 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Commonsense Knowledge in Pre-trained Language Models with Sense-level Precision and Expanded Vocabulary
Oct 12, 2022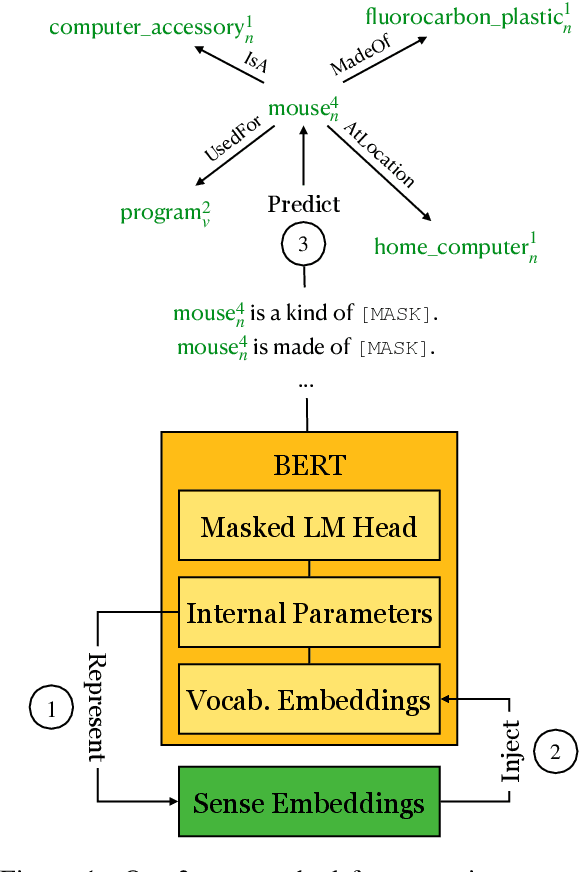
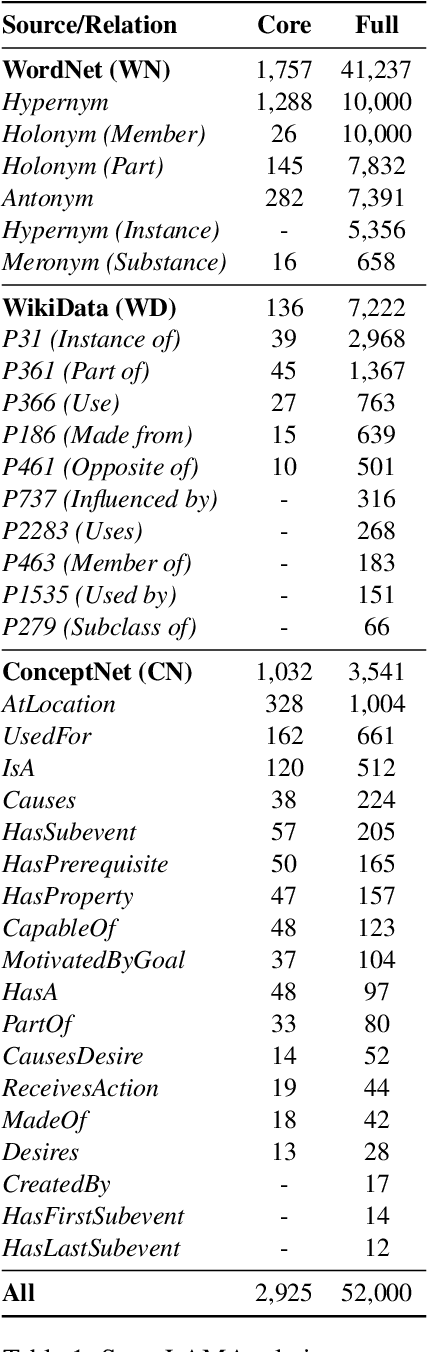
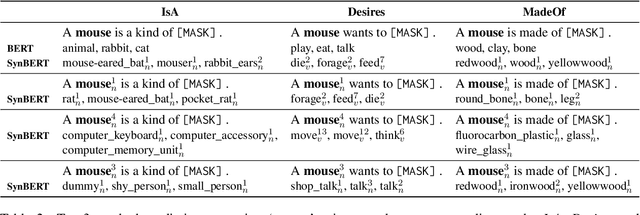
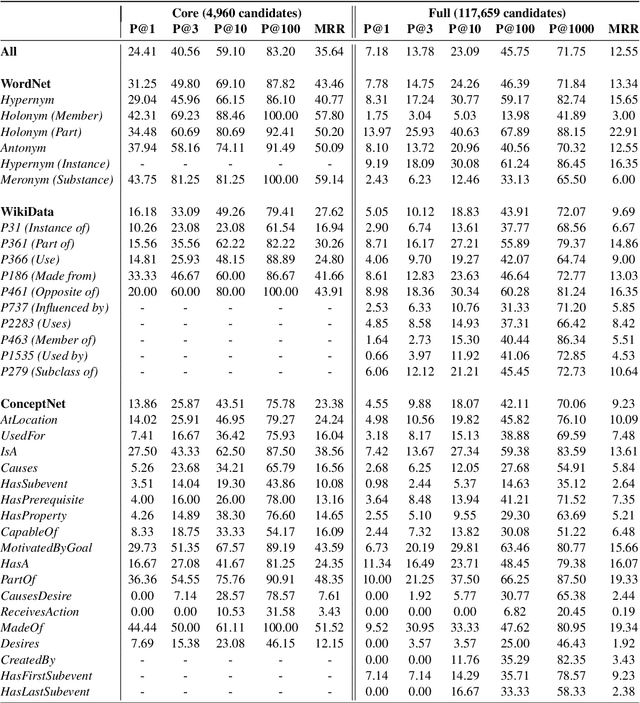
Progress on commonsense reasoning is usually measured from performance improvements on Question Answering tasks designed to require commonsense knowledge. However, fine-tuning large Language Models (LMs) on these specific tasks does not directly evaluate commonsense learned during pre-training. The most direct assessments of commonsense knowledge in pre-trained LMs are arguably cloze-style tasks targeting commonsense assertions (e.g., A pen is used for [MASK].). However, this approach is restricted by the LM's vocabulary available for masked predictions, and its precision is subject to the context provided by the assertion. In this work, we present a method for enriching LMs with a grounded sense inventory (i.e., WordNet) available at the vocabulary level, without further training. This modification augments the prediction space of cloze-style prompts to the size of a large ontology while enabling finer-grained (sense-level) queries and predictions. In order to evaluate LMs with higher precision, we propose SenseLAMA, a cloze-style task featuring verbalized relations from disambiguated triples sourced from WordNet, WikiData, and ConceptNet. Applying our method to BERT, producing a WordNet-enriched version named SynBERT, we find that LMs can learn non-trivial commonsense knowledge from self-supervision, covering numerous relations, and more effectively than comparable similarity-based approaches.
Proceedings of the 4th Workshop on Online Recommender Systems and User Modeling -- ORSUM 2021
Jan 17, 2022Modern online services continuously generate data at very fast rates. This continuous flow of data encompasses content - e.g., posts, news, products, comments -, but also user feedback - e.g., ratings, views, reads, clicks -, together with context data - user device, spatial or temporal data, user task or activity, weather. This can be overwhelming for systems and algorithms designed to train in batches, given the continuous and potentially fast change of content, context and user preferences or intents. Therefore, it is important to investigate online methods able to transparently adapt to the inherent dynamics of online services. Incremental models that learn from data streams are gaining attention in the recommender systems community, given their natural ability to deal with the continuous flows of data generated in dynamic, complex environments. User modeling and personalization can particularly benefit from algorithms capable of maintaining models incrementally and online. The objective of this workshop is to foster contributions and bring together a growing community of researchers and practitioners interested in online, adaptive approaches to user modeling, recommendation and personalization, and their implications regarding multiple dimensions, such as evaluation, reproducibility, privacy and explainability.
