 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Vision Language Model for Autonomous Driving
Dec 30, 2025While Vision-Language Models (VLMs) show significant promise for end-to-end autonomous driving by leveraging the common sense embedded in language models, their reliance on 2D image cues for complex scene understanding and decision-making presents a critical bottleneck for safety and reliability. Current image-based methods struggle with accurate metric spatial reasoning and geometric inference, leading to unreliable driving policies. To bridge this gap, we propose LVLDrive (LiDAR-Vision-Language), a novel framework specifically designed to upgrade existing VLMs with robust 3D metric spatial understanding for autonomous driving by incoperating LiDAR point cloud as an extra input modality. A key challenge lies in mitigating the catastrophic disturbance introduced by disparate 3D data to the pre-trained VLMs. To this end, we introduce a Gradual Fusion Q-Former that incrementally injects LiDAR features, ensuring the stability and preservation of the VLM's existing knowledge base. Furthermore, we develop a spatial-aware question-answering (SA-QA) dataset to explicitly teach the model advanced 3D perception and reasoning capabilities. Extensive experiments on driving benchmarks demonstrate that LVLDrive achieves superior performance compared to vision-only counterparts across scene understanding, metric spatial perception, and reliable driving decision-making. Our work highlights the necessity of explicit 3D metric data for building trustworthy VLM-based autonomous systems.
ConDA: Unsupervised Domain Adaptation for LiDAR Segmentation via Regularized Domain Concatenation
Nov 30, 2021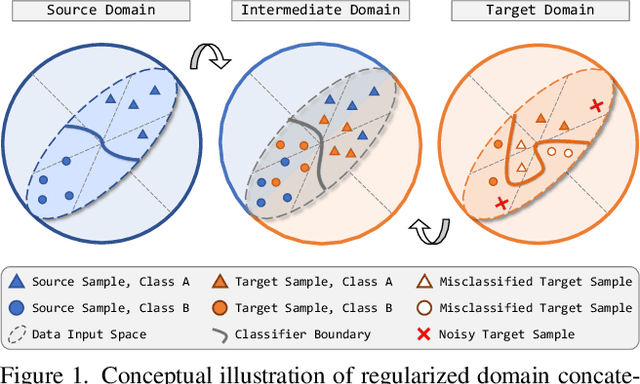
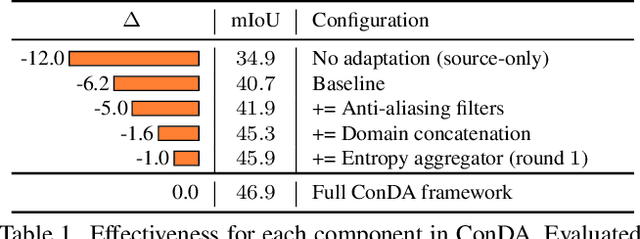
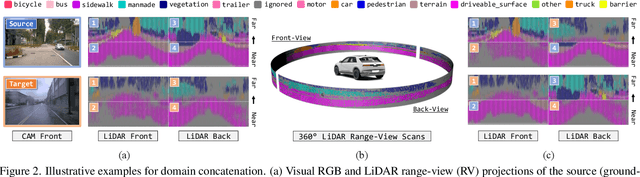

Transferring knowledge learned from the labeled source domain to the raw target domain for unsupervised domain adaptation (UDA) is essential to the scalable deployment of an autonomous driving system. State-of-the-art approaches in UDA often employ a key concept: utilize joint supervision signals from both the source domain (with ground-truth) and the target domain (with pseudo-labels) for self-training. In this work, we improve and extend on this aspect. We present ConDA, a concatenation-based domain adaptation framework for LiDAR semantic segmentation that: (1) constructs an intermediate domain consisting of fine-grained interchange signals from both source and target domains without destabilizing the semantic coherency of objects and background around the ego-vehicle; and (2) utilizes the intermediate domain for self-training. Additionally, to improve both the network training on the source domain and self-training on the intermediate domain, we propose an anti-aliasing regularizer and an entropy aggregator to reduce the detrimental effects of aliasing artifacts and noisy target predictions. Through extensive experiments, we demonstrate that ConDA is significantly more effective in mitigating the domain gap compared to prior arts.
AMVNet: Assertion-based Multi-View Fusion Network for LiDAR Semantic Segmentation
Dec 09, 2020
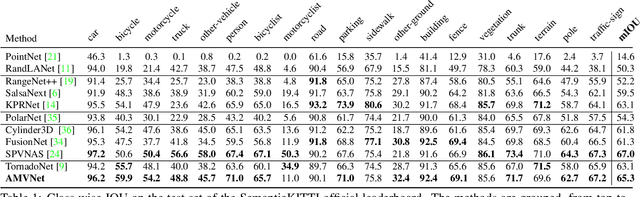
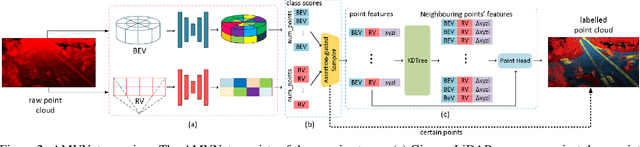

In this paper, we present an Assertion-based Multi-View Fusion network (AMVNet) for LiDAR semantic segmentation which aggregates the semantic features of individual projection-based networks using late fusion. Given class scores from different projection-based networks, we perform assertion-guided point sampling on score disagreements and pass a set of point-level features for each sampled point to a simple point head which refines the predictions. This modular-and-hierarchical late fusion approach provides the flexibility of having two independent networks with a minor overhead from a light-weight network. Such approaches are desirable for robotic systems, e.g. autonomous vehicles, for which the computational and memory resources are often limited. Extensive experiments show that AMVNet achieves state-of-the-art results in both the SemanticKITTI and nuScenes benchmark datasets and that our approach outperforms the baseline method of combining the class scores of the projection-based networks.
nuScenes: A multimodal dataset for autonomous driving
Mar 26, 2019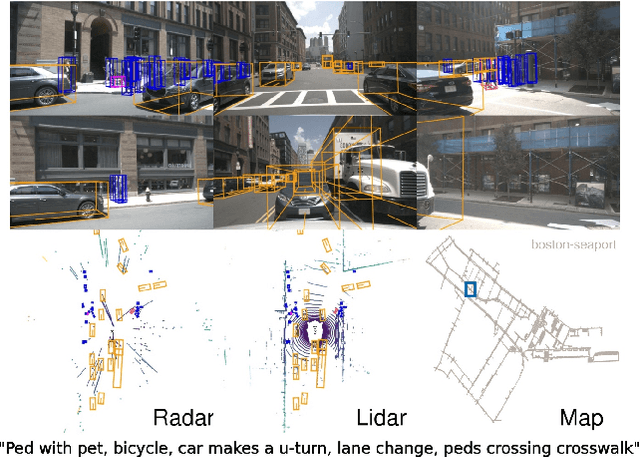
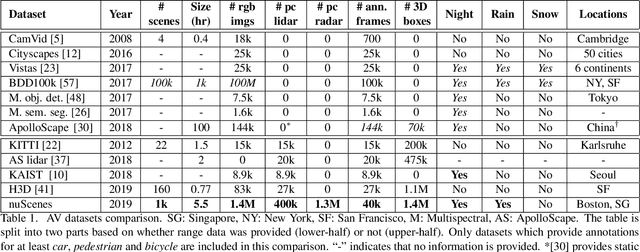


Robust detection and tracking of objects is crucial for the deployment of autonomous vehicle technology. Image-based benchmark datasets have driven the development in computer vision tasks such as object detection, tracking and segmentation of agents in the environment. Most autonomous vehicles, however, carry a combination of cameras and range sensors such as lidar and radar. As machine learning based methods for detection and tracking become more prevalent, there is a need to train and evaluate such methods on datasets containing range sensor data along with images. In this work we present nuTonomy scenes (nuScenes), the first dataset to carry the full autonomous vehicle sensor suite: 6 cameras, 5 radars and 1 lidar, all with full 360 degree field of view. nuScenes comprises 1000 scenes, each 20s long and fully annotated with 3D bounding boxes for 23 classes and 8 attributes. It has 7x as many annotations and 100x as many images as the pioneering KITTI dataset. We also define a new metric for 3D detection which consolidates the multiple aspects of the detection task: classification, localization, size, orientation, velocity and attribute estimation. We provide careful dataset analysis as well as baseline performance for lidar and image based detection methods. Data, development kit, and more information are available at www.nuscenes.org.