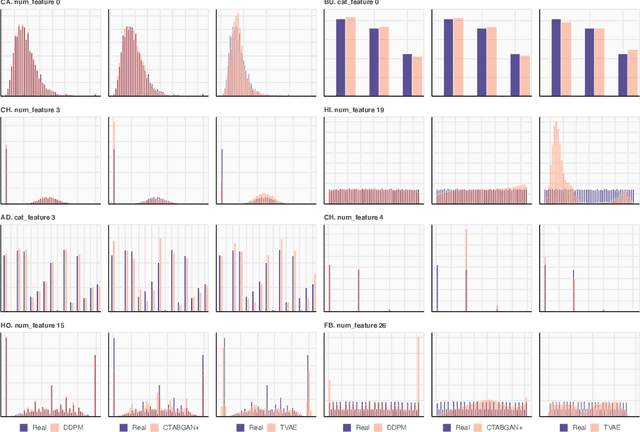
Denoising diffusion probabilistic models are currently becoming the leading paradigm of generative modeling for many important data modalities. Being the most prevalent in the computer vision community, diffusion models have also recently gained some attention in other domains, including speech, NLP, and graph-like data. In this work, we investigate if the framework of diffusion models can be advantageous for general tabular problems, where datapoints are typically represented by vectors of heterogeneous features. The inherent heterogeneity of tabular data makes it quite challenging for accurate modeling, since the individual features can be of completely different nature, i.e., some of them can be continuous and some of them can be discrete. To address such data types, we introduce TabDDPM -- a diffusion model that can be universally applied to any tabular dataset and handles any type of feature. We extensively evaluate TabDDPM on a wide set of benchmarks and demonstrate its superiority over existing GAN/VAE alternatives, which is consistent with the advantage of diffusion models in other fields. Additionally, we show that TabDDPM is eligible for privacy-oriented setups, where the original datapoints cannot be publicly shared.