 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-Reptile: An Automatized Reptile-Based Meta-Learning Library for BCIs
Dec 27, 2024Meta-learning, i.e., "learning to learn", is a promising approach to enable efficient BCI classifier training with limited amounts of data. It can effectively use collections of in some way similar classification tasks, with rapid adaptation to new tasks where only minimal data are available. However, applying meta-learning to existing classifiers and BCI tasks requires significant effort. To address this issue, we propose EEG-Reptile, an automated library that leverages meta-learning to improve classification accuracy of neural networks in BCIs and other EEG-based applications. It utilizes the Reptile meta-learning algorithm to adapt neural network classifiers of EEG data to the inter-subject domain, allowing for more efficient fine-tuning for a new subject on a small amount of data. The proposed library incorporates an automated hyperparameter tuning module, a data management pipeline, and an implementation of the Reptile meta-learning algorithm. EEG-Reptile automation level allows using it without deep understanding of meta-learning. We demonstrate the effectiveness of EEG-Reptile on two benchmark datasets (BCI IV 2a, Lee2019 MI) and three neural network architectures (EEGNet, FBCNet, EEG-Inception). Our library achieved improvement in both zero-shot and few-shot learning scenarios compared to traditional transfer learning approaches.
Compression of Recurrent Neural Networks for Efficient Language Modeling
Feb 06, 2019
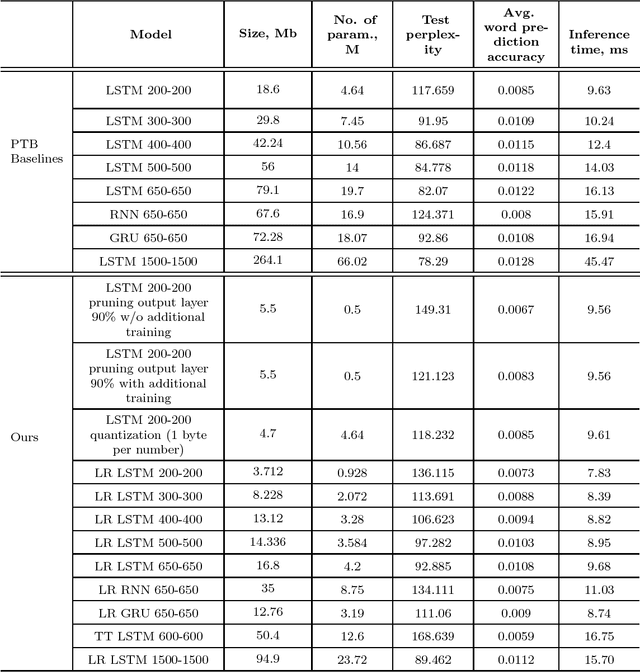
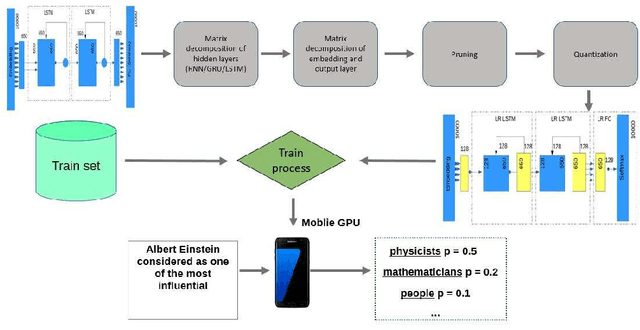
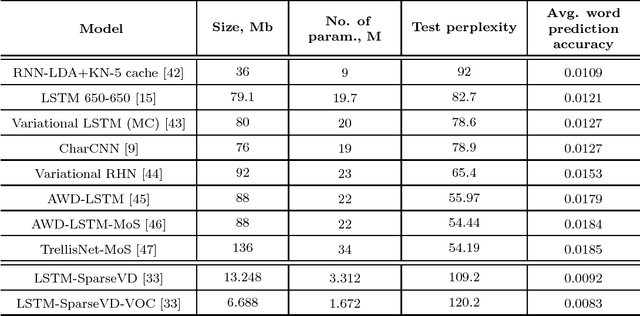
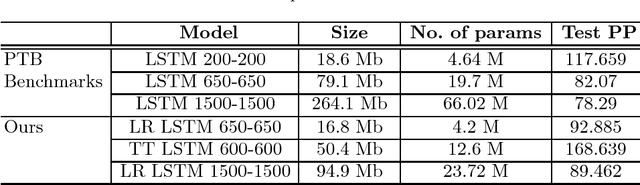
Recurrent neural networks have proved to be an effective method for statistical language modeling. However, in practice their memory and run-time complexity are usually too large to be implemented in real-time offline mobile applications. In this paper we consider several compression techniques for recurrent neural networks including Long-Short Term Memory models. We make particular attention to the high-dimensional output problem caused by the very large vocabulary size. We focus on effective compression methods in the context of their exploitation on devices: pruning, quantization, and matrix decomposition approaches (low-rank factorization and tensor train decomposition, in particular). For each model we investigate the trade-off between its size, suitability for fast inference and perplexity. We propose a general pipeline for applying the most suitable methods to compress recurrent neural networks for language modeling. It has been shown in the experimental study with the Penn Treebank (PTB) dataset that the most efficient results in terms of speed and compression-perplexity balance are obtained by matrix decomposition techniques.
Neural Networks Compression for Language Modeling
Aug 20, 2017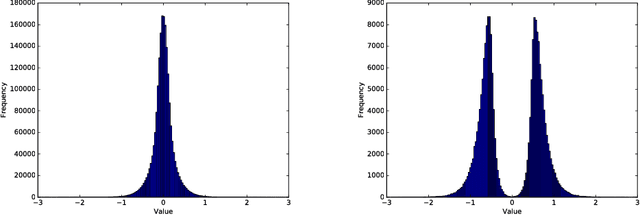
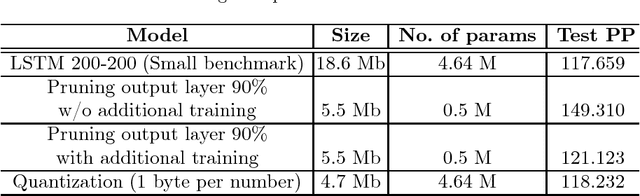
In this paper, we consider several compression techniques for the language modeling problem based on recurrent neural networks (RNNs). It is known that conventional RNNs, e.g, LSTM-based networks in language modeling, are characterized with either high space complexity or substantial inference time. This problem is especially crucial for mobile applications, in which the constant interaction with the remote server is inappropriate. By using the Penn Treebank (PTB) dataset we compare pruning, quantization, low-rank factorization, tensor train decomposition for LSTM networks in terms of model size and suitability for fast inference.