 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeystroke Dynamics Against Academic Dishonesty in the Age of LLMs
Jun 21, 2024



The transition to online examinations and assignments raises significant concerns about academic integrity. Traditional plagiarism detection systems often struggle to identify instances of intelligent cheating, particularly when students utilize advanced generative AI tools to craft their responses. This study proposes a keystroke dynamics-based method to differentiate between bona fide and assisted writing within academic contexts. To facilitate this, a dataset was developed to capture the keystroke patterns of individuals engaged in writing tasks, both with and without the assistance of generative AI. The detector, trained using a modified TypeNet architecture, achieved accuracies ranging from 74.98% to 85.72% in condition-specific scenarios and from 52.24% to 80.54% in condition-agnostic scenarios. The findings highlight significant differences in keystroke dynamics between genuine and assisted writing. The outcomes of this study enhance our understanding of how users interact with generative AI and have implications for improving the reliability of digital educational platforms.
MM-PhyRLHF: Reinforcement Learning Framework for Multimodal Physics Question-Answering
Apr 19, 2024



Recent advancements in LLMs have shown their significant potential in tasks like text summarization and generation. Yet, they often encounter difficulty while solving complex physics problems that require arithmetic calculation and a good understanding of concepts. Moreover, many physics problems include images that contain important details required to understand the problem's context. We propose an LMM-based chatbot to answer multimodal physics MCQs. For domain adaptation, we utilize the MM-PhyQA dataset comprising Indian high school-level multimodal physics problems. To improve the LMM's performance, we experiment with two techniques, RLHF (Reinforcement Learning from Human Feedback) and Image Captioning. In image captioning, we add a detailed explanation of the diagram in each image, minimizing hallucinations and image processing errors. We further explore the integration of Reinforcement Learning from Human Feedback (RLHF) methodology inspired by the ranking approach in RLHF to enhance the human-like problem-solving abilities of the models. The RLHF approach incorporates human feedback into the learning process of LLMs, improving the model's problem-solving skills, truthfulness, and reasoning capabilities, minimizing the hallucinations in the answers, and improving the quality instead of using vanilla-supervised fine-tuned models. We employ the LLaVA open-source model to answer multimodal physics MCQs and compare the performance with and without using RLHF.
MM-PhyQA: Multimodal Physics Question-Answering With Multi-Image CoT Prompting
Apr 11, 2024While Large Language Models (LLMs) can achieve human-level performance in various tasks, they continue to face challenges when it comes to effectively tackling multi-step physics reasoning tasks. To identify the shortcomings of existing models and facilitate further research in this area, we curated a novel dataset, MM-PhyQA, which comprises well-constructed, high schoollevel multimodal physics problems. By evaluating the performance of contemporary LLMs that are publicly available, both with and without the incorporation of multimodal elements in these problems, we aim to shed light on their capabilities. For generating answers for questions consisting of multimodal input (in this case, images and text) we employed Zero-shot prediction using GPT-4 and utilized LLaVA (LLaVA and LLaVA-1.5), the latter of which were fine-tuned on our dataset. For evaluating the performance of LLMs consisting solely of textual input, we tested the performance of the base and fine-tuned versions of the Mistral-7B and LLaMA2-7b models. We also showcased the performance of the novel Multi-Image Chain-of-Thought (MI-CoT) Prompting technique, which when used to train LLaVA-1.5 13b yielded the best results when tested on our dataset, with superior scores in most metrics and the highest accuracy of 71.65% on the test set.
Generative AI in Vision: A Survey on Models, Metrics and Applications
Feb 26, 2024



Generative AI models have revolutionized various fields by enabling the creation of realistic and diverse data samples. Among these models, diffusion models have emerged as a powerful approach for generating high-quality images, text, and audio. This survey paper provides a comprehensive overview of generative AI diffusion and legacy models, focusing on their underlying techniques, applications across different domains, and their challenges. We delve into the theoretical foundations of diffusion models, including concepts such as denoising diffusion probabilistic models (DDPM) and score-based generative modeling. Furthermore, we explore the diverse applications of these models in text-to-image, image inpainting, and image super-resolution, along with others, showcasing their potential in creative tasks and data augmentation. By synthesizing existing research and highlighting critical advancements in this field, this survey aims to provide researchers and practitioners with a comprehensive understanding of generative AI diffusion and legacy models and inspire future innovations in this exciting area of artificial intelligence.
A Review on Objective-Driven Artificial Intelligence
Aug 20, 2023



