 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNNs on Monitoring Physical Activity Energy Expenditure in Older People
Jun 01, 2020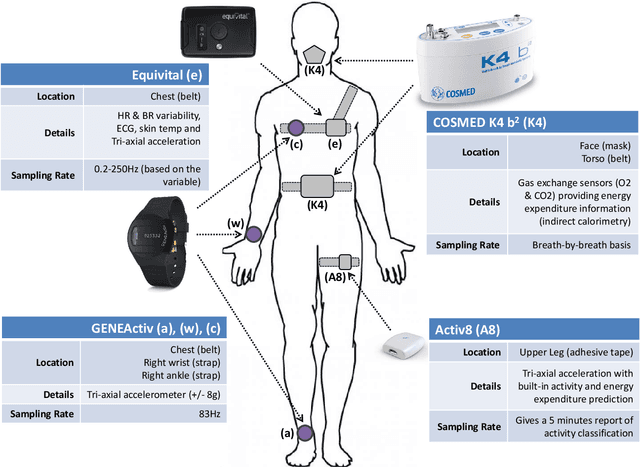

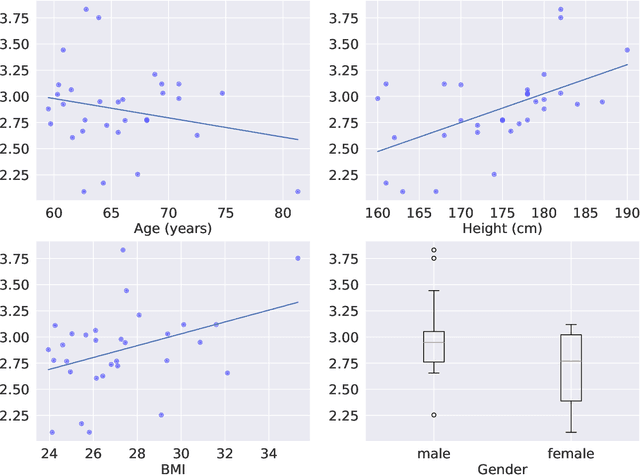
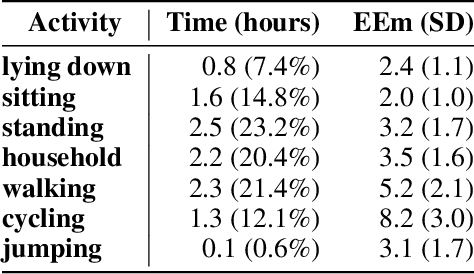
Through the quantification of physical activity energy expenditure (PAEE), health care monitoring has the potential to stimulate vital and healthy ageing, inducing behavioural changes in older people and linking these to personal health gains. To be able to measure PAEE in a monitoring environment, methods from wearable accelerometers have been developed, however, mainly targeted towards younger people. Since elderly subjects differ in energy requirements and range of physical activities, the current models may not be suitable for estimating PAEE among the elderly. Because past activities influence present PAEE, we propose a modeling approach known for its ability to model sequential data, the Recurrent Neural Network (RNN). To train the RNN for an elderly population, we used the GOTOV dataset with 34 healthy participants of 60 years and older (mean 65 years old), performing 16 different activities. We used accelerometers placed on wrist and ankle, and measurements of energy counts by means of indirect calorimetry. After optimization, we propose an architecture consisting of an RNN with 3 GRU layers and a feedforward network combining both accelerometer and participant-level data. In this paper, we describe our efforts to go beyond the standard facilities of a GRU-based RNN, with the aim of achieving accuracy surpassing the state of the art. These efforts include switching aggregation function from mean to dispersion measures (SD, IQR, ...), combining temporal and static data (person-specific details such as age, weight, BMI) and adding symbolic activity data as predicted by a previously trained ML model. The resulting architecture manages to increase its performance by approximatelly 10% while decreasing training input by a factor of 10. It can thus be employed to investigate associations of PAEE with vitality parameters related to metabolic and cognitive health and mental well-being.
