 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
Multilingual Topic Classification in X: Dataset and Analysis
Oct 04, 2024



In the dynamic realm of social media, diverse topics are discussed daily, transcending linguistic boundaries. However, the complexities of understanding and categorising this content across various languages remain an important challenge with traditional techniques like topic modelling often struggling to accommodate this multilingual diversity. In this paper, we introduce X-Topic, a multilingual dataset featuring content in four distinct languages (English, Spanish, Japanese, and Greek), crafted for the purpose of tweet topic classification. Our dataset includes a wide range of topics, tailored for social media content, making it a valuable resource for scientists and professionals working on cross-linguistic analysis, the development of robust multilingual models, and computational scientists studying online dialogue. Finally, we leverage X-Topic to perform a comprehensive cross-linguistic and multilingual analysis, and compare the capabilities of current general- and domain-specific language models.
SuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research
Oct 23, 2023


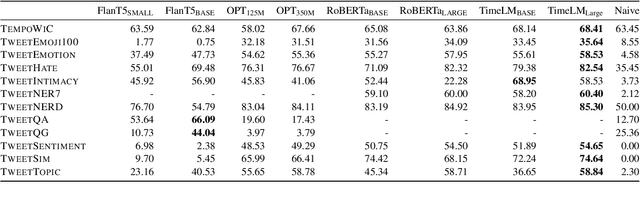
Despite its relevance, the maturity of NLP for social media pales in comparison with general-purpose models, metrics and benchmarks. This fragmented landscape makes it hard for the community to know, for instance, given a task, which is the best performing model and how it compares with others. To alleviate this issue, we introduce a unified benchmark for NLP evaluation in social media, SuperTweetEval, which includes a heterogeneous set of tasks and datasets combined, adapted and constructed from scratch. We benchmarked the performance of a wide range of models on SuperTweetEval and our results suggest that, despite the recent advances in language modelling, social media remains challenging.
RelBERT: Embedding Relations with Language Models
Oct 08, 2023Many applications need access to background knowledge about how different concepts and entities are related. Although Knowledge Graphs (KG) and Large Language Models (LLM) can address this need to some extent, KGs are inevitably incomplete and their relational schema is often too coarse-grained, while LLMs are inefficient and difficult to control. As an alternative, we propose to extract relation embeddings from relatively small language models. In particular, we show that masked language models such as RoBERTa can be straightforwardly fine-tuned for this purpose, using only a small amount of training data. The resulting model, which we call RelBERT, captures relational similarity in a surprisingly fine-grained way, allowing us to set a new state-of-the-art in analogy benchmarks. Crucially, RelBERT is capable of modelling relations that go well beyond what the model has seen during training. For instance, we obtained strong results on relations between named entities with a model that was only trained on lexical relations between concepts, and we observed that RelBERT can recognise morphological analogies despite not being trained on such examples. Overall, we find that RelBERT significantly outperforms strategies based on prompting language models that are several orders of magnitude larger, including recent GPT-based models and open source models.
A Practical Toolkit for Multilingual Question and Answer Generation
May 27, 2023Generating questions along with associated answers from a text has applications in several domains, such as creating reading comprehension tests for students, or improving document search by providing auxiliary questions and answers based on the query. Training models for question and answer generation (QAG) is not straightforward due to the expected structured output (i.e. a list of question and answer pairs), as it requires more than generating a single sentence. This results in a small number of publicly accessible QAG models. In this paper, we introduce AutoQG, an online service for multilingual QAG, along with lmqg, an all-in-one Python package for model fine-tuning, generation, and evaluation. We also release QAG models in eight languages fine-tuned on a few variants of pre-trained encoder-decoder language models, which can be used online via AutoQG or locally via lmqg. With these resources, practitioners of any level can benefit from a toolkit that includes a web interface for end users, and easy-to-use code for developers who require custom models or fine-grained controls for generation.
