 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarity: an improved gradient method for producing quality visual counterfactual explanations
Nov 22, 2022



Visual counterfactual explanations identify modifications to an image that would change the prediction of a classifier. We propose a set of techniques based on generative models (VAE) and a classifier ensemble directly trained in the latent space, which all together, improve the quality of the gradient required to compute visual counterfactuals. These improvements lead to a novel classification model, Clarity, which produces realistic counterfactual explanations over all images. We also present several experiments that give insights on why these techniques lead to better quality results than those in the literature. The explanations produced are competitive with the state-of-the-art and emphasize the importance of selecting a meaningful input space for training.
Delta-Closure Structure for Studying Data Distribution
Oct 13, 2022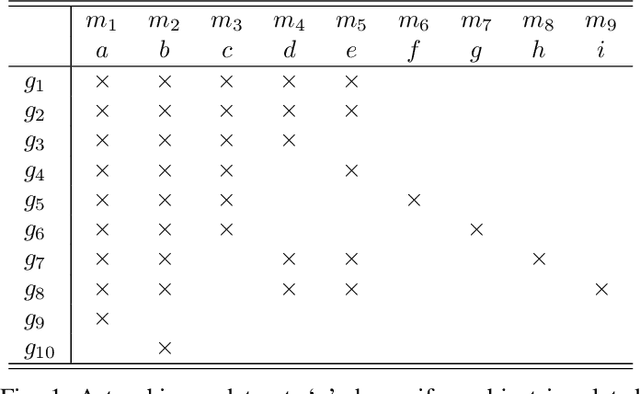
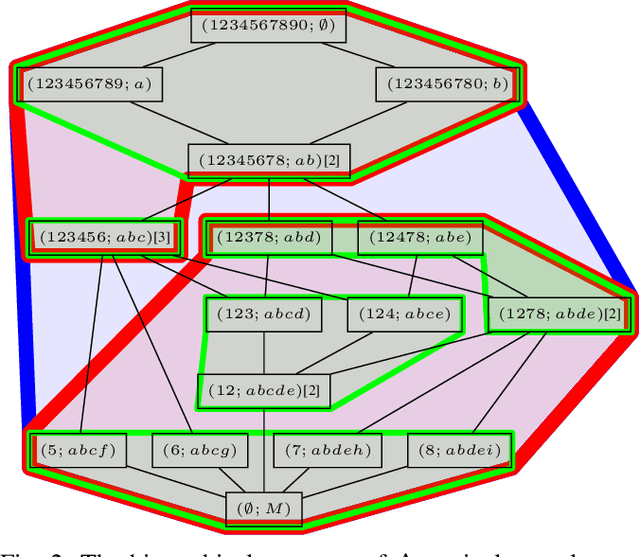
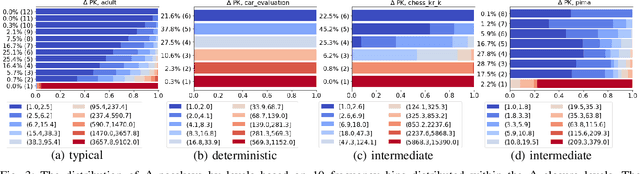
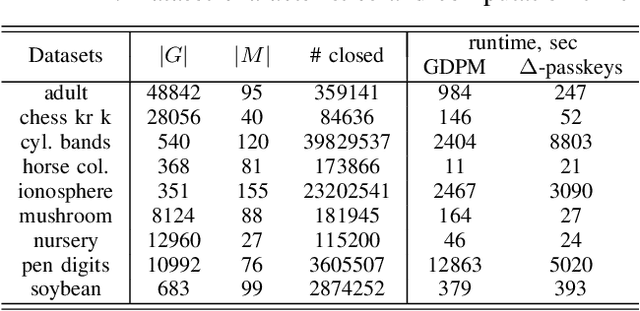
In this paper, we revisit pattern mining and study the distribution underlying a binary dataset thanks to the closure structure which is based on passkeys, i.e., minimum generators in equivalence classes robust to noise. We introduce $\Delta$-closedness, a generalization of the closure operator, where $\Delta$ measures how a closed set differs from its upper neighbors in the partial order induced by closure. A $\Delta$-class of equivalence includes minimum and maximum elements and allows us to characterize the distribution underlying the data. Moreover, the set of $\Delta$-classes of equivalence can be partitioned into the so-called $\Delta$-closure structure. In particular, a $\Delta$-class of equivalence with a high level demonstrates correlations among many attributes, which are supported by more observations when $\Delta$ is large. In the experiments, we study the $\Delta$-closure structure of several real-world datasets and show that this structure is very stable for large $\Delta$ and does not substantially depend on the data sampling used for the analysis.
