 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RelEntLess Benchmark for Modelling Graded Relations between Named Entities
May 24, 2023Relations such as "is influenced by", "is known for" or "is a competitor of" are inherently graded: we can rank entity pairs based on how well they satisfy these relations, but it is hard to draw a line between those pairs that satisfy them and those that do not. Such graded relations play a central role in many applications, yet they are typically not covered by existing Knowledge Graphs. In this paper, we consider the possibility of using Large Language Models (LLMs) to fill this gap. To this end, we introduce a new benchmark, in which entity pairs have to be ranked according to how much they satisfy a given graded relation. The task is formulated as a few-shot ranking problem, where models only have access to a description of the relation and five prototypical instances. We use the proposed benchmark to evaluate state-of-the-art relation embedding strategies as well as several recent LLMs, covering both publicly available LLMs and closed models such as GPT-4. Overall, we find a strong correlation between model size and performance, with smaller Language Models struggling to outperform a naive baseline. The results of the largest Flan-T5 and OPT models are remarkably strong, although a clear gap with human performance remains.
Politics and Virality in the Time of Twitter: A Large-Scale Cross-Party Sentiment Analysis in Greece, Spain and United Kingdom
Feb 01, 2022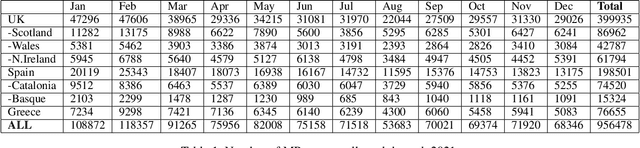
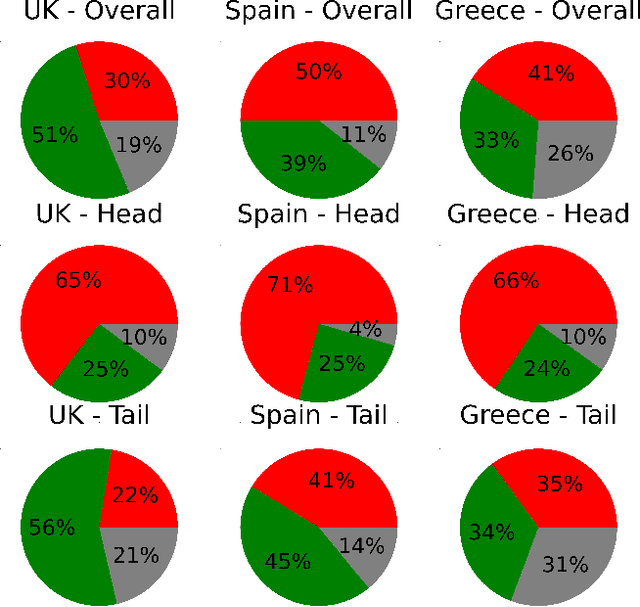

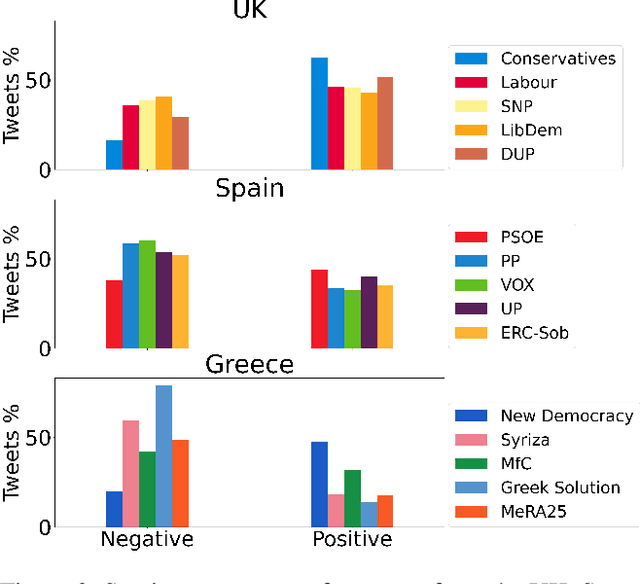
Social media has become extremely influential when it comes to policy making in modern societies especially in the western world (e.g., 48% of Europeans use social media every day or almost every day). Platforms such as Twitter allow users to follow politicians, thus making citizens more involved in political discussion. In the same vein, politicians use Twitter to express their opinions, debate among others on current topics and promote their political agenda aiming to influence voter behaviour. Previous studies have shown that tweets conveying negative sentiment are likely to be retweeted more frequently. In this paper, we attempt to analyse tweets from politicians from different countries and explore if their tweets follow the same trend. Utilising state-of-the-art pre-trained language models we performed sentiment analysis on multilingual tweets collected from members of parliament of Greece, Spain and United Kingdom, including devolved administrations. We achieved this by systematically exploring and analysing the differences between influential and less popular tweets. Our analysis indicates that politicians' negatively charged tweets spread more widely, especially in more recent times, and highlights interesting trends in the intersection of sentiment and popularity.
