 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIKD+: Reliable Low Complexity Deep Models For Retinopathy Classification
Mar 04, 2023



Deep neural network (DNN) models for retinopathy have estimated predictive accuracies in the mid-to-high 90%. However, the following aspects remain unaddressed: State-of-the-art models are complex and require substantial computational infrastructure to train and deploy; The reliability of predictions can vary widely. In this paper, we focus on these aspects and propose a form of iterative knowledge distillation(IKD), called IKD+ that incorporates a tradeoff between size, accuracy and reliability. We investigate the functioning of IKD+ using two widely used techniques for estimating model calibration (Platt-scaling and temperature-scaling), using the best-performing model available, which is an ensemble of EfficientNets with approximately 100M parameters. We demonstrate that IKD+ equipped with temperature-scaling results in models that show up to approximately 500-fold decreases in the number of parameters than the original ensemble without a significant loss in accuracy. In addition, calibration scores (reliability) for the IKD+ models are as good as or better than the base mode
Domain-Specific Pretraining Improves Confidence in Whole Slide Image Classification
Feb 20, 2023Whole Slide Images (WSIs) or histopathology images are used in digital pathology. WSIs pose great challenges to deep learning models for clinical diagnosis, owing to their size and lack of pixel-level annotations. With the recent advancements in computational pathology, newer multiple-instance learning-based models have been proposed. Multiple-instance learning for WSIs necessitates creating patches and uses the encoding of these patches for diagnosis. These models use generic pre-trained models (ResNet-50 pre-trained on ImageNet) for patch encoding. The recently proposed KimiaNet, a DenseNet121 model pre-trained on TCGA slides, is a domain-specific pre-trained model. This paper shows the effect of domain-specific pre-training on WSI classification. To investigate the impact of domain-specific pre-training, we considered the current state-of-the-art multiple-instance learning models, 1) CLAM, an attention-based model, and 2) TransMIL, a self-attention-based model, and evaluated the models' confidence and predictive performance in detecting primary brain tumors - gliomas. Domain-specific pre-training improves the confidence of the models and also achieves a new state-of-the-art performance of WSI-based glioma subtype classification, showing a high clinical applicability in assisting glioma diagnosis.
Calibrating Deep Neural Networks using Explicit Regularisation and Dynamic Data Pruning
Dec 20, 2022



Deep neural networks (DNN) are prone to miscalibrated predictions, often exhibiting a mismatch between the predicted output and the associated confidence scores. Contemporary model calibration techniques mitigate the problem of overconfident predictions by pushing down the confidence of the winning class while increasing the confidence of the remaining classes across all test samples. However, from a deployment perspective, an ideal model is desired to (i) generate well-calibrated predictions for high-confidence samples with predicted probability say >0.95, and (ii) generate a higher proportion of legitimate high-confidence samples. To this end, we propose a novel regularization technique that can be used with classification losses, leading to state-of-the-art calibrated predictions at test time; From a deployment standpoint in safety-critical applications, only high-confidence samples from a well-calibrated model are of interest, as the remaining samples have to undergo manual inspection. Predictive confidence reduction of these potentially ``high-confidence samples'' is a downside of existing calibration approaches. We mitigate this by proposing a dynamic train-time data pruning strategy that prunes low-confidence samples every few epochs, providing an increase in "confident yet calibrated samples". We demonstrate state-of-the-art calibration performance across image classification benchmarks, reducing training time without much compromise in accuracy. We provide insights into why our dynamic pruning strategy that prunes low-confidence training samples leads to an increase in high-confidence samples at test time.
