 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies for Vision Transformers for Object Detection
Paper and Code
Apr 05, 2023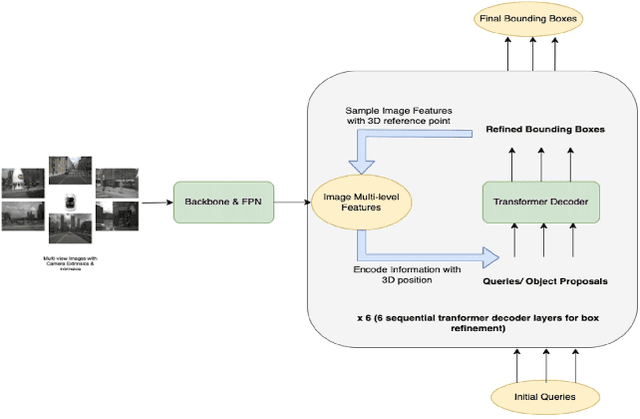


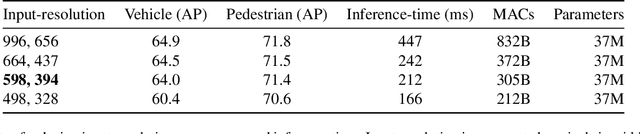
Vision-based Transformer have shown huge application in the perception module of autonomous driving in terms of predicting accurate 3D bounding boxes, owing to their strong capability in modeling long-range dependencies between the visual features. However Transformers, initially designed for language models, have mostly focused on the performance accuracy, and not so much on the inference-time budget. For a safety critical system like autonomous driving, real-time inference at the on-board compute is an absolute necessity. This keeps our object detection algorithm under a very tight run-time budget. In this paper, we evaluated a variety of strategies to optimize on the inference-time of vision transformers based object detection methods keeping a close-watch on any performance variations. Our chosen metric for these strategies is accuracy-runtime joint optimization. Moreover, for actual inference-time analysis we profile our strategies with float32 and float16 precision with TensorRT module. This is the most common format used by the industry for deployment of their Machine Learning networks on the edge devices. We showed that our strategies are able to improve inference-time by 63% at the cost of performance drop of mere 3% for our problem-statement defined in evaluation section. These strategies brings down Vision Transformers detectors inference-time even less than traditional single-image based CNN detectors like FCOS. We recommend practitioners use these techniques to deploy Transformers based hefty multi-view networks on a budge-constrained robotic platform.