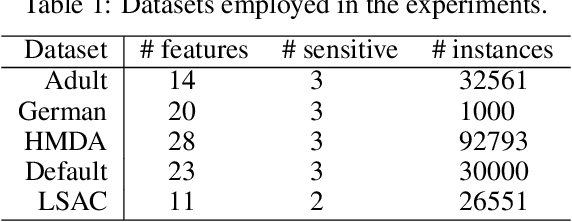
Reducing Unintended Bias of ML Models on Tabular and Textual Data
Aug 05, 2021



Unintended biases in machine learning (ML) models are among the major concerns that must be addressed to maintain public trust in ML. In this paper, we address process fairness of ML models that consists in reducing the dependence of models on sensitive features, without compromising their performance. We revisit the framework FixOut that is inspired in the approach "fairness through unawareness" to build fairer models. We introduce several improvements such as automating the choice of FixOut's parameters. Also, FixOut was originally proposed to improve fairness of ML models on tabular data. We also demonstrate the feasibility of FixOut's workflow for models on textual data. We present several experimental results that illustrate the fact that FixOut improves process fairness on different classification settings.
A Bayesian Convolutional Neural Network for Robust Galaxy Ellipticity Regression
Apr 20, 2021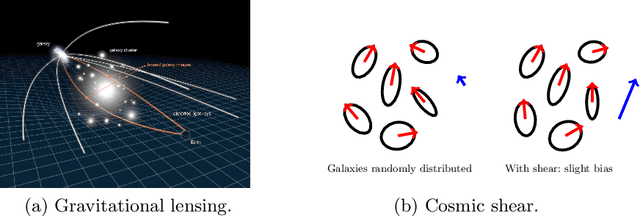
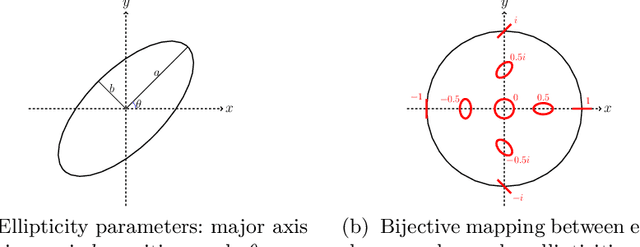
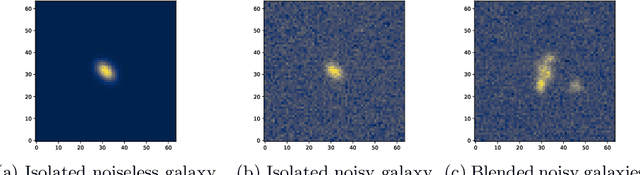
Cosmic shear estimation is an essential scientific goal for large galaxy surveys. It refers to the coherent distortion of distant galaxy images due to weak gravitational lensing along the line of sight. It can be used as a tracer of the matter distribution in the Universe. The unbiased estimation of the local value of the cosmic shear can be obtained via Bayesian analysis which relies on robust estimation of the galaxies ellipticity (shape) posterior distribution. This is not a simple problem as, among other things, the images may be corrupted with strong background noise. For current and coming surveys, another central issue in galaxy shape determination is the treatment of statistically dominant overlapping (blended) objects. We propose a Bayesian Convolutional Neural Network based on Monte-Carlo Dropout to reliably estimate the ellipticity of galaxies and the corresponding measurement uncertainties. We show that while a convolutional network can be trained to correctly estimate well calibrated aleatoric uncertainty, -- the uncertainty due to the presence of noise in the images -- it is unable to generate a trustworthy ellipticity distribution when exposed to previously unseen data (i.e. here, blended scenes). By introducing a Bayesian Neural Network, we show how to reliably estimate the posterior predictive distribution of ellipticities along with robust estimation of epistemic uncertainties. Experiments also show that epistemic uncertainty can detect inconsistent predictions due to unknown blended scenes.