While advancing rapidly, Artificial Intelligence still falls short of human intelligence in several key aspects due to inherent limitations in current AI technologies and our understanding of cognition. Humans have an innate ability to understand context, nuances, and subtle cues in communication, which allows us to comprehend jokes, sarcasm, and metaphors. Machines struggle to interpret such contextual information accurately. Humans possess a vast repository of common-sense knowledge that helps us make logical inferences and predictions about the world. Machines lack this innate understanding and often struggle with making sense of situations that humans find trivial. In this article, we review the prospective Machine Intelligence candidates, a review from Prof. Yann LeCun, and other work that can help close this gap between human and machine intelligence. Specifically, we talk about what's lacking with the current AI techniques such as supervised learning, reinforcement learning, self-supervised learning, etc. Then we show how Hierarchical planning-based approaches can help us close that gap and deep-dive into energy-based, latent-variable methods and Joint embedding predictive architecture methods.
Training Strategies for Vision Transformers for Object Detection
Apr 05, 2023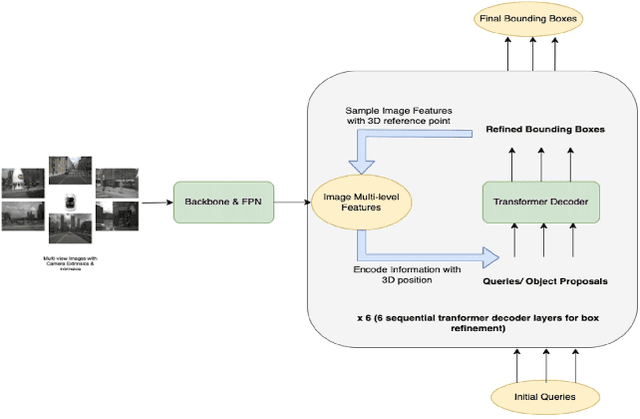


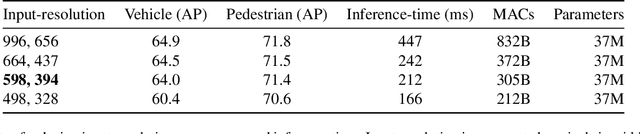
Vision-based Transformer have shown huge application in the perception module of autonomous driving in terms of predicting accurate 3D bounding boxes, owing to their strong capability in modeling long-range dependencies between the visual features. However Transformers, initially designed for language models, have mostly focused on the performance accuracy, and not so much on the inference-time budget. For a safety critical system like autonomous driving, real-time inference at the on-board compute is an absolute necessity. This keeps our object detection algorithm under a very tight run-time budget. In this paper, we evaluated a variety of strategies to optimize on the inference-time of vision transformers based object detection methods keeping a close-watch on any performance variations. Our chosen metric for these strategies is accuracy-runtime joint optimization. Moreover, for actual inference-time analysis we profile our strategies with float32 and float16 precision with TensorRT module. This is the most common format used by the industry for deployment of their Machine Learning networks on the edge devices. We showed that our strategies are able to improve inference-time by 63% at the cost of performance drop of mere 3% for our problem-statement defined in evaluation section. These strategies brings down Vision Transformers detectors inference-time even less than traditional single-image based CNN detectors like FCOS. We recommend practitioners use these techniques to deploy Transformers based hefty multi-view networks on a budge-constrained robotic platform.
Trajectory-Prediction with Vision: A Survey
Mar 15, 2023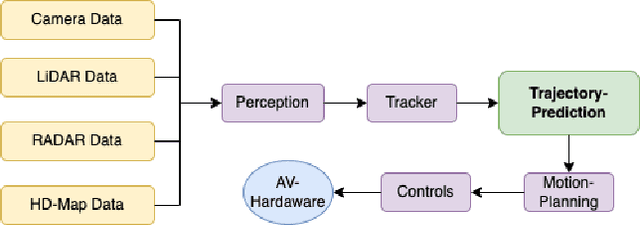
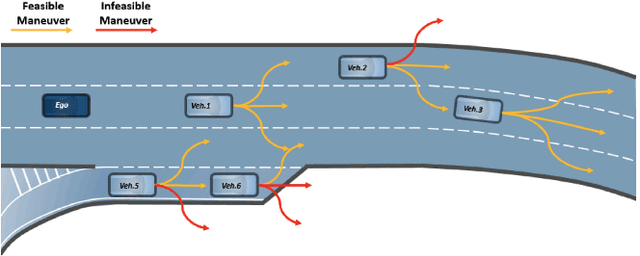
To plan a safe and efficient route, an autonomous vehicle should anticipate future trajectories of other agents around it. Trajectory prediction is an extremely challenging task which recently gained a lot of attention in the autonomous vehicle research community. Trajectory-prediction forecasts future state of all the dynamic agents in the scene given their current and past states. A good prediction model can prevent collisions on the road, and hence the ultimate goal for autonomous vehicles: Collision rate: collisions per Million miles. The objective of this paper is to provide an overview of the field trajectory-prediction. We categorize the relevant algorithms into different classes so that researchers can follow through the trends in the trajectory-prediction research field. Moreover we also touch upon the background knowledge required to formulate a trajectory-prediction problem.
Transformer-Based Sensor Fusion for Autonomous Driving: A Survey
Feb 22, 2023

