 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3M3D: Multi-view, Multi-path, Multi-representation for 3D Object Detection
Feb 16, 2023



3D visual perception tasks based on multi-camera images are essential for autonomous driving systems. Latest work in this field performs 3D object detection by leveraging multi-view images as an input and iteratively enhancing object queries (object proposals) by cross-attending multi-view features. However, individual backbone features are not updated with multi-view features and it stays as a mere collection of the output of the single-image backbone network. Therefore we propose 3M3D: A Multi-view, Multi-path, Multi-representation for 3D Object Detection where we update both multi-view features and query features to enhance the representation of the scene in both fine panoramic view and coarse global view. Firstly, we update multi-view features by multi-view axis self-attention. It will incorporate panoramic information in the multi-view features and enhance understanding of the global scene. Secondly, we update multi-view features by self-attention of the ROI (Region of Interest) windows which encodes local finer details in the features. It will help exchange the information not only along the multi-view axis but also along the other spatial dimension. Lastly, we leverage the fact of multi-representation of queries in different domains to further boost the performance. Here we use sparse floating queries along with dense BEV (Bird's Eye View) queries, which are later post-processed to filter duplicate detections. Moreover, we show performance improvements on nuScenes benchmark dataset on top of our baselines.
Surround-View Vision-based 3D Detection for Autonomous Driving: A Survey
Feb 13, 2023Vision-based 3D Detection task is fundamental task for the perception of an autonomous driving system, which has peaked interest amongst many researchers and autonomous driving engineers. However achieving a rather good 3D BEV (Bird's Eye View) performance is not an easy task using 2D sensor input-data with cameras. In this paper we provide a literature survey for the existing Vision Based 3D detection methods, focused on autonomous driving. We have made detailed analysis of over $60$ papers leveraging Vision BEV detections approaches and highlighted different sub-groups for detailed understanding of common trends. Moreover, we have highlighted how the literature and industry trend have moved towards surround-view image based methods and note down thoughts on what special cases this method addresses. In conclusion, we provoke thoughts of 3D Vision techniques for future research based on shortcomings of the current techniques including the direction of collaborative perception.
nuScenes: A multimodal dataset for autonomous driving
Mar 26, 2019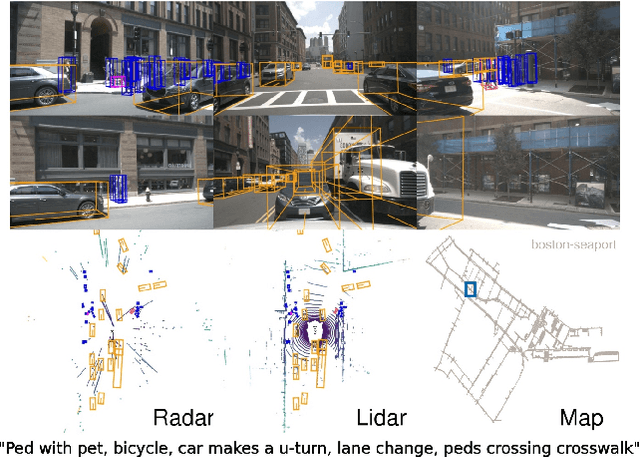
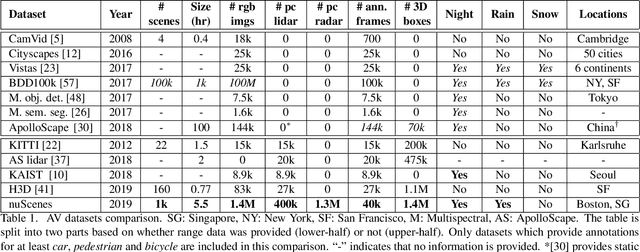


Robust detection and tracking of objects is crucial for the deployment of autonomous vehicle technology. Image-based benchmark datasets have driven the development in computer vision tasks such as object detection, tracking and segmentation of agents in the environment. Most autonomous vehicles, however, carry a combination of cameras and range sensors such as lidar and radar. As machine learning based methods for detection and tracking become more prevalent, there is a need to train and evaluate such methods on datasets containing range sensor data along with images. In this work we present nuTonomy scenes (nuScenes), the first dataset to carry the full autonomous vehicle sensor suite: 6 cameras, 5 radars and 1 lidar, all with full 360 degree field of view. nuScenes comprises 1000 scenes, each 20s long and fully annotated with 3D bounding boxes for 23 classes and 8 attributes. It has 7x as many annotations and 100x as many images as the pioneering KITTI dataset. We also define a new metric for 3D detection which consolidates the multiple aspects of the detection task: classification, localization, size, orientation, velocity and attribute estimation. We provide careful dataset analysis as well as baseline performance for lidar and image based detection methods. Data, development kit, and more information are available at www.nuscenes.org.