A Bayesian Neural Network based on Dropout Regulation
Feb 03, 2021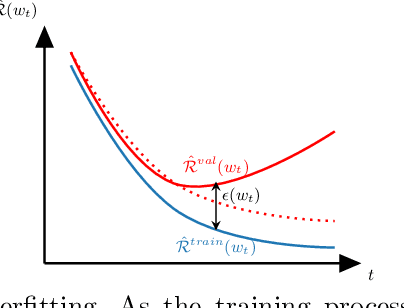
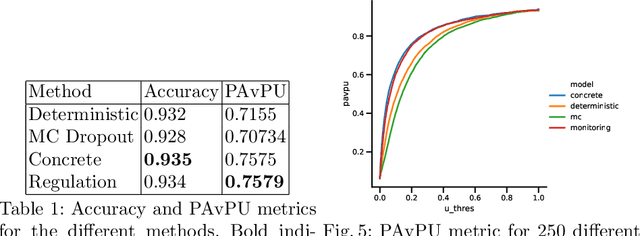
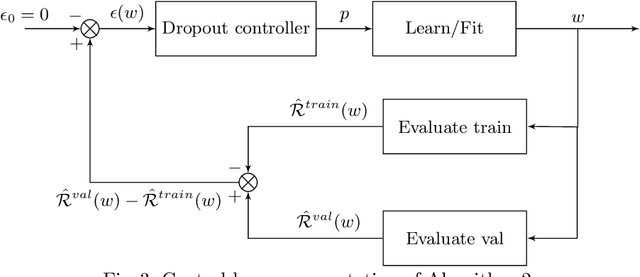
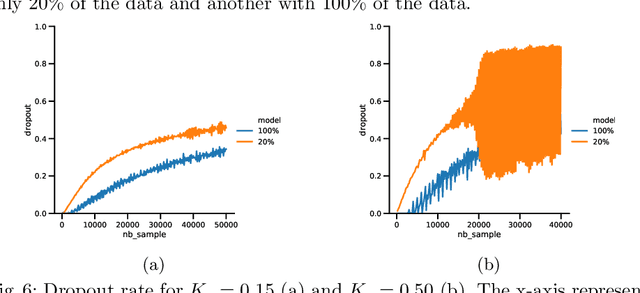
Bayesian Neural Networks (BNN) have recently emerged in the Deep Learning world for dealing with uncertainty estimation in classification tasks, and are used in many application domains such as astrophysics, autonomous driving...BNN assume a prior over the weights of a neural network instead of point estimates, enabling in this way the estimation of both aleatoric and epistemic uncertainty of the model prediction.Moreover, a particular type of BNN, namely MC Dropout, assumes a Bernoulli distribution on the weights by using Dropout.Several attempts to optimize the dropout rate exist, e.g. using a variational approach.In this paper, we present a new method called "Dropout Regulation" (DR), which consists of automatically adjusting the dropout rate during training using a controller as used in automation.DR allows for a precise estimation of the uncertainty which is comparable to the state-of-the-art while remaining simple to implement.