An Empirical Comparison of LM-based Question and Answer Generation Methods
May 26, 2023



Question and answer generation (QAG) consists of generating a set of question-answer pairs given a context (e.g. a paragraph). This task has a variety of applications, such as data augmentation for question answering (QA) models, information retrieval and education. In this paper, we establish baselines with three different QAG methodologies that leverage sequence-to-sequence language model (LM) fine-tuning. Experiments show that an end-to-end QAG model, which is computationally light at both training and inference times, is generally robust and outperforms other more convoluted approaches. However, there are differences depending on the underlying generative LM. Finally, our analysis shows that QA models fine-tuned solely on generated question-answer pairs can be competitive when compared to supervised QA models trained on human-labeled data.
A RelEntLess Benchmark for Modelling Graded Relations between Named Entities
May 24, 2023Relations such as "is influenced by", "is known for" or "is a competitor of" are inherently graded: we can rank entity pairs based on how well they satisfy these relations, but it is hard to draw a line between those pairs that satisfy them and those that do not. Such graded relations play a central role in many applications, yet they are typically not covered by existing Knowledge Graphs. In this paper, we consider the possibility of using Large Language Models (LLMs) to fill this gap. To this end, we introduce a new benchmark, in which entity pairs have to be ranked according to how much they satisfy a given graded relation. The task is formulated as a few-shot ranking problem, where models only have access to a description of the relation and five prototypical instances. We use the proposed benchmark to evaluate state-of-the-art relation embedding strategies as well as several recent LLMs, covering both publicly available LLMs and closed models such as GPT-4. Overall, we find a strong correlation between model size and performance, with smaller Language Models struggling to outperform a naive baseline. The results of the largest Flan-T5 and OPT models are remarkably strong, although a clear gap with human performance remains.
An Efficient Multilingual Language Model Compression through Vocabulary Trimming