LMMS Reloaded: Transformer-based Sense Embeddings for Disambiguation and Beyond
May 26, 2021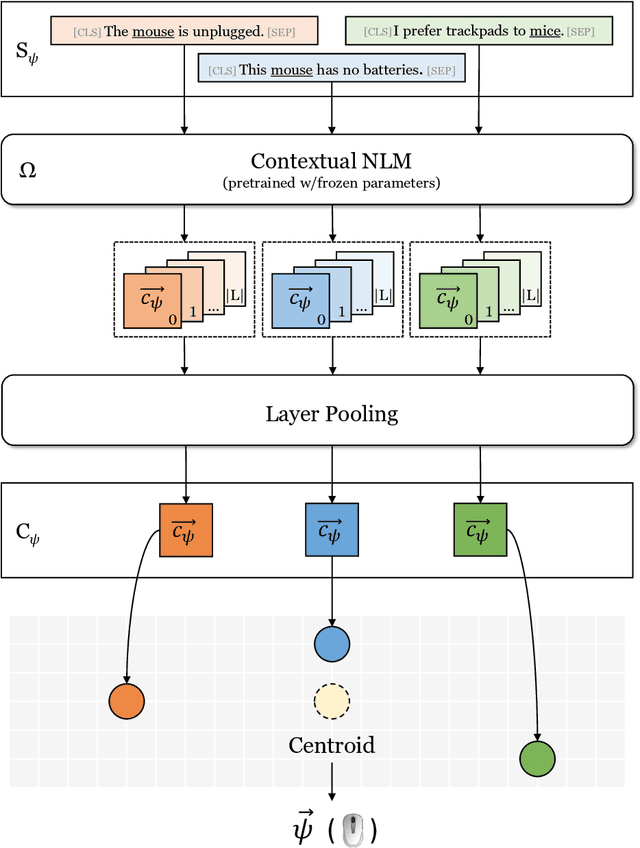
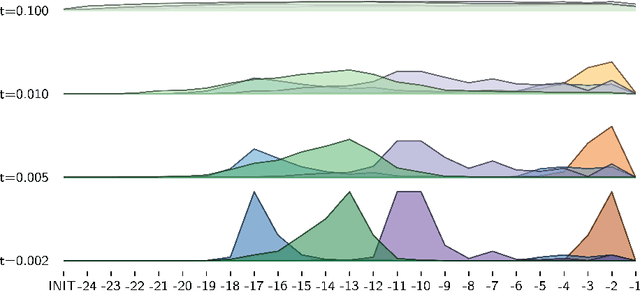
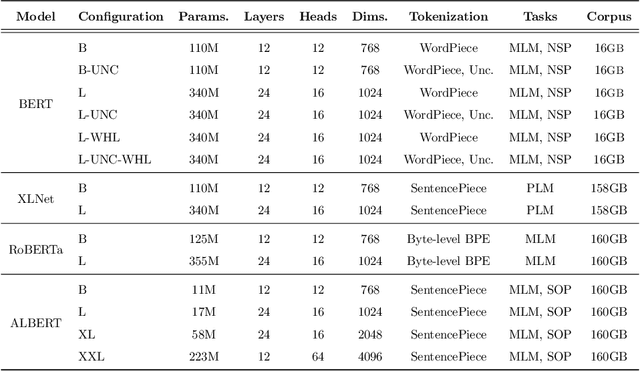
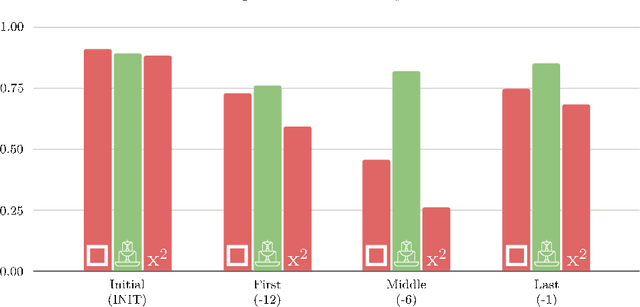
Distributional semantics based on neural approaches is a cornerstone of Natural Language Processing, with surprising connections to human meaning representation as well. Recent Transformer-based Language Models have proven capable of producing contextual word representations that reliably convey sense-specific information, simply as a product of self-supervision. Prior work has shown that these contextual representations can be used to accurately represent large sense inventories as sense embeddings, to the extent that a distance-based solution to Word Sense Disambiguation (WSD) tasks outperforms models trained specifically for the task. Still, there remains much to understand on how to use these Neural Language Models (NLMs) to produce sense embeddings that can better harness each NLM's meaning representation abilities. In this work we introduce a more principled approach to leverage information from all layers of NLMs, informed by a probing analysis on 14 NLM variants. We also emphasize the versatility of these sense embeddings in contrast to task-specific models, applying them on several sense-related tasks, besides WSD, while demonstrating improved performance using our proposed approach over prior work focused on sense embeddings. Finally, we discuss unexpected findings regarding layer and model performance variations, and potential applications for downstream tasks.