Mint: MDL-based approach for Mining INTeresting Numerical Pattern Sets
Nov 30, 2020



Pattern mining is well established in data mining research, especially for mining binary datasets. Surprisingly, there is much less work about numerical pattern mining and this research area remains under-explored. In this paper, we propose Mint, an efficient MDL-based algorithm for mining numerical datasets. The MDL principle is a robust and reliable framework widely used in pattern mining, and as well in subgroup discovery. In Mint we reuse MDL for discovering useful patterns and returning a set of non-redundant overlapping patterns with well-defined boundaries and covering meaningful groups of objects. Mint is not alone in the category of numerical pattern miners based on MDL. In the experiments presented in the paper we show that Mint outperforms competitors among which Slim and RealKrimp.
Rediscovering alignment relations with Graph Convolutional Networks
Nov 11, 2020



Knowledge graphs are concurrently published and edited in the Web of data. Hence they may overlap, which makes key the task that consists in matching their content. This task encompasses the identification, within and across knowledge graphs, of nodes that are equivalent, more specific, or weakly related. In this article, we propose to match nodes of a knowledge graph by (i) learning node embeddings with Graph Convolutional Networks such that similar nodes have low distances in the embedding space, and (ii) clustering nodes based on their embeddings. We experimented this approach on a biomedical knowledge graph and particularly investigated the interplay between formal semantics and GCN models with the two following main focuses. Firstly, we applied various inference rules associated with domain knowledge, independently or combined, before learning node embeddings, and we measured the improvements in matching results. Secondly, while our GCN model is agnostic to the exact alignment relations (e.g., equivalence, weak similarity), we observed that distances in the embedding space are coherent with the "strength" of these different relations (e.g., smaller distances for equivalences), somehow corresponding to their rediscovery by the model.
Making ML models fairer through explanations: the case of LimeOut
Nov 01, 2020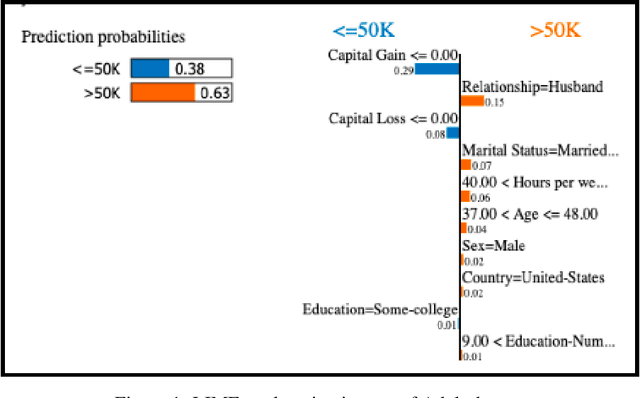
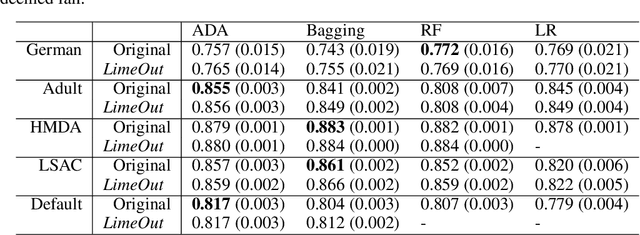

Algorithmic decisions are now being used on a daily basis, and based on Machine Learning (ML) processes that may be complex and biased. This raises several concerns given the critical impact that biased decisions may have on individuals or on society as a whole. Not only unfair outcomes affect human rights, they also undermine public trust in ML and AI. In this paper we address fairness issues of ML models based on decision outcomes, and we show how the simple idea of "feature dropout" followed by an "ensemble approach" can improve model fairness. To illustrate, we will revisit the case of "LimeOut" that was proposed to tackle "process fairness", which measures a model's reliance on sensitive or discriminatory features. Given a classifier, a dataset and a set of sensitive features, LimeOut first assesses whether the classifier is fair by checking its reliance on sensitive features using "Lime explanations". If deemed unfair, LimeOut then applies feature dropout to obtain a pool of classifiers. These are then combined into an ensemble classifier that was empirically shown to be less dependent on sensitive features without compromising the classifier's accuracy. We present different experiments on multiple datasets and several state of the art classifiers, which show that LimeOut's classifiers improve (or at least maintain) not only process fairness but also other fairness metrics such as individual and group fairness, equal opportunity, and demographic parity.
Discovery data topology with the closure structure. Theoretical and practical aspects
Oct 06, 2020
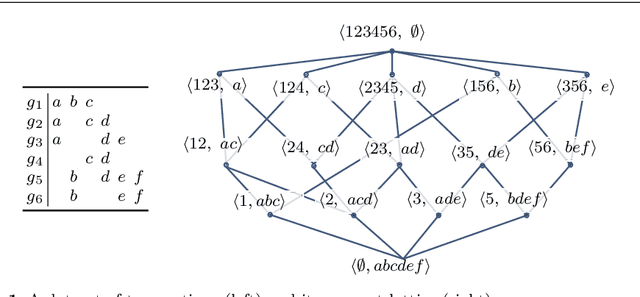


In this paper, we are revisiting pattern mining and especially itemset mining, which allows one to analyze binary datasets in searching for interesting and meaningful association rules and respective itemsets in an unsupervised way. While a summarization of a dataset based on a set of patterns does not provide a general and satisfying view over a dataset, we introduce a concise representation --the closure structure-- based on closed itemsets and their minimum generators, for capturing the intrinsic content of a dataset. The closure structure allows one to understand the topology of the dataset in the whole and the inherent complexity of the data. We propose a formalization of the closure structure in terms of Formal Concept Analysis, which is well adapted to study this data topology. We present and demonstrate theoretical results, and as well, practical results using the GDPM algorithm. GDPM is rather unique in its functionality as it returns a characterization of the topology of a dataset in terms of complexity levels, highlighting the diversity and the distribution of the itemsets. Finally, a series of experiments shows how GDPM can be practically used and what can be expected from the output.
Tackling scalability issues in mining path patterns from knowledge graphs: a preliminary study
Aug 07, 2020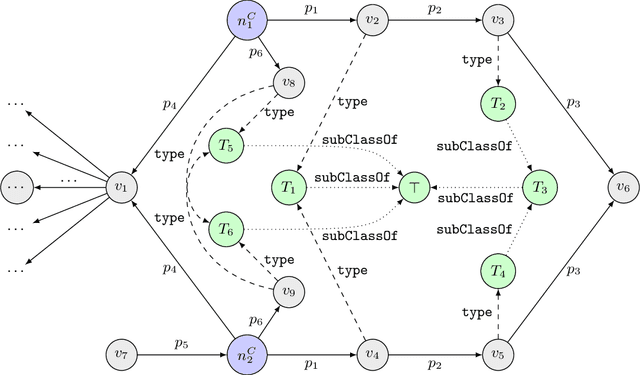

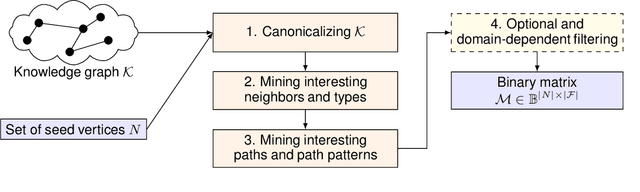

Features mined from knowledge graphs are widely used within multiple knowledge discovery tasks such as classification or fact-checking. Here, we consider a given set of vertices, called seed vertices, and focus on mining their associated neighboring vertices, paths, and, more generally, path patterns that involve classes of ontologies linked with knowledge graphs. Due to the combinatorial nature and the increasing size of real-world knowledge graphs, the task of mining these patterns immediately entails scalability issues. In this paper, we address these issues by proposing a pattern mining approach that relies on a set of constraints (e.g., support or degree thresholds) and the monotonicity property. As our motivation comes from the mining of real-world knowledge graphs, we illustrate our approach with PGxLOD, a biomedical knowledge graph.