May 24, 2023Multilingual language model (LM) have become a powerful tool in NLP especially for non-English languages. Nevertheless, model parameters of multilingual LMs remain large due to the larger embedding matrix of the vocabulary covering tokens in different languages. On the contrary, monolingual LMs can be trained in a target language with the language-specific vocabulary only, but this requires a large budget and availability of reliable corpora to achieve a high-quality LM from scratch. In this paper, we propose vocabulary-trimming (VT), a method to reduce a multilingual LM vocabulary to a target language by deleting irrelevant tokens from its vocabulary. In theory, VT can compress any existing multilingual LM to build monolingual LMs in any language covered by the multilingual LM. In our experiments, we show that VT can retain the original performance of the multilingual LM, while being smaller in size (in general around 50% of the original vocabulary size is enough) than the original multilingual LM. The evaluation is performed over four NLP tasks (two generative and two classification tasks) among four widely used multilingual LMs in seven languages. Finally, we show that this methodology can keep the best of both monolingual and multilingual worlds by keeping a small size as monolingual models without the need for specifically retraining them, and even limiting potentially harmful social biases.
Generative Language Models for Paragraph-Level Question Generation
Oct 08, 2022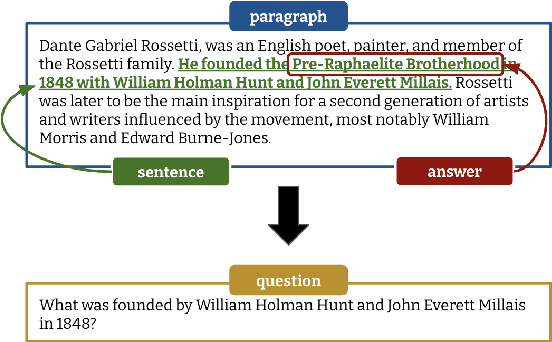
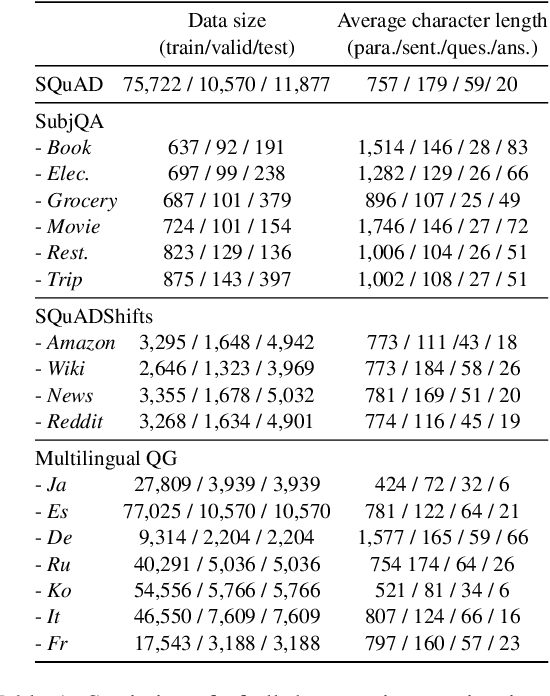
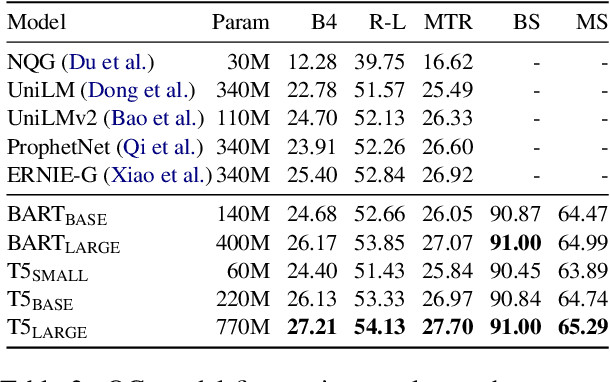
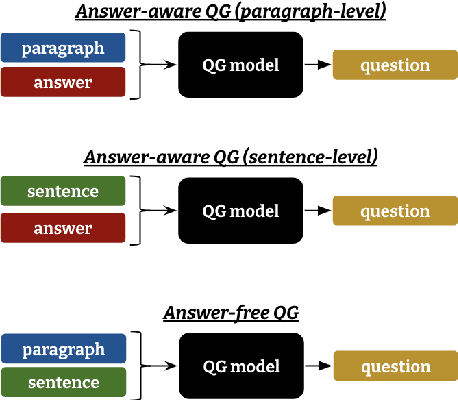
Powerful generative models have led to recent progress in question generation (QG). However, it is difficult to measure advances in QG research since there are no standardized resources that allow a uniform comparison among approaches. In this paper, we introduce QG-Bench, a multilingual and multidomain benchmark for QG that unifies existing question answering datasets by converting them to a standard QG setting. It includes general-purpose datasets such as SQuAD for English, datasets from ten domains and two styles, as well as datasets in eight different languages. Using QG-Bench as a reference, we perform an extensive analysis of the