Preference rules for label ranking: Mining patterns in multi-target relations
Mar 20, 2019
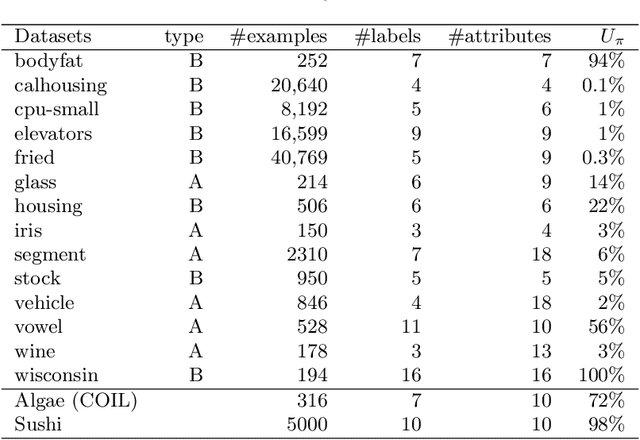
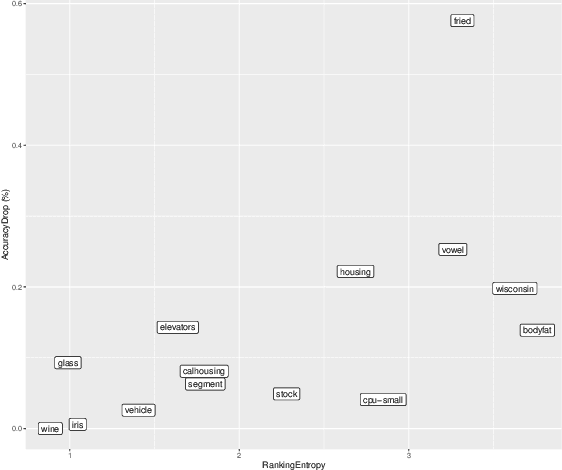
In this paper we investigate two variants of association rules for preference data, Label Ranking Association Rules and Pairwise Association Rules. Label Ranking Association Rules (LRAR) are the equivalent of Class Association Rules (CAR) for the Label Ranking task. In CAR, the consequent is a single class, to which the example is expected to belong to. In LRAR, the consequent is a ranking of the labels. The generation of LRAR requires special support and confidence measures to assess the similarity of rankings. In this work, we carry out a sensitivity analysis of these similarity-based measures. We want to understand which datasets benefit more from such measures and which parameters have more influence in the accuracy of the model. Furthermore, we propose an alternative type of rules, the Pairwise Association Rules (PAR), which are defined as association rules with a set of pairwise preferences in the consequent. While PAR can be used both as descriptive and predictive models, they are essentially descriptive models. Experimental results show the potential of both approaches.
Building robust prediction models for defective sensor data using Artificial Neural Networks
Apr 16, 2018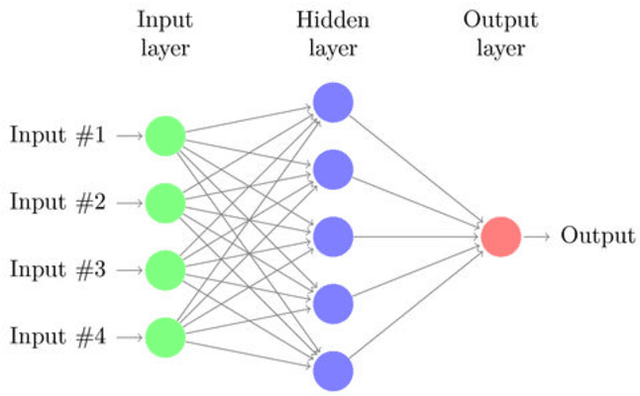
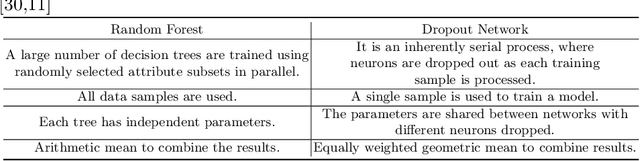
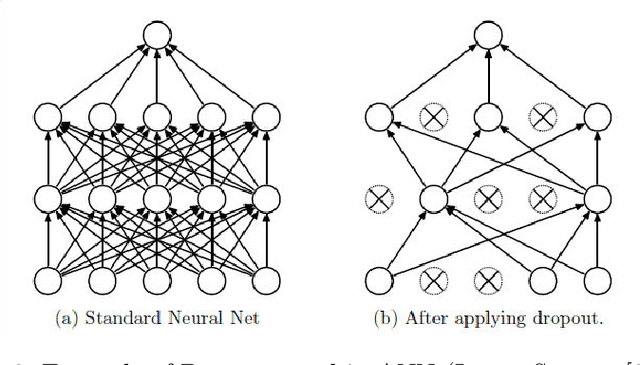
Predicting the health of components in complex dynamic systems such as an automobile poses numerous challenges. The primary aim of such predictive systems is to use the high-dimensional data acquired from different sensors and predict the state-of-health of a particular component, e.g., brake pad. The classical approach involves selecting a smaller set of relevant sensor signals using feature selection and using them to train a machine learning algorithm. However, this fails to address two prominent problems: (1) sensors are susceptible to failure when exposed to extreme conditions over a long periods of time; (2) sensors are electrical devices that can be affected by noise or electrical interference. Using the failed and noisy sensor signals as inputs largely reduce the prediction accuracy. To tackle this problem, it is advantageous to use the information from all sensor signals, so that the failure of one sensor can be compensated by another. In this work, we propose an Artificial Neural Network (ANN) based framework to exploit the information from a large number of signals. Secondly, our framework introduces a data augmentation approach to perform accurate predictions in spite of noisy signals. The plausibility of our framework is validated on real life industrial application from Robert Bosch GmbH.