Preference rules for label ranking: Mining patterns in multi-target relations
Mar 20, 2019
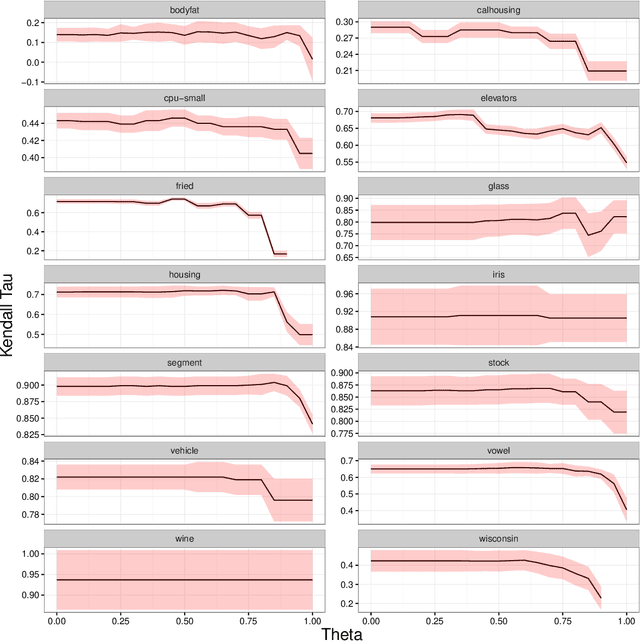
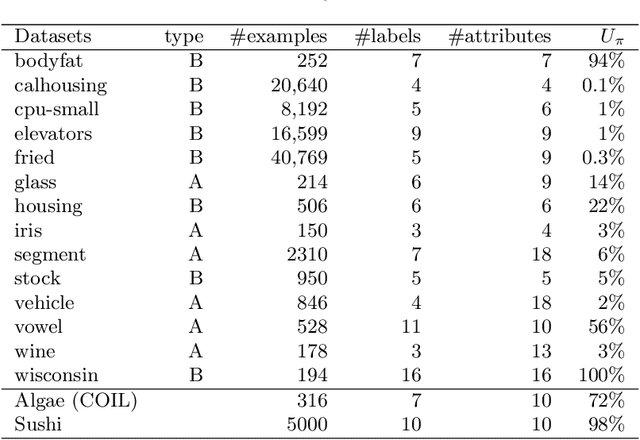
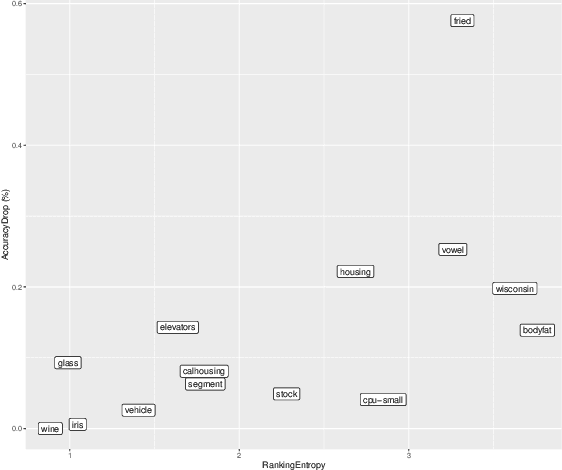
In this paper we investigate two variants of association rules for preference data, Label Ranking Association Rules and Pairwise Association Rules. Label Ranking Association Rules (LRAR) are the equivalent of Class Association Rules (CAR) for the Label Ranking task. In CAR, the consequent is a single class, to which the example is expected to belong to. In LRAR, the consequent is a ranking of the labels. The generation of LRAR requires special support and confidence measures to assess the similarity of rankings. In this work, we carry out a sensitivity analysis of these similarity-based measures. We want to understand which datasets benefit more from such measures and which parameters have more influence in the accuracy of the model. Furthermore, we propose an alternative type of rules, the Pairwise Association Rules (PAR), which are defined as association rules with a set of pairwise preferences in the consequent. While PAR can be used both as descriptive and predictive models, they are essentially descriptive models. Experimental results show the potential of both approaches.