Sensor fusion is an essential topic in many perception systems, such as autonomous driving and robotics. Transformers-based detection head and CNN-based feature encoder to extract features from raw sensor-data has emerged as one of the best performing sensor-fusion 3D-detection-framework, according to the dataset leaderboards. In this work we provide an in-depth literature survey of transformer based 3D-object detection task in the recent past, primarily focusing on the sensor fusion. We also briefly go through the Vision transformers (ViT) basics, so that readers can easily follow through the paper. Moreover, we also briefly go through few of the non-transformer based less-dominant methods for sensor fusion for autonomous driving. In conclusion we summarize with sensor-fusion trends to follow and provoke future research. More updated summary can be found at: https://github.com/ApoorvRoboticist/Transformers-Sensor-Fusion
3M3D: Multi-view, Multi-path, Multi-representation for 3D Object Detection
Feb 16, 2023



3D visual perception tasks based on multi-camera images are essential for autonomous driving systems. Latest work in this field performs 3D object detection by leveraging multi-view images as an input and iteratively enhancing object queries (object proposals) by cross-attending multi-view features. However, individual backbone features are not updated with multi-view features and it stays as a mere collection of the output of the single-image backbone network. Therefore we propose 3M3D: A Multi-view, Multi-path, Multi-representation for 3D Object Detection where we update both multi-view features and query features to enhance the representation of the scene in both fine panoramic view and coarse global view. Firstly, we update multi-view features by multi-view axis self-attention. It will incorporate panoramic information in the multi-view features and enhance understanding of the global scene. Secondly, we update multi-view features by self-attention of the ROI (Region of Interest) windows which encodes local finer details in the features. It will help exchange the information not only along the multi-view axis but also along the other spatial dimension. Lastly, we leverage the fact of multi-representation of queries in different domains to further boost the performance. Here we use sparse floating queries along with dense BEV (Bird's Eye View) queries, which are later post-processed to filter duplicate detections. Moreover, we show performance improvements on nuScenes benchmark dataset on top of our baselines.
Vision-RADAR fusion for Robotics BEV Detections: A Survey
Feb 13, 2023Due to the trending need of building autonomous robotic perception system, sensor fusion has attracted a lot of attention amongst researchers and engineers to make best use of cross-modality information. However, in order to build a robotic platform at scale we need to emphasize on autonomous robot platform bring-up cost as well. Cameras and radars, which inherently includes complementary perception information, has potential for developing autonomous robotic platform at scale. However, there is a limited work around radar fused with Vision, compared to LiDAR fused with vision work. In this paper, we tackle this gap with a survey on Vision-Radar fusion approaches for a BEV object detection system. First we go through the background information viz., object detection tasks, choice of sensors, sensor setup, benchmark datasets and evaluation metrics for a robotic perception system. Later, we cover per-modality (Camera and RADAR) data representation, then we go into detail about sensor fusion techniques based on sub-groups viz., early-fusion, deep-fusion, and late-fusion to easily understand the pros and cons of each method. Finally, we propose possible future trends for vision-radar fusion to enlighten future research. Regularly updated summary can be found at: https://github.com/ApoorvRoboticist/Vision-RADAR-Fusion-BEV-Survey