 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Platform-Agnostic Multimodal Digital Human Modelling Framework: Neurophysiological Sensing in Game-Based Interaction
Mar 11, 2026Digital Human Modelling (DHM) is increasingly shaped by advances in AI, wearable biosensing, and interactive digital environments, particularly in research addressing accessibility and inclusion. However, many AI-enabled DHM approaches remain tightly coupled to specific platforms, tasks, or interpretative pipelines, limiting reproducibility, scalability, and ethical reuse. This paper presents a platform-agnostic DHM framework designed to support AI-ready multimodal interaction research by explicitly separating sensing, interaction modelling, and inference readiness. The framework integrates the OpenBCI Galea headset as a unified multimodal sensing layer, providing concurrent EEG, EMG, EOG, PPG, and inertial data streams, alongside a reproducible, game-based interaction environment implemented using SuperTux. Rather than embedding AI models or behavioural inference, physiological signals are represented as structured, temporally aligned observables, enabling downstream AI methods to be applied under appropriate ethical approval. Interaction is modelled using computational task primitives and timestamped event markers, supporting consistent alignment across heterogeneous sensors and platforms. Technical verification via author self-instrumentation confirms data integrity, stream continuity, and synchronisation; no human-subjects evaluation or AI inference is reported. Scalability considerations are discussed with respect to data throughput, latency, and extension to additional sensors or interaction modalities. Illustrative use cases demonstrate how the framework can support AI-enabled DHM and HCI studies, including accessibility-oriented interaction design and adaptive systems research, without requiring architectural modifications. The proposed framework provides an emerging-technology-focused infrastructure for future ethics-approved, inclusive DHM research.
Bearded Dragon Activity Recognition Pipeline: An AI-Based Approach to Behavioural Monitoring
Jul 23, 2025Traditional monitoring of bearded dragon (Pogona Viticeps) behaviour is time-consuming and prone to errors. This project introduces an automated system for real-time video analysis, using You Only Look Once (YOLO) object detection models to identify two key behaviours: basking and hunting. We trained five YOLO variants (v5, v7, v8, v11, v12) on a custom, publicly available dataset of 1200 images, encompassing bearded dragons (600), heating lamps (500), and crickets (100). YOLOv8s was selected as the optimal model due to its superior balance of accuracy (mAP@0.5:0.95 = 0.855) and speed. The system processes video footage by extracting per-frame object coordinates, applying temporal interpolation for continuity, and using rule-based logic to classify specific behaviours. Basking detection proved reliable. However, hunting detection was less accurate, primarily due to weak cricket detection (mAP@0.5 = 0.392). Future improvements will focus on enhancing cricket detection through expanded datasets or specialised small-object detectors. This automated system offers a scalable solution for monitoring reptile behaviour in controlled environments, significantly improving research efficiency and data quality.
ArtBrain: An Explainable end-to-end Toolkit for Classification and Attribution of AI-Generated Art and Style
Dec 02, 2024Recently, the quality of artworks generated using Artificial Intelligence (AI) has increased significantly, resulting in growing difficulties in detecting synthetic artworks. However, limited studies have been conducted on identifying the authenticity of synthetic artworks and their source. This paper introduces AI-ArtBench, a dataset featuring 185,015 artistic images across 10 art styles. It includes 125,015 AI-generated images and 60,000 pieces of human-created artwork. This paper also outlines a method to accurately detect AI-generated images and trace them to their source model. This work proposes a novel Convolutional Neural Network model based on the ConvNeXt model called AttentionConvNeXt. AttentionConvNeXt was implemented and trained to differentiate between the source of the artwork and its style with an F1-Score of 0.869. The accuracy of attribution to the generative model reaches 0.999. To combine the scientific contributions arising from this study, a web-based application named ArtBrain was developed to enable both technical and non-technical users to interact with the model. Finally, this study presents the results of an Artistic Turing Test conducted with 50 participants. The findings reveal that humans could identify AI-generated images with an accuracy of approximately 58%, while the model itself achieved a significantly higher accuracy of around 99%.
What Differentiates Educational Literature? A Multimodal Fusion Approach of Transformers and Computational Linguistics
Nov 26, 2024



The integration of new literature into the English curriculum remains a challenge since educators often lack scalable tools to rapidly evaluate readability and adapt texts for diverse classroom needs. This study proposes to address this gap through a multimodal approach that combines transformer-based text classification with linguistic feature analysis to align texts with UK Key Stages. Eight state-of-the-art Transformers were fine-tuned on segmented text data, with BERT achieving the highest unimodal F1 score of 0.75. In parallel, 500 deep neural network topologies were searched for the classification of linguistic characteristics, achieving an F1 score of 0.392. The fusion of these modalities shows a significant improvement, with every multimodal approach outperforming all unimodal models. In particular, the ELECTRA Transformer fused with the neural network achieved an F1 score of 0.996. The proposed approach is finally encapsulated in a stakeholder-facing web application, providing non-technical stakeholder access to real-time insights on text complexity, reading difficulty, curriculum alignment, and recommendations for learning age range. The application empowers data-driven decision making and reduces manual workload by integrating AI-based recommendations into lesson planning for English literature.
Enhancing Pollinator Conservation towards Agriculture 4.0: Monitoring of Bees through Object Recognition
May 24, 2024



In an era of rapid climate change and its adverse effects on food production, technological intervention to monitor pollinator conservation is of paramount importance for environmental monitoring and conservation for global food security. The survival of the human species depends on the conservation of pollinators. This article explores the use of Computer Vision and Object Recognition to autonomously track and report bee behaviour from images. A novel dataset of 9664 images containing bees is extracted from video streams and annotated with bounding boxes. With training, validation and testing sets (6722, 1915, and 997 images, respectively), the results of the COCO-based YOLO model fine-tuning approaches show that YOLOv5m is the most effective approach in terms of recognition accuracy. However, YOLOv5s was shown to be the most optimal for real-time bee detection with an average processing and inference time of 5.1ms per video frame at the cost of slightly lower ability. The trained model is then packaged within an explainable AI interface, which converts detection events into timestamped reports and charts, with the aim of facilitating use by non-technical users such as expert stakeholders from the apiculture industry towards informing responsible consumption and production.
WeedScout: Real-Time Autonomous blackgrass Classification and Mapping using dedicated hardware
May 12, 2024
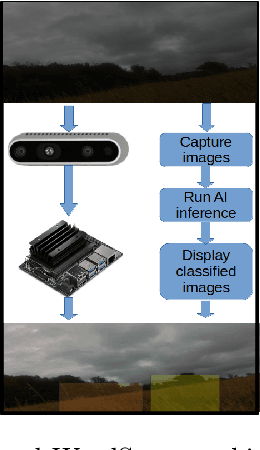
Blackgrass (Alopecurus myosuroides) is a competitive weed that has wide-ranging impacts on food security by reducing crop yields and increasing cultivation costs. In addition to the financial burden on agriculture, the application of herbicides as a preventive to blackgrass can negatively affect access to clean water and sanitation. The WeedScout project introduces a Real-Rime Autonomous Black-Grass Classification and Mapping (RT-ABGCM), a cutting-edge solution tailored for real-time detection of blackgrass, for precision weed management practices. Leveraging Artificial Intelligence (AI) algorithms, the system processes live image feeds, infers blackgrass density, and covers two stages of maturation. The research investigates the deployment of You Only Look Once (YOLO) models, specifically the streamlined YOLOv8 and YOLO-NAS, accelerated at the edge with the NVIDIA Jetson Nano (NJN). By optimising inference speed and model performance, the project advances the integration of AI into agricultural practices, offering potential solutions to challenges such as herbicide resistance and environmental impact. Additionally, two datasets and model weights are made available to the research community, facilitating further advancements in weed detection and precision farming technologies.
A Deep Learning Method for Classification of Biophilic Artworks
Mar 08, 2024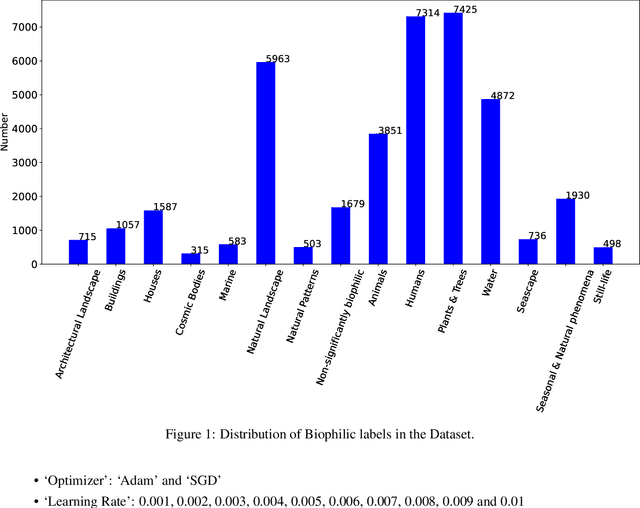
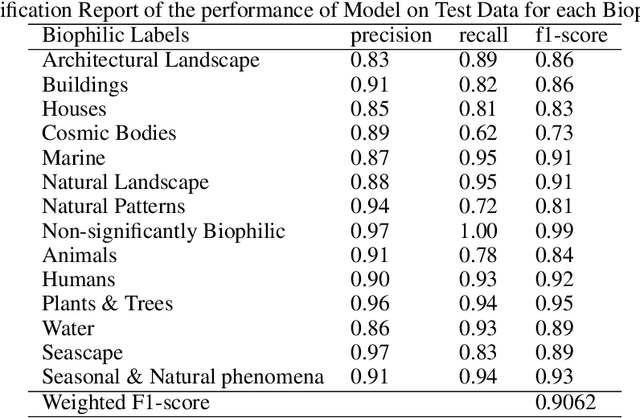
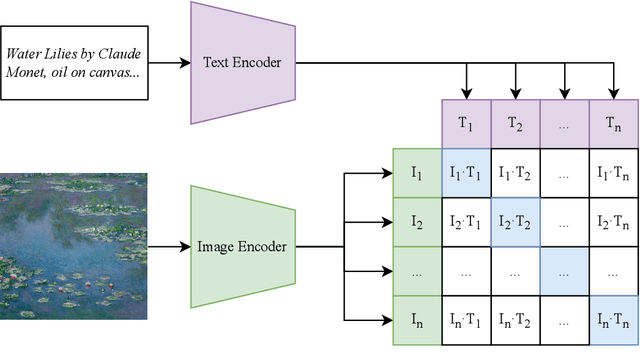
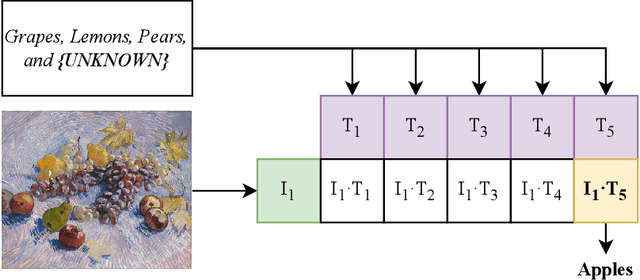
Biophilia is an innate love for living things and nature itself that has been associated with a positive impact on mental health and well-being. This study explores the application of deep learning methods for the classification of Biophilic artwork, in order to learn and explain the different Biophilic characteristics present in a visual representation of a painting. Using the concept of Biophilia that postulates the deep connection of human beings with nature, we use an artificially intelligent algorithm to recognise the different patterns underlying the Biophilic features in an artwork. Our proposed method uses a lower-dimensional representation of an image and a decoder model to extract salient features of the image of each Biophilic trait, such as plants, water bodies, seasons, animals, etc., based on learnt factors such as shape, texture, and illumination. The proposed classification model is capable of extracting Biophilic artwork that not only helps artists, collectors, and researchers studying to interpret and exploit the effects of mental well-being on exposure to nature-inspired visual aesthetics but also enables a methodical exploration of the study of Biophilia and Biophilic artwork for aesthetic preferences. Using the proposed algorithms, we have also created a gallery of Biophilic collections comprising famous artworks from different European and American art galleries, which will soon be published on the Vieunite@ online community.
UDEEP: Edge-based Computer Vision for In-Situ Underwater Crayfish and Plastic Detection
Dec 21, 2023Invasive signal crayfish have a detrimental impact on ecosystems. They spread the fungal-type crayfish plague disease (Aphanomyces astaci) that is lethal to the native white clawed crayfish, the only native crayfish species in Britain. Invasive signal crayfish extensively burrow, causing habitat destruction, erosion of river banks and adverse changes in water quality, while also competing with native species for resources and leading to declines in native populations. Moreover, pollution exacerbates the vulnerability of White-clawed crayfish, with their populations declining by over 90% in certain English counties, making them highly susceptible to extinction. To safeguard aquatic ecosystems, it is imperative to address the challenges posed by invasive species and discarded plastics in the United Kingdom's river ecosystem's. The UDEEP platform can play a crucial role in environmental monitoring by performing on-the-fly classification of Signal crayfish and plastic debris while leveraging the efficacy of AI, IoT devices and the power of edge computing (i.e., NJN). By providing accurate data on the presence, spread and abundance of these species, the UDEEP platform can contribute to monitoring efforts and aid in mitigating the spread of invasive species.
FM-G-CAM: A Holistic Approach for Explainable AI in Computer Vision
Dec 10, 2023



Explainability is an aspect of modern AI that is vital for impact and usability in the real world. The main objective of this paper is to emphasise the need to understand the predictions of Computer Vision models, specifically Convolutional Neural Network (CNN) based models. Existing methods of explaining CNN predictions are mostly based on Gradient-weighted Class Activation Maps (Grad-CAM) and solely focus on a single target class. We show that from the point of the target class selection, we make an assumption on the prediction process, hence neglecting a large portion of the predictor CNN model's thinking process. In this paper, we present an exhaustive methodology called Fused Multi-class Gradient-weighted Class Activation Map (FM-G-CAM) that considers multiple top predicted classes, which provides a holistic explanation of the predictor CNN's thinking rationale. We also provide a detailed and comprehensive mathematical and algorithmic description of our method. Furthermore, along with a concise comparison of existing methods, we compare FM-G-CAM with Grad-CAM, highlighting its benefits through real-world practical use cases. Finally, we present an open-source Python library with FM-G-CAM implementation to conveniently generate saliency maps for CNN-based model predictions.
Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
Aug 24, 2023



There are growing implications surrounding generative AI in the speech domain that enable voice cloning and real-time voice conversion from one individual to another. This technology poses a significant ethical threat and could lead to breaches of privacy and misrepresentation, thus there is an urgent need for real-time detection of AI-generated speech for DeepFake Voice Conversion. To address the above emerging issues, the DEEP-VOICE dataset is generated in this study, comprised of real human speech from eight well-known figures and their speech converted to one another using Retrieval-based Voice Conversion. Presenting as a binary classification problem of whether the speech is real or AI-generated, statistical analysis of temporal audio features through t-testing reveals that there are significantly different distributions. Hyperparameter optimisation is implemented for machine learning models to identify the source of speech. Following the training of 208 individual machine learning models over 10-fold cross validation, it is found that the Extreme Gradient Boosting model can achieve an average classification accuracy of 99.3% and can classify speech in real-time, at around 0.004 milliseconds given one second of speech. All data generated for this study is released publicly for future research on AI speech detection.