capabilities of language models for the task. First, we propose robust QG baselines based on fine-tuning generative language models. Then, we complement automatic evaluation based on standard metrics with an extensive manual evaluation, which in turn sheds light on the difficulty of evaluating QG models. Finally, we analyse both the domain adaptability of these models as well as the effectiveness of multilingual models in languages other than English. QG-Bench is released along with the fine-tuned models presented in the paper https://github.com/asahi417/lm-question-generation, which are also available as a demo https://autoqg.net/.
Named Entity Recognition in Twitter: A Dataset and Analysis on Short-Term Temporal Shifts
Oct 07, 2022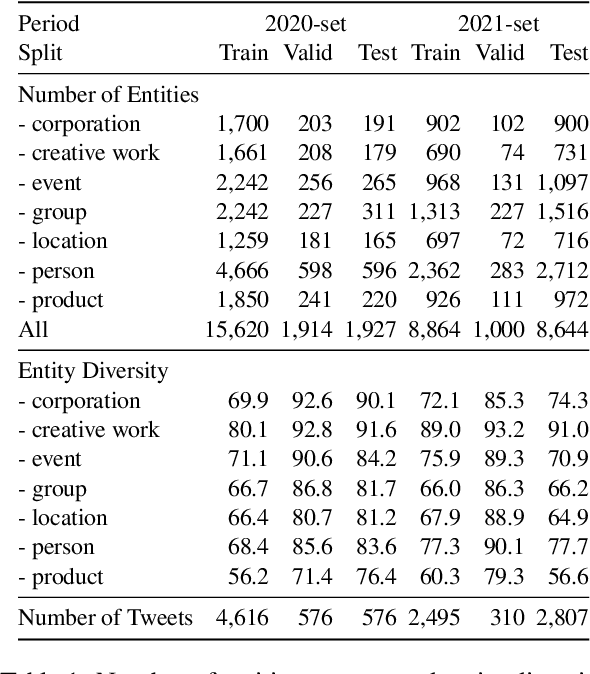
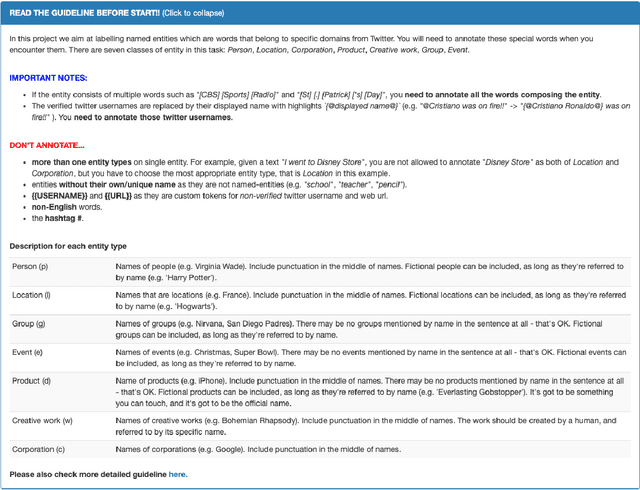
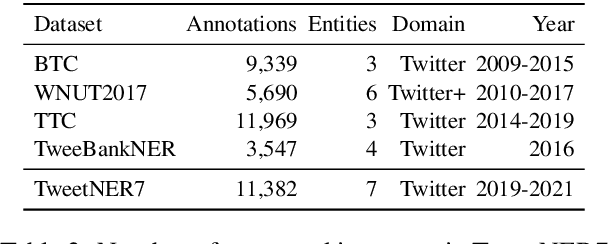
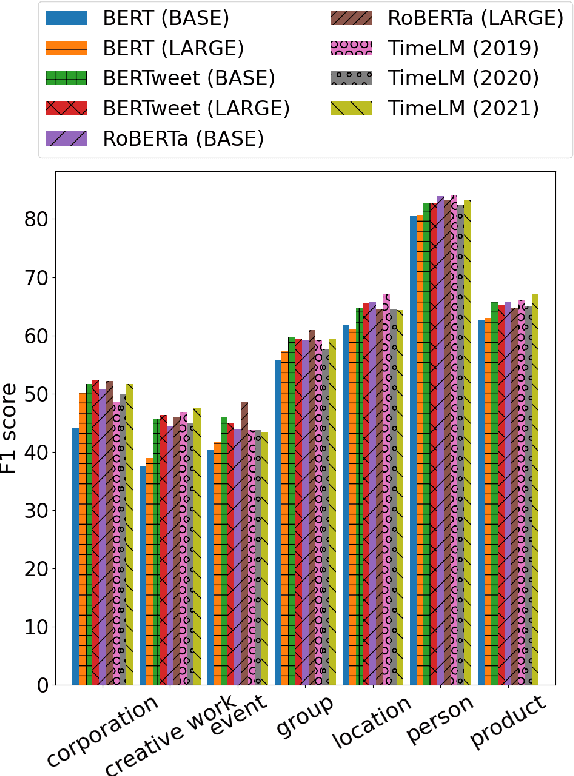
Recent progress in language model pre-training has led to important improvements in Named Entity Recognition (NER). Nonetheless, this progress has been mainly tested in well-formatted documents such as news, Wikipedia, or scientific articles. In social media the landscape is different, in which it adds another layer of complexity due to its noisy and dynamic nature. In this paper, we focus on NER in Twitter, one of the largest social media platforms, and construct a new NER dataset, TweetNER7, which contains seven entity types annotated over 11,382 tweets from September 2019 to August 2021. The dataset was constructed by carefully distributing the tweets over time and taking representative trends as a basis. Along with the dataset, we provide a set of language model baselines and perform an analysis on the language model performance on the task, especially analyzing the impact of different time periods. In particular, we focus on three important temporal aspects in our analysis: short-term degradation of NER models over time, strategies to fine-tune a language model over different periods, and self-labeling as an alternative to lack of recently-labeled data. TweetNER7 is released publicly (https://huggingface.co/datasets/tner/tweetner7) along with the models fine-tuned on it (NER models have been integrated into TweetNLP and can be found athttps://github.com/asahi417/tner/tree/master/examples/tweetner7_paper).