Modelling General Properties of Nouns by Selectively Averaging Contextualised Embeddings
Dec 04, 2020
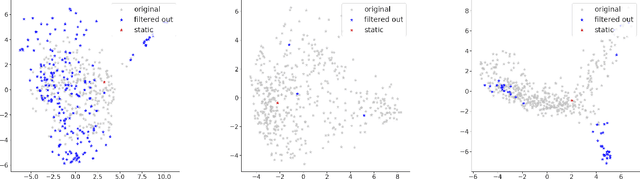

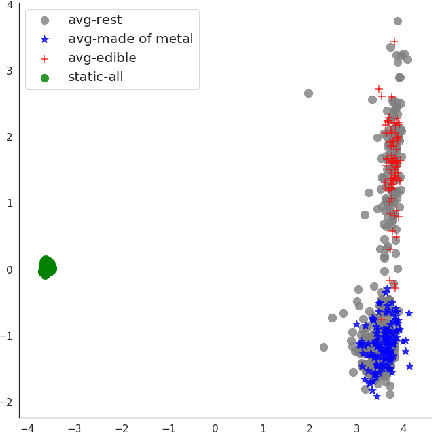
While the success of pre-trained language models has largely eliminated the need for high-quality static word vectors in many NLP applications, static word vectors continue to play an important role in tasks where word meaning needs to be modelled in the absence of linguistic context. In this paper, we explore how the contextualised embeddings predicted by BERT can be used to produce high-quality word vectors for such domains, in particular related to knowledge base completion, where our focus is on capturing the semantic properties of nouns. We find that a simple strategy of averaging the contextualised embeddings of masked word mentions leads to vectors that outperform the static word vectors learned by BERT, as well as those from standard word embedding models, in property induction tasks. We notice in particular that masking target words is critical to achieve this strong performance, as the resulting vectors focus less on idiosyncratic properties and more on general semantic properties. Inspired by this view, we propose a filtering strategy which is aimed at removing the most idiosyncratic mention vectors, allowing us to obtain further performance gains in property induction.
Towards Preemptive Detection of Depression and Anxiety in Twitter
Nov 10, 2020
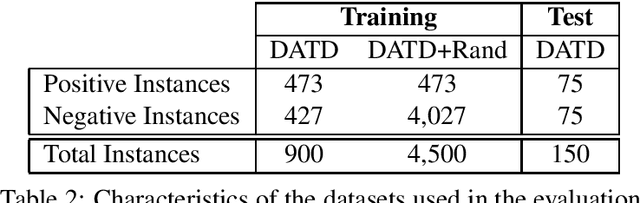
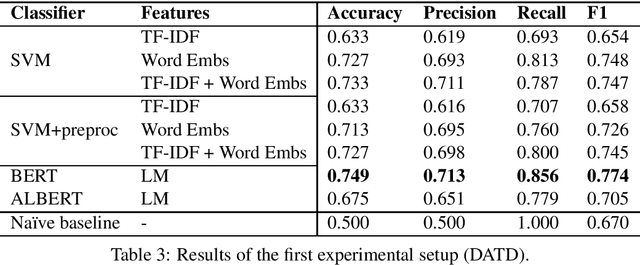
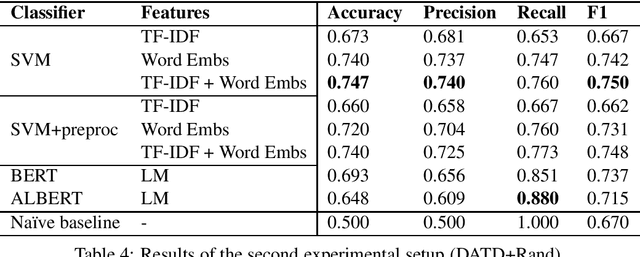
Depression and anxiety are psychiatric disorders that are observed in many areas of everyday life. For example, these disorders manifest themselves somewhat frequently in texts written by nondiagnosed users in social media. However, detecting users with these conditions is not a straightforward task as they may not explicitly talk about their mental state, and if they do, contextual cues such as immediacy must be taken into account. When available, linguistic flags pointing to probable anxiety or depression could be used by medical experts to write better guidelines and treatments. In this paper, we develop a dataset designed to foster research in depression and anxiety detection in Twitter, framing the detection task as a binary tweet classification problem. We then apply state-of-the-art classification models to this dataset, providing a competitive set of baselines alongside qualitative error analysis. Our results show that language models perform reasonably well, and better than more traditional baselines. Nonetheless, there is clear room for improvement, particularly with unbalanced training sets and in cases where seemingly obvious linguistic cues (keywords) are used counter-intuitively.