 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORGE: Fused On-Register Gradient Elimination for Memory-Efficient LLM Training
Jun 22, 2026Reverse-mode differentiation computes every weight gradient, writes it to memory, and only then lets the optimizer read it back. This two-phase schedule sets the memory ceiling of modern training: at the seam between the phases, every layer's gradient is live at once. We argue that this materialized gradient is an artifact of how differentiation is staged, not a quantity that learning requires -- and we eliminate it. FORGE folds the optimizer step into the backward pass and applies it one tile at a time, entirely in registers, so each gradient tile is consumed the instant it is produced and never becomes a tensor. The fusion changes only when the update happens, not what it computes: in full precision the fused step is provably exact -- the identical optimizer update, for every element-wise rule -- and that exactness survives tensor- and sequence-parallel sharding; in the bf16 and 8-bit regimes used in practice it is faithful rather than bit-identical, its deviation bounded and, for the weight store, rendered unbiased by stochastic rounding. Because each gradient tile is born and consumed in the same registers, it is never converted down to bf16 to be stored and read back; FORGE thus preserves the full-precision fidelity that both bf16 and 8-bit optimizers lose to that conversion. Nor is the method tied to one architecture or one optimizer: linear layers are ubiquitous, and FORGE reclaims the gradient memory of any of them under any element-wise rule. Empirically FORGE more than halves the memory of an optimizer step and, at the small batch sizes typical of fine-tuning and continued pretraining, runs about 1.5x faster; integrated into tensor-parallel Megatron-LM it fits 8B training at four times the micro-batch a standard optimizer allows on the same GPUs.
The Periodic Table of LLM Reasoning: A Structured Survey of Reasoning Paradigms, Methods, and Failure Modes
Jun 09, 2026Large Language Models (LLMs) have achieved strong performance across natural language processing tasks, yet reliable reasoning remains an open challenge. Although modern LLMs show progress in structured inference, multi-step problem solving, and contextual understanding, their reasoning behavior is often inconsistent and sensitive to prompting strategies, task design, and model scale. This survey provides a systematic analysis of more than 300 recent papers from arXiv, Semantic Scholar, Google Scholar, Papers with Code, and the ACL Anthology to examine how reasoning capabilities emerge in LLMs and where they fail. We make three main contributions. First, we introduce a structured taxonomy of LLM reasoning research, covering Chain-of-Thought reasoning, multi-hop reasoning, mathematical reasoning, common sense reasoning, visual and temporal reasoning, code and algorithmic reasoning, retrieval-augmented reasoning, tool-augmented and agentic reasoning, and reinforcement learning-based reasoning. Second, we analyze methodological trends across these paradigms, including prompting methods, model architectures, training objectives, reward modeling, and evaluation benchmarks. Third, we synthesize recurring limitations and failure modes, such as reasoning hallucinations, brittle multi-step inference, weak causal abstraction, and poor cross-domain generalization. By organizing a rapidly expanding literature, this survey offers a unified view of the current capabilities and limitations of reasoning in LLMs. We also identify emerging research directions, including meta-reasoning, self-evolving reasoning frameworks, multimodal reasoning, and socially grounded reasoning. Overall, this work aims to serve as a reference for developing more robust, interpretable, and generalizable reasoning systems in future language models.
IRIS: Interleaved Reinforcement with Incremental Staged Curriculum for Cross-Lingual Mathematical Reasoning
Apr 27, 2026Curriculum learning helps language models tackle complex reasoning by gradually increasing task difficulty. However, it often fails to generate consistent step-by-step reasoning, especially in multilingual and low-resource settings where cross-lingual transfer from English to Indian languages remains limited. We propose IRIS: Interleaved Reinforcement with Incremental Staged Curriculum, a two-axis framework that combines Supervised Fine-Tuning on progressively harder problems (vertical axis) with Reverse Curriculum Reinforcement Learning to reduce reliance on step-by-step guidance (horizontal axis). We design a composite reward combining correctness, step-wise alignment, continuity, and numeric incentives, optimized via Group Relative Policy Optimization (GRPO). We release CL-Math, a dataset of 29k problems with step-level annotations in English, Hindi, and Marathi. Across standard benchmarks and curated multilingual test sets, IRIS consistently improves performance, with strong results on math reasoning tasks and substantial gains in low-resource and bilingual settings, alongside modest improvements in high-resource languages.
Psychologically-Grounded Graph Modeling for Interpretable Depression Detection
Apr 27, 2026Automatic depression detection from conversational interactions holds significant promise for scalable screening but remains hindered by severe data scarcity and a lack of clinical interpretability. Existing approaches typically rely on black-box deep learning architectures that struggle to model the subtle, temporal evolution of depressive symptoms or account for participant-specific heterogeneity. In this work, we propose PsyGAT (Psychological Graph Attention Network), a psychologically grounded framework that models conversational sessions as dynamic temporal graphs. We introduce Psychological Expression Units (PEUs) to explicitly encode utterance-level clinical evidence, structuring the session graph to capture transitions in psychological states rather than mere semantic dependencies. To address the critical class imbalance in depression datasets, we employ clinically approved persona-based data augmentation, enable robust model learning. Additionally, we integrate session-level personality context directly into the graph structure to disentangle trait-based behavior from acute depressive symptoms. PsyGAT achieves state-of-the-art performance, surpassing both strong graph-based baselines and closed-source LLMs like GPT-5, achieving 89.99 and 71.37 Macro F1 scores in DAIC-WoZ and E-DAIC, respectively. We further introduce Causal-PsyGAT, an interpretability module that identifies symptom triggers. Experiments show a 20% improvement in MRR for identifying causal indicators, effectively bridging the gap between depression monitoring and clinical explainability. The full augmented dataset is publicly available at https://doi.org/10.6084/m9.figshare.31801921.
Better and Worse with Scale: How Contextual Entrainment Diverges with Model Size
Apr 14, 2026Larger language models become simultaneously better and worse at handling contextual information -- better at ignoring false claims, worse at ignoring irrelevant tokens. We formalize this apparent paradox through the first scaling laws for contextual entrainment, the tendency of models to favor tokens that appeared in context regardless of relevance. Analyzing the Cerebras-GPT (111M-13B) and Pythia (410M-12B) model families, we find entrainment follows predictable power-law scaling, but with opposite trends depending on context type: semantic contexts show decreasing entrainment with scale, while non-semantic contexts show increasing entrainment. Concretely, the largest models are four times more resistant to counterfactual misinformation than the smallest, yet simultaneously twice as prone to copying arbitrary tokens. These diverging trends, which replicate across model families, suggest that semantic filtering and mechanical copying are functionally distinct behaviors that scale in opposition -- scaling alone does not resolve context sensitivity, it reshapes it.
Multilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
Dec 24, 2024



Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini's accuracy on English datasets by +6% and matches Gemini's performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.
Knowledge Graphs are all you need: Leveraging KGs in Physics Question Answering
Dec 06, 2024



This study explores the effectiveness of using knowledge graphs generated by large language models to decompose high school-level physics questions into sub-questions. We introduce a pipeline aimed at enhancing model response quality for Question Answering tasks. By employing LLMs to construct knowledge graphs that capture the internal logic of the questions, these graphs then guide the generation of subquestions. We hypothesize that this method yields sub-questions that are more logically consistent with the original questions compared to traditional decomposition techniques. Our results show that sub-questions derived from knowledge graphs exhibit significantly improved fidelity to the original question's logic. This approach not only enhances the learning experience by providing clearer and more contextually appropriate sub-questions but also highlights the potential of LLMs to transform educational methodologies. The findings indicate a promising direction for applying AI to improve the quality and effectiveness of educational content.
Steps are all you need: Rethinking STEM Education with Prompt Engineering
Dec 06, 2024Few shot and Chain-of-Thought prompting have shown promise when applied to Physics Question Answering Tasks, but are limited by the lack of mathematical ability inherent to LLMs, and are prone to hallucination. By utilizing a Mixture of Experts (MoE) Model, along with analogical prompting, we are able to show improved model performance when compared to the baseline on standard LLMs. We also survey the limits of these prompting techniques and the effects they have on model performance. Additionally, we propose Analogical CoT prompting, a prompting technique designed to allow smaller, open source models to leverage Analogical prompting, something they have struggled with, possibly due to a lack of specialist training data.
Enhancing LLMs for Physics Problem-Solving using Reinforcement Learning with Human-AI Feedback
Dec 06, 2024
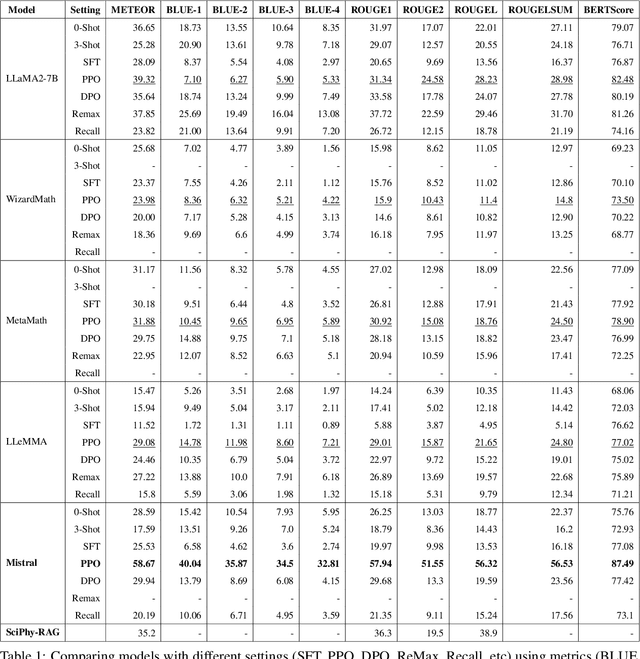
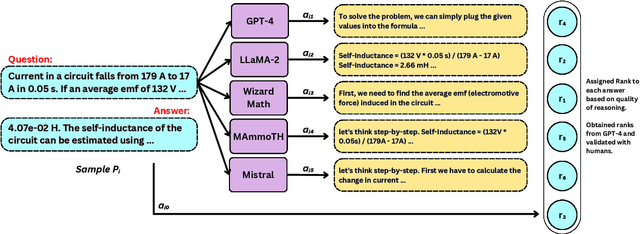
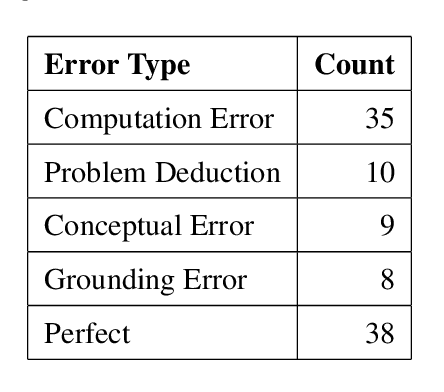
Large Language Models (LLMs) have demonstrated strong capabilities in text-based tasks but struggle with the complex reasoning required for physics problems, particularly in advanced arithmetic and conceptual understanding. While some research has explored ways to enhance LLMs in physics education using techniques such as prompt engineering and Retrieval Augmentation Generation (RAG), not enough effort has been made in addressing their limitations in physics reasoning. This paper presents a novel approach to improving LLM performance on physics questions using Reinforcement Learning with Human and Artificial Intelligence Feedback (RLHAIF). We evaluate several reinforcement learning methods, including Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), and Remax optimization. These methods are chosen to investigate RL policy performance with different settings on the PhyQA dataset, which includes challenging physics problems from high school textbooks. Our RLHAIF model, tested on leading LLMs like LLaMA2 and Mistral, achieved superior results, notably with the MISTRAL-PPO model, demonstrating marked improvements in reasoning and accuracy. It achieved high scores, with a 58.67 METEOR score and a 0.74 Reasoning score, making it a strong example for future physics reasoning research in this area.
Su-RoBERTa: A Semi-supervised Approach to Predicting Suicide Risk through Social Media using Base Language Models
Dec 02, 2024



In recent times, more and more people are posting about their mental states across various social media platforms. Leveraging this data, AI-based systems can be developed that help in assessing the mental health of individuals, such as suicide risk. This paper is a study done on suicidal risk assessments using Reddit data leveraging Base language models to identify patterns from social media posts. We have demonstrated that using smaller language models, i.e., less than 500M parameters, can also be effective in contrast to LLMs with greater than 500M parameters. We propose Su-RoBERTa, a fine-tuned RoