 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the stability and plasticity of recommender systems
Aug 05, 2025The typical offline protocol to evaluate recommendation algorithms is to collect a dataset of user-item interactions and then use a part of this dataset to train a model, and the remaining data to measure how closely the model recommendations match the observed user interactions. This protocol is straightforward, useful and practical, but it only captures performance of a particular model trained at some point in the past. We know, however, that online systems evolve over time. In general, it is a good idea that models reflect such changes, so models are frequently retrained with recent data. But if this is the case, to what extent can we trust previous evaluations? How will a model perform when a different pattern (re)emerges? In this paper we propose a methodology to study how recommendation models behave when they are retrained. The idea is to profile algorithms according to their ability to, on the one hand, retain past patterns -- stability -- and, on the other hand, (quickly) adapt to changes -- plasticity. We devise an offline evaluation protocol that provides detail on the long-term behavior of models, and that is agnostic to datasets, algorithms and metrics. To illustrate the potential of this framework, we present preliminary results of three different types of algorithms on the GoodReads dataset that suggest different stability and plasticity profiles depending on the algorithmic technique, and a possible trade-off between stability and plasticity.Although additional experiments will be necessary to confirm these observations, they already illustrate the usefulness of the proposed framework to gain insights on the long term dynamics of recommendation models.
Rethinking negative sampling in content-based news recommendation
Nov 13, 2024



News recommender systems are hindered by the brief lifespan of articles, as they undergo rapid relevance decay. Recent studies have demonstrated the potential of content-based neural techniques in tackling this problem. However, these models often involve complex neural architectures and often lack consideration for negative examples. In this study, we posit that the careful sampling of negative examples has a big impact on the model's outcome. We devise a negative sampling technique that not only improves the accuracy of the model but also facilitates the decentralization of the recommendation system. The experimental results obtained using the MIND dataset demonstrate that the accuracy of the method under consideration can compete with that of State-of-the-Art models. The utilization of the sampling technique is essential in reducing model complexity and accelerating the training process, while maintaining a high level of accuracy. Finally, we discuss how decentralized models can help improve privacy and scalability.
Behind Recommender Systems: the Geography of the ACM RecSys Community
Sep 07, 2023The amount and dissemination rate of media content accessible online is nowadays overwhelming. Recommender Systems filter this information into manageable streams or feeds, adapted to our personal needs or preferences. It is of utter importance that algorithms employed to filter information do not distort or cut out important elements from our perspectives of the world. Under this principle, it is essential to involve diverse views and teams from the earliest stages of their design and development. This has been highlighted, for instance, in recent European Union regulations such as the Digital Services Act, via the requirement of risk monitoring, including the risk of discrimination, and the AI Act, through the requirement to involve people with diverse backgrounds in the development of AI systems. We look into the geographic diversity of the recommender systems research community, specifically by analyzing the affiliation countries of the authors who contributed to the ACM Conference on Recommender Systems (RecSys) during the last 15 years. This study has been carried out in the framework of the Diversity in AI - DivinAI project, whose main objective is the long-term monitoring of diversity in AI forums through a set of indexes.
Fairness and Diversity in Information Access Systems
May 16, 2023Among the seven key requirements to achieve trustworthy AI proposed by the High-Level Expert Group on Artificial Intelligence (AI-HLEG) established by the European Commission (EC), the fifth requirement ("Diversity, non-discrimination and fairness") declares: "In order to achieve Trustworthy AI, we must enable inclusion and diversity throughout the entire AI system's life cycle. [...] This requirement is closely linked with the principle of fairness". In this paper, we try to shed light on how closely these two distinct concepts, diversity and fairness, may be treated by focusing on information access systems and ranking literature. These concepts should not be used interchangeably because they do represent two different values, but what we argue is that they also cannot be considered totally unrelated or divergent. Having diversity does not imply fairness, but fostering diversity can effectively lead to fair outcomes, an intuition behind several methods proposed to mitigate the disparate impact of information access systems, i.e. recommender systems and search engines.
Federated Anomaly Detection over Distributed Data Streams
May 17, 2022Sharing of telecommunication network data, for example, even at high aggregation levels, is nowadays highly restricted due to privacy legislation and regulations and other important ethical concerns. It leads to scattering data across institutions, regions, and states, inhibiting the usage of AI methods that could otherwise take advantage of data at scale. It creates the need to build a platform to control such data, build models or perform calculations. In this work, we propose an approach to building the bridge among anomaly detection, federated learning, and data streams. The overarching goal of the work is to detect anomalies in a federated environment over distributed data streams. This work complements the state-of-the-art by adapting the data stream algorithms in a federated learning setting for anomaly detection and by delivering a robust framework and demonstrating the practical feasibility in a real-world distributed deployment scenario.
Proceedings of the 4th Workshop on Online Recommender Systems and User Modeling -- ORSUM 2021
Jan 17, 2022Modern online services continuously generate data at very fast rates. This continuous flow of data encompasses content - e.g., posts, news, products, comments -, but also user feedback - e.g., ratings, views, reads, clicks -, together with context data - user device, spatial or temporal data, user task or activity, weather. This can be overwhelming for systems and algorithms designed to train in batches, given the continuous and potentially fast change of content, context and user preferences or intents. Therefore, it is important to investigate online methods able to transparently adapt to the inherent dynamics of online services. Incremental models that learn from data streams are gaining attention in the recommender systems community, given their natural ability to deal with the continuous flows of data generated in dynamic, complex environments. User modeling and personalization can particularly benefit from algorithms capable of maintaining models incrementally and online. The objective of this workshop is to foster contributions and bring together a growing community of researchers and practitioners interested in online, adaptive approaches to user modeling, recommendation and personalization, and their implications regarding multiple dimensions, such as evaluation, reproducibility, privacy and explainability.
AutoFITS: Automatic Feature Engineering for Irregular Time Series
Dec 29, 2021
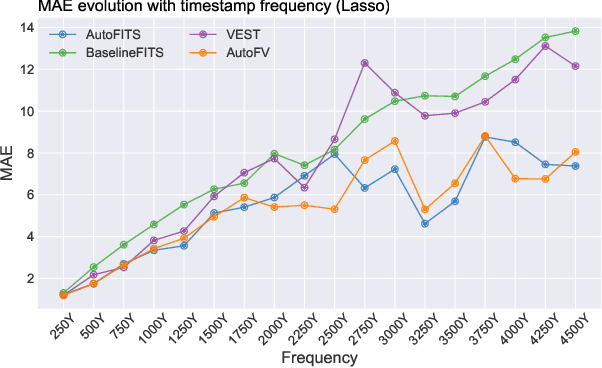
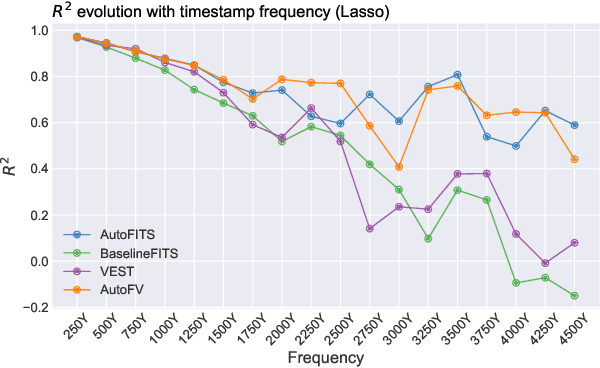
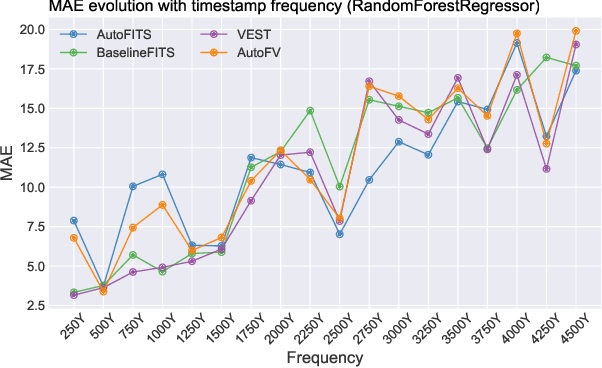
A time series represents a set of observations collected over time. Typically, these observations are captured with a uniform sampling frequency (e.g. daily). When data points are observed in uneven time intervals the time series is referred to as irregular or intermittent. In such scenarios, the most common solution is to reconstruct the time series to make it regular, thus removing its intermittency. We hypothesise that, in irregular time series, the time at which each observation is collected may be helpful to summarise the dynamics of the data and improve forecasting performance. We study this idea by developing a novel automatic feature engineering framework, which focuses on extracting information from this point of view, i.e., when each instance is collected. We study how valuable this information is by integrating it in a time series forecasting workflow and investigate how it compares to or complements state-of-the-art methods for regular time series forecasting. In the end, we contribute by providing a novel framework that tackles feature engineering for time series from an angle previously vastly ignored. We show that our approach has the potential to further extract more information about time series that significantly improves forecasting performance.