Knowledge-based Analogical Reasoning in Neuro-symbolic Latent Spaces
Sep 19, 2022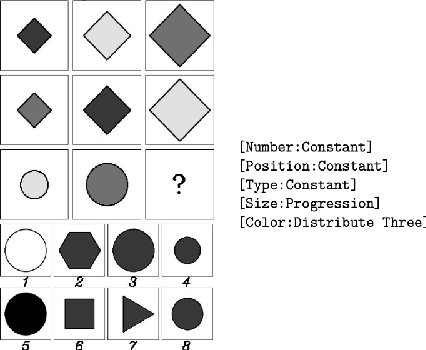
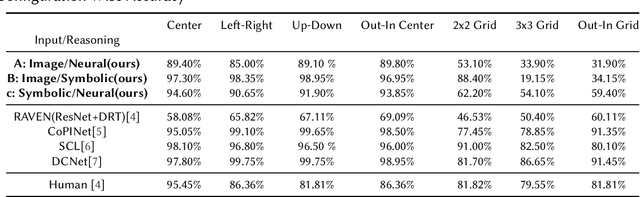
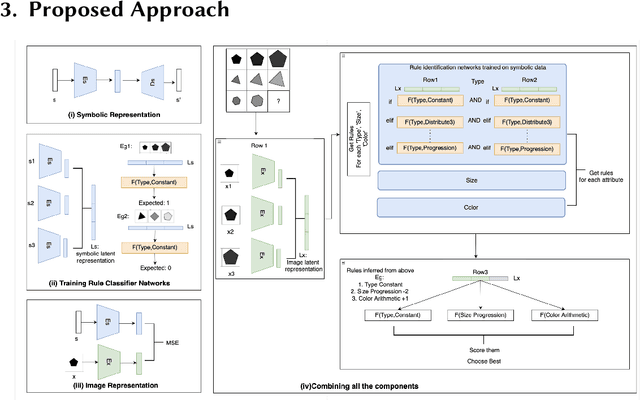
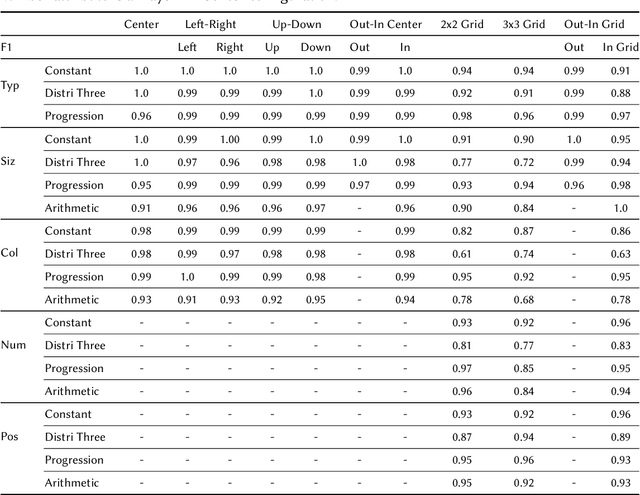
Analogical Reasoning problems challenge both connectionist and symbolic AI systems as these entail a combination of background knowledge, reasoning and pattern recognition. While symbolic systems ingest explicit domain knowledge and perform deductive reasoning, they are sensitive to noise and require inputs be mapped to preset symbolic features. Connectionist systems on the other hand can directly ingest rich input spaces such as images, text or speech and recognize pattern even with noisy inputs. However, connectionist models struggle to include explicit domain knowledge for deductive reasoning. In this paper, we propose a framework that combines the pattern recognition abilities of neural networks with symbolic reasoning and background knowledge for solving a class of Analogical Reasoning problems where the set of attributes and possible relations across them are known apriori. We take inspiration from the 'neural algorithmic reasoning' approach [DeepMind 2020] and use problem-specific background knowledge by (i) learning a distributed representation based on a symbolic model of the problem (ii) training neural-network transformations reflective of the relations involved in the problem and finally (iii) training a neural network encoder from images to the distributed representation in (i). These three elements enable us to perform search-based reasoning using neural networks as elementary functions manipulating distributed representations. We test this on visual analogy problems in RAVENs Progressive Matrices, and achieve accuracy competitive with human performance and, in certain cases, superior to initial end-to-end neural-network based approaches. While recent neural models trained at scale yield SOTA, our novel neuro-symbolic reasoning approach is a promising direction for this problem, and is arguably more general, especially for problems where domain knowledge is available.