Affordance Extraction and Inference based on Semantic Role Labeling
Sep 03, 2018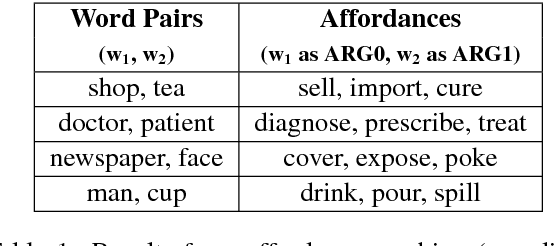
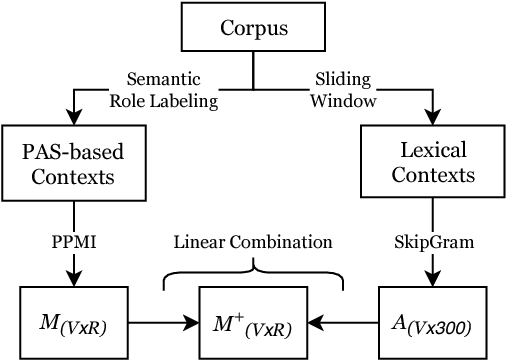
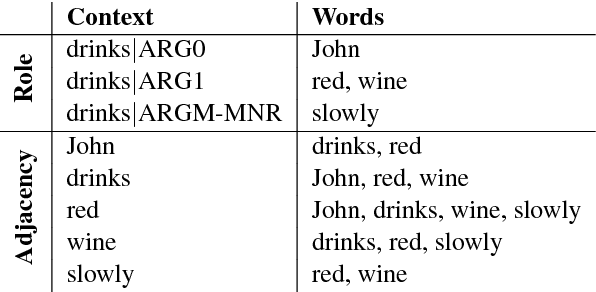
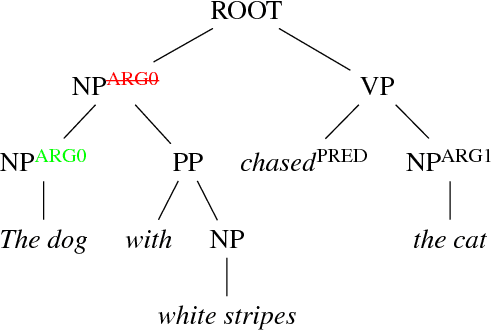
Common-sense reasoning is becoming increasingly important for the advancement of Natural Language Processing. While word embeddings have been very successful, they cannot explain which aspects of 'coffee' and 'tea' make them similar, or how they could be related to 'shop'. In this paper, we propose an explicit word representation that builds upon the Distributional Hypothesis to represent meaning from semantic roles, and allow inference of relations from their meshing, as supported by the affordance-based Indexical Hypothesis. We find that our model improves the state-of-the-art on unsupervised word similarity tasks while allowing for direct inference of new relations from the same vector space.