 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling General Properties of Nouns by Selectively Averaging Contextualised Embeddings
Paper and Code

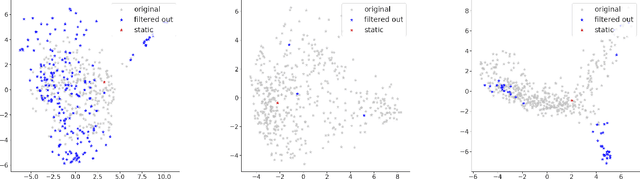

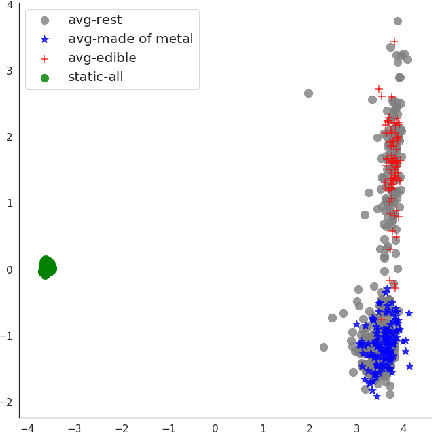
While the success of pre-trained language models has largely eliminated the need for high-quality static word vectors in many NLP applications, static word vectors continue to play an important role in tasks where word meaning needs to be modelled in the absence of linguistic context. In this paper, we explore how the contextualised embeddings predicted by BERT can be used to produce high-quality word vectors for such domains, in particular related to knowledge base completion, where our focus is on capturing the semantic properties of nouns. We find that a simple strategy of averaging the contextualised embeddings of masked word mentions leads to vectors that outperform the static word vectors learned by BERT, as well as those from standard word embedding models, in property induction tasks. We notice in particular that masking target words is critical to achieve this strong performance, as the resulting vectors focus less on idiosyncratic properties and more on general semantic properties. Inspired by this view, we propose a filtering strategy which is aimed at removing the most idiosyncratic mention vectors, allowing us to obtain further performance gains in property induction.