Smart energy management as a means towards improved energy efficiency
Feb 08, 2018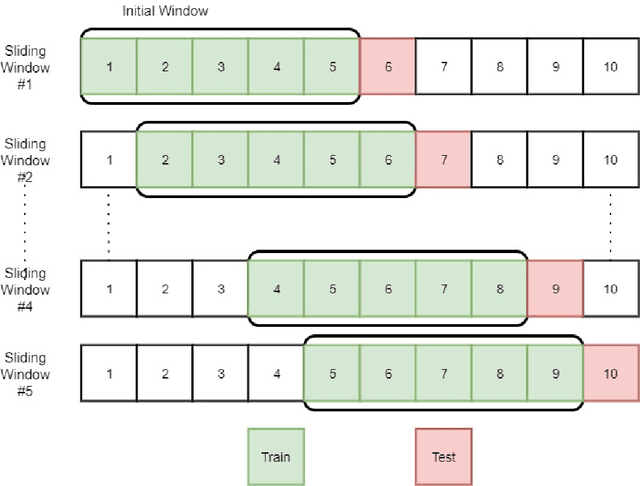
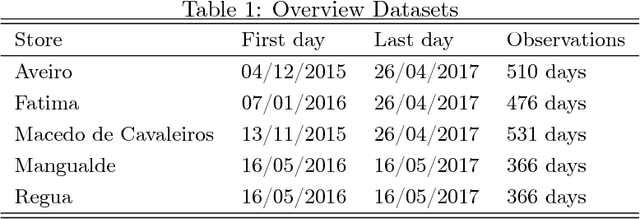
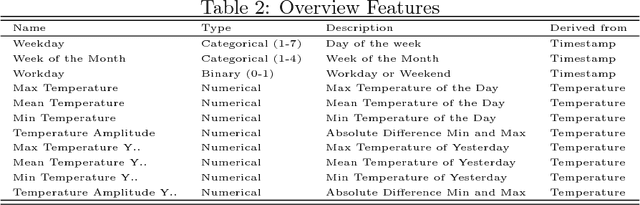
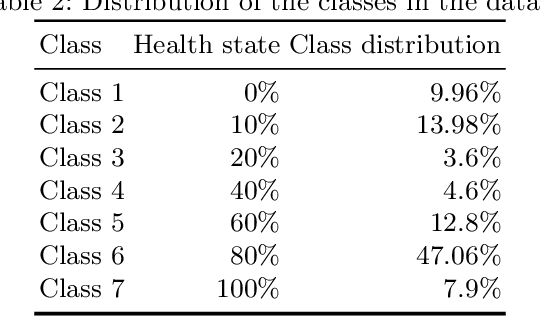
The costs associated with refrigerator equipment often represent more than half of the total energy costs in supermarkets. This presents a good motivation for running these systems efficiently. In this study, we investigate different ways to construct a reference behavior, which can serve as a baseline for judging the performance of energy consumption. We used 3 distinct learning models: Multiple Linear Regression, Random Forests, and Artificial Neural Networks. During our experiments we used a variation of the sliding window method in combination with learning curves. We applied this approach on five different supermarkets, across Portugal. We are able to create baselines using off-the-shelf data mining techniques. Moreover, we found a way to create them based on short term historical data. We believe that our research will serve as a base for future studies, for which we provide interesting directions.