 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers and Transfer Learning for Improving Portuguese Semantic Role Labeling
Jan 06, 2021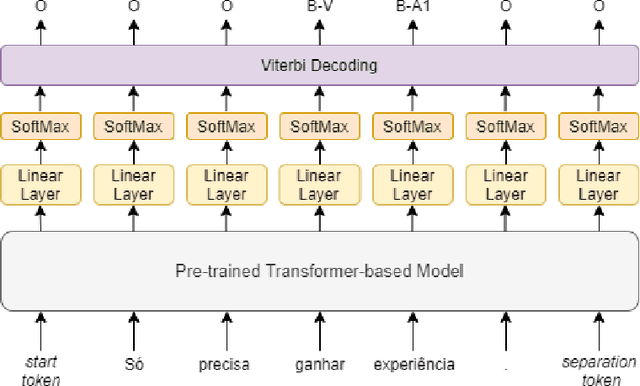



Semantic Role Labeling (SRL) is a core Natural Language Processing task. For English, recent methods based on Transformer models have allowed for major improvements over the previous state of the art. However, for low resource languages, and in particular for Portuguese, currently available SRL models are hindered by scarce training data. In this paper, we explore a model architecture with only a pre-trained BERT-based model, a linear layer, softmax and Viterbi decoding. We substantially improve the state of the art performance in Portuguese by over 15$F_1$. Additionally, we improve SRL results in Portuguese corpora by exploiting cross-lingual transfer learning using multilingual pre-trained models (XLM-R), and transfer learning from dependency parsing in Portuguese. We evaluate the various proposed approaches empirically and as result we present an heuristic that supports the choice of the most appropriate model considering the available resources.