Machine Learning in Sports: A Case Study on Using Explainable Models for Predicting Outcomes of Volleyball Matches
Jun 18, 2022


Machine Learning has become an integral part of engineering design and decision making in several domains, including sports. Deep Neural Networks (DNNs) have been the state-of-the-art methods for predicting outcomes of professional sports events. However, apart from getting highly accurate predictions on these sports events outcomes, it is necessary to answer questions such as "Why did the model predict that Team A would win Match X against Team B?" DNNs are inherently black-box in nature. Therefore, it is required to provide high-quality interpretable, and understandable explanations for a model's prediction in sports. This paper explores a two-phased Explainable Artificial Intelligence(XAI) approach to predict outcomes of matches in the Brazilian volleyball League (SuperLiga). In the first phase, we directly use the interpretable rule-based ML models that provide a global understanding of the model's behaviors based on Boolean Rule Column Generation (BRCG; extracts simple AND-OR classification rules) and Logistic Regression (LogReg; allows to estimate the feature importance scores). In the second phase, we construct non-linear models such as Support Vector Machine (SVM) and Deep Neural Network (DNN) to obtain predictive performance on the volleyball matches' outcomes. We construct the "post-hoc" explanations for each data instance using ProtoDash, a method that finds prototypes in the training dataset that are most similar to the test instance, and SHAP, a method that estimates the contribution of each feature on the model's prediction. We evaluate the SHAP explanations using the faithfulness metric. Our results demonstrate the effectiveness of the explanations for the model's predictions.
Composition of Relational Features with an Application to Explaining Black-Box Predictors
Jun 01, 2022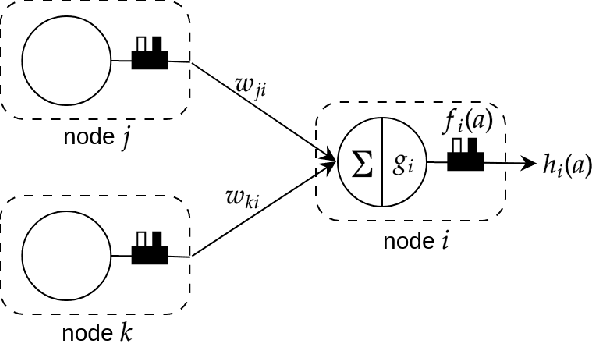


Relational machine learning programs like those developed in Inductive Logic Programming (ILP) offer several advantages: (1) The ability to model complex relationships amongst data instances; (2) The use of domain-specific relations during model construction; and (3) The models constructed are human-readable, which is often one step closer to being human-understandable. However, these ILP-like methods have not been able to capitalise fully on the rapid hardware, software and algorithmic developments fuelling current developments in deep neural networks. In this paper, we treat relational features as functions and use the notion of generalised composition of functions to derive complex functions from simpler ones. We formulate the notion of a set of $\text{M}$-simple features in a mode language $\text{M}$ and identify two composition operators ($\rho_1$ and $\rho_2$) from which all possible complex features can be derived. We use these results to implement a form of "explainable neural network" called Compositional Relational Machines, or CRMs, which are labelled directed-acyclic graphs. The vertex-label for any vertex $j$ in the CRM contains a feature-function $f_j$ and a continuous activation function $g_j$. If $j$ is a "non-input" vertex, then $f_j$ is the composition of features associated with vertices in the direct predecessors of $j$. Our focus is on CRMs in which input vertices (those without any direct predecessors) all have $\text{M}$-simple features in their vertex-labels. We provide a randomised procedure for constructing and learning such CRMs. Using a notion of explanations based on the compositional structure of features in a CRM, we provide empirical evidence on synthetic data of the ability to identify appropriate explanations; and demonstrate the use of CRMs as 'explanation machines' for black-box models that do not provide explanations for their predictions.
Solving Visual Analogies Using Neural Algorithmic Reasoning
Nov 19, 2021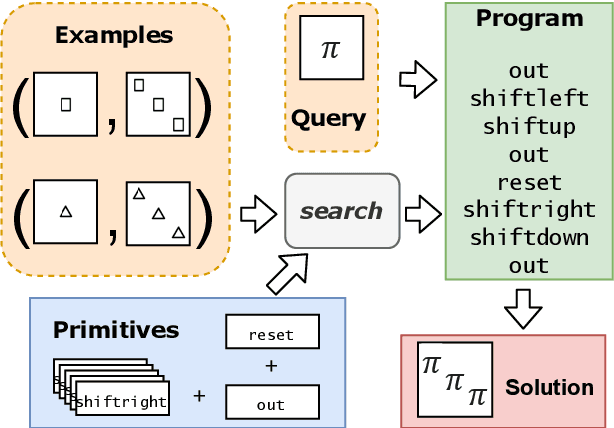

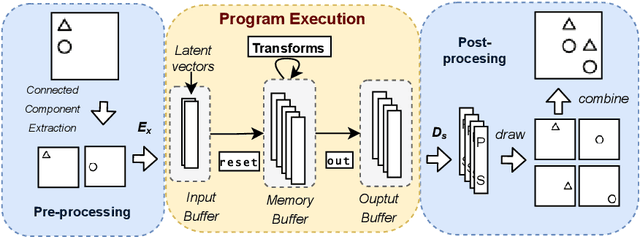
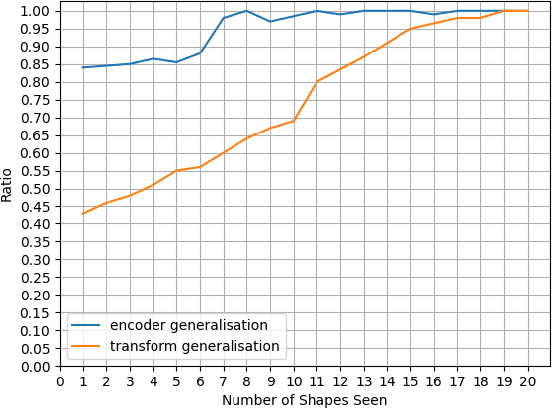
We consider a class of visual analogical reasoning problems that involve discovering the sequence of transformations by which pairs of input/output images are related, so as to analogously transform future inputs. This program synthesis task can be easily solved via symbolic search. Using a variation of the `neural analogical reasoning' approach of (Velickovic and Blundell 2021), we instead search for a sequence of elementary neural network transformations that manipulate distributed representations derived from a symbolic space, to which input images are directly encoded. We evaluate the extent to which our `neural reasoning' approach generalizes for images with unseen shapes and positions.
Using Program Synthesis and Inductive Logic Programming to solve Bongard Problems
Oct 19, 2021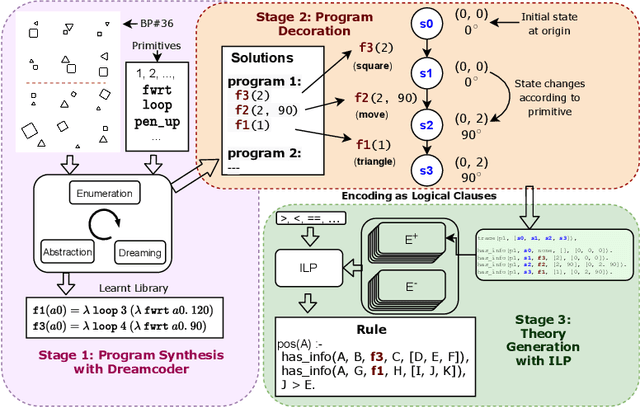

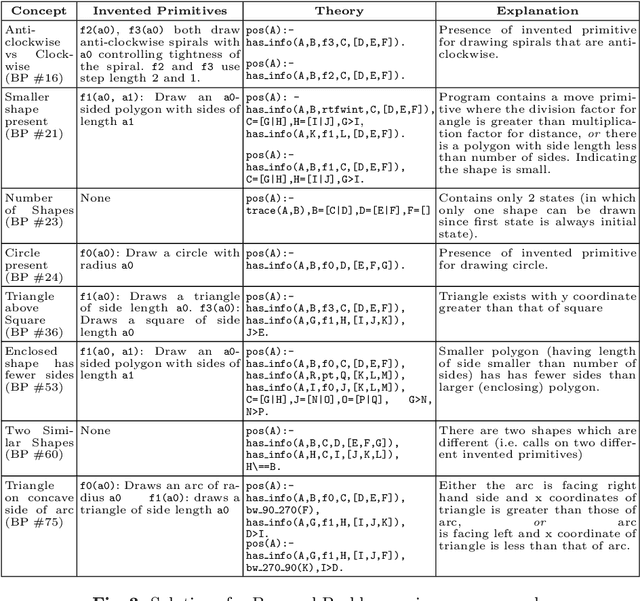
The ability to recognise and make analogies is often used as a measure or test of human intelligence. The ability to solve Bongard problems is an example of such a test. It has also been postulated that the ability to rapidly construct novel abstractions is critical to being able to solve analogical problems. Given an image, the ability to construct a program that would generate that image is one form of abstraction, as exemplified in the Dreamcoder project. In this paper, we present a preliminary examination of whether programs constructed by Dreamcoder can be used for analogical reasoning to solve certain Bongard problems. We use Dreamcoder to discover programs that generate the images in a Bongard problem and represent each of these as a sequence of state transitions. We decorate the states using positional information in an automated manner and then encode the resulting sequence into logical facts in Prolog. We use inductive logic programming (ILP), to learn an (interpretable) theory for the abstract concept involved in an instance of a Bongard problem. Experiments on synthetically created Bongard problems for concepts such as 'above/below' and 'clockwise/counterclockwise' demonstrate that our end-to-end system can solve such problems. We study the importance and completeness of each component of our approach, highlighting its current limitations and pointing to directions for improvement in our formulation as well as in elements of any Dreamcoder-like program synthesis system used for such an approach.
How to Tell Deep Neural Networks What We Know
Jul 21, 2021
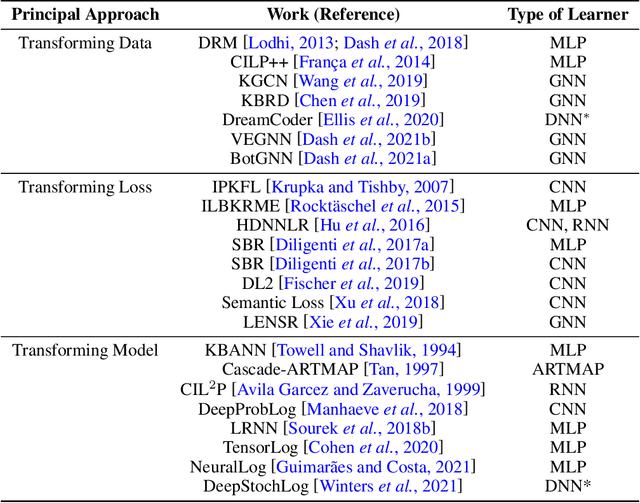
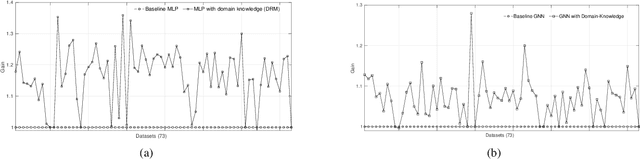
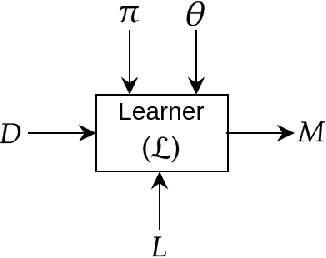
We present a short survey of ways in which existing scientific knowledge are included when constructing models with neural networks. The inclusion of domain-knowledge is of special interest not just to constructing scientific assistants, but also, many other areas that involve understanding data using human-machine collaboration. In many such instances, machine-based model construction may benefit significantly from being provided with human-knowledge of the domain encoded in a sufficiently precise form. This paper examines the inclusion of domain-knowledge by means of changes to: the input, the loss-function, and the architecture of deep networks. The categorisation is for ease of exposition: in practice we expect a combination of such changes will be employed. In each category, we describe techniques that have been shown to yield significant changes in network performance.
Inclusion of Domain-Knowledge into GNNs using Mode-Directed Inverse Entailment
May 22, 2021
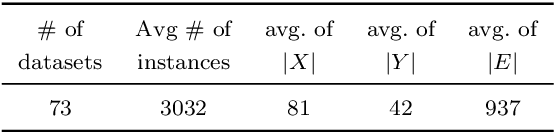


We present a general technique for constructing Graph Neural Networks (GNNs) capable of using multi-relational domain knowledge. The technique is based on mode-directed inverse entailment (MDIE) developed in Inductive Logic Programming (ILP). Given a data instance $e$ and background knowledge $B$, MDIE identifies a most-specific logical formula $\bot_B(e)$ that contains all the relational information in $B$ that is related to $e$. We transform $\bot_B(e)$ into a corresponding "bottom-graph" that can be processed for use by standard GNN implementations. This transformation allows a principled way of incorporating generic background knowledge into GNNs: we use the term `BotGNN' for this form of graph neural networks. For several GNN variants, using real-world datasets with substantial background knowledge, we show that BotGNNs perform significantly better than both GNNs without background knowledge and a recently proposed simplified technique for including domain knowledge into GNNs. We also provide experimental evidence comparing BotGNNs favourably to multi-layer perceptrons (MLPs) that use features representing a "propositionalised" form of the background knowledge; and BotGNNs to a standard ILP based on the use of most-specific clauses. Taken together, these results point to BotGNNs as capable of combining the computational efficacy of GNNs with the representational versatility of ILP.