 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeedScout: Real-Time Autonomous blackgrass Classification and Mapping using dedicated hardware
May 12, 2024
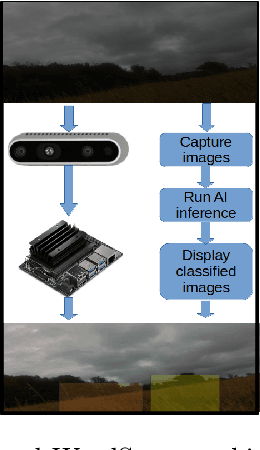
Blackgrass (Alopecurus myosuroides) is a competitive weed that has wide-ranging impacts on food security by reducing crop yields and increasing cultivation costs. In addition to the financial burden on agriculture, the application of herbicides as a preventive to blackgrass can negatively affect access to clean water and sanitation. The WeedScout project introduces a Real-Rime Autonomous Black-Grass Classification and Mapping (RT-ABGCM), a cutting-edge solution tailored for real-time detection of blackgrass, for precision weed management practices. Leveraging Artificial Intelligence (AI) algorithms, the system processes live image feeds, infers blackgrass density, and covers two stages of maturation. The research investigates the deployment of You Only Look Once (YOLO) models, specifically the streamlined YOLOv8 and YOLO-NAS, accelerated at the edge with the NVIDIA Jetson Nano (NJN). By optimising inference speed and model performance, the project advances the integration of AI into agricultural practices, offering potential solutions to challenges such as herbicide resistance and environmental impact. Additionally, two datasets and model weights are made available to the research community, facilitating further advancements in weed detection and precision farming technologies.
A Machine Learning Approach to Detect Customer Satisfaction From Multiple Tweet Parameters
Feb 25, 2024



Since internet technologies have advanced, one of the primary factors in company development is customer happiness. Online platforms have become prominent places for sharing reviews. Twitter is one of these platforms where customers frequently post their thoughts. Reviews of flights on these platforms have become a concern for the airline business. A positive review can help the company grow, while a negative one can quickly ruin its revenue and reputation. So it's vital for airline businesses to examine the feedback and experiences of their customers and enhance their services to remain competitive. But studying thousands of tweets and analyzing them to find the satisfaction of the customer is quite a difficult task. This tedious process can be made easier by using a machine learning approach to analyze tweets to determine client satisfaction levels. Some work has already been done on this strategy to automate the procedure using machine learning and deep learning techniques. However, they are all purely concerned with assessing the text's sentiment. In addition to the text, the tweet also includes the time, location, username, airline name, and so on. This additional information can be crucial for improving the model's outcome. To provide a machine learning based solution, this work has broadened its perspective to include these qualities. And it has come as no surprise that the additional features beyond text sentiment analysis produce better outcomes in machine learning based models.
UDEEP: Edge-based Computer Vision for In-Situ Underwater Crayfish and Plastic Detection
Dec 21, 2023Invasive signal crayfish have a detrimental impact on ecosystems. They spread the fungal-type crayfish plague disease (Aphanomyces astaci) that is lethal to the native white clawed crayfish, the only native crayfish species in Britain. Invasive signal crayfish extensively burrow, causing habitat destruction, erosion of river banks and adverse changes in water quality, while also competing with native species for resources and leading to declines in native populations. Moreover, pollution exacerbates the vulnerability of White-clawed crayfish, with their populations declining by over 90% in certain English counties, making them highly susceptible to extinction. To safeguard aquatic ecosystems, it is imperative to address the challenges posed by invasive species and discarded plastics in the United Kingdom's river ecosystem's. The UDEEP platform can play a crucial role in environmental monitoring by performing on-the-fly classification of Signal crayfish and plastic debris while leveraging the efficacy of AI, IoT devices and the power of edge computing (i.e., NJN). By providing accurate data on the presence, spread and abundance of these species, the UDEEP platform can contribute to monitoring efforts and aid in mitigating the spread of invasive species.
IKD+: Reliable Low Complexity Deep Models For Retinopathy Classification
Mar 04, 2023



Deep neural network (DNN) models for retinopathy have estimated predictive accuracies in the mid-to-high 90%. However, the following aspects remain unaddressed: State-of-the-art models are complex and require substantial computational infrastructure to train and deploy; The reliability of predictions can vary widely. In this paper, we focus on these aspects and propose a form of iterative knowledge distillation(IKD), called IKD+ that incorporates a tradeoff between size, accuracy and reliability. We investigate the functioning of IKD+ using two widely used techniques for estimating model calibration (Platt-scaling and temperature-scaling), using the best-performing model available, which is an ensemble of EfficientNets with approximately 100M parameters. We demonstrate that IKD+ equipped with temperature-scaling results in models that show up to approximately 500-fold decreases in the number of parameters than the original ensemble without a significant loss in accuracy. In addition, calibration scores (reliability) for the IKD+ models are as good as or better than the base mode
Efficient, Effective and Well Justified Estimation of Active Nodes within a Cluster
Jan 26, 2020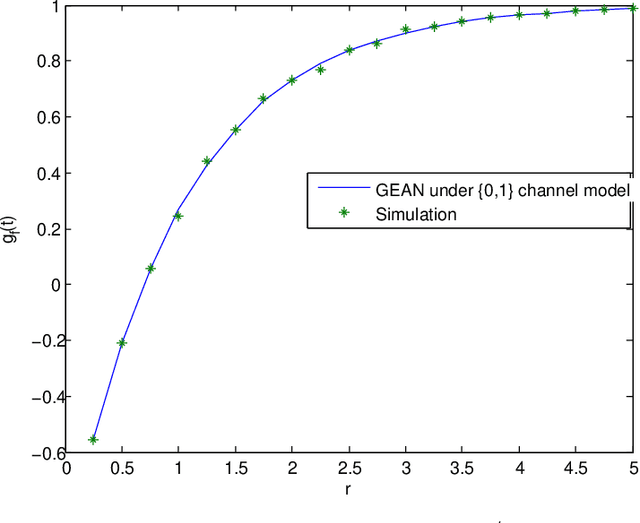
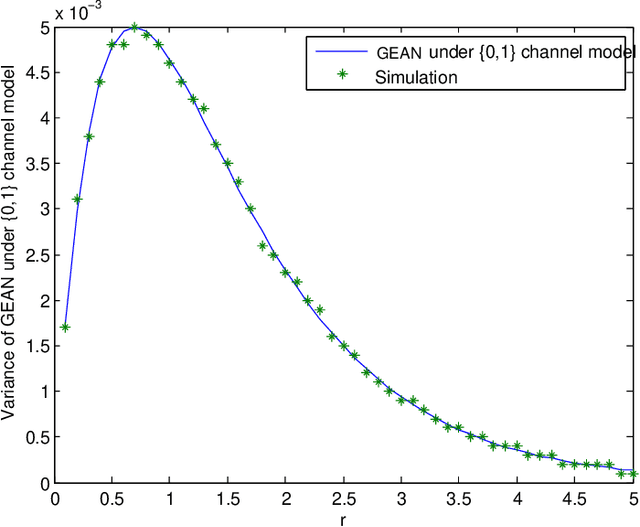
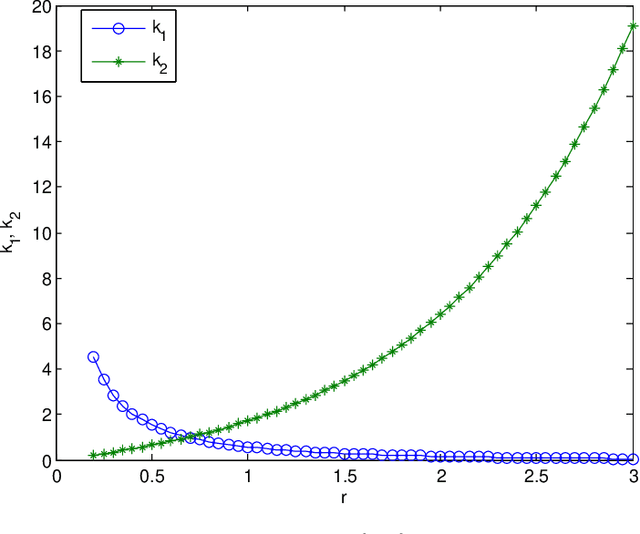
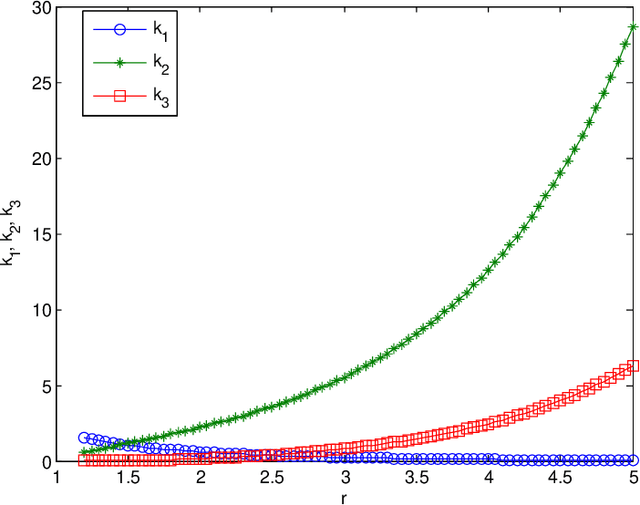
Reliable and efficient estimation of the size of a dynamically changing cluster in an IoT network is critical in its nominal operation. Most previous estimation schemes worked with relatively smaller frame size and large number of rounds. Here we propose a new estimator named \textquotedblleft Gaussian Estimator of Active Nodes,\textquotedblright (GEAN), that works with large enough frame size under which testing statistics is well approximated as a Gaussian variable, thereby requiring less number of frames, and thus less total number of channel slots to attain a desired accuracy in estimation. More specifically, the selection of the frame size is done according to Triangular Array Central Limit Theorem which also enables us to quantify the approximation error. Larger frame size helps the statistical average to converge faster to the ensemble mean of the estimator and the quantification of the approximation error helps to determine the number of rounds to keep up with the accuracy requirements. We present the analysis of our scheme under two different channel models i.e. $ \{0,1 \} $ and $ \{0,1,e \} $, whereas all previous schemes worked only under $ \{0,1 \} $ channel model. The overall performance of GEAN is better than the previously proposed schemes considering the number of slots required for estimation to achieve a given level of estimation accuracy.
Latent Factor Analysis of Gaussian Distributions under Graphical Constraints
Jan 11, 2020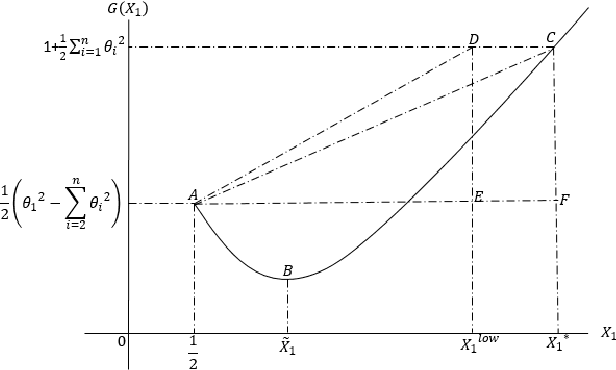
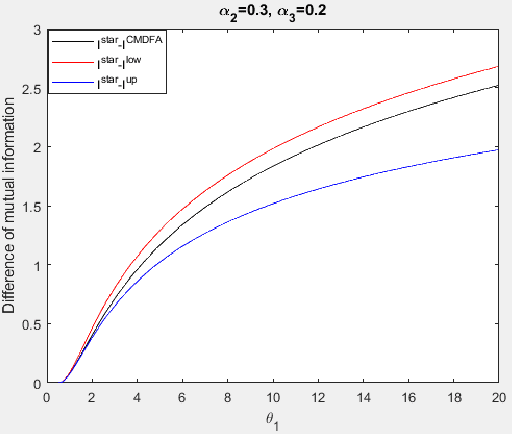
We explore the algebraic structure of the solution space of convex optimization problem Constrained Minimum Trace Factor Analysis (CMTFA), when the population covariance matrix $\Sigma_x$ has an additional latent graphical constraint, namely, a latent star topology. In particular, we have shown that CMTFA can have either a rank $ 1 $ or a rank $ n-1 $ solution and nothing in between. The special case of a rank $ 1 $ solution, corresponds to the case where just one latent variable captures all the dependencies among the observables, giving rise to a star topology. We found explicit conditions for both rank $ 1 $ and rank $n- 1$ solutions for CMTFA solution of $\Sigma_x$. As a basic attempt towards building a more general Gaussian tree, we have found a necessary and a sufficient condition for multiple clusters, each having rank $ 1 $ CMTFA solution, to satisfy a minimum probability to combine together to build a Gaussian tree. To support our analytical findings we have presented some numerical demonstrating the usefulness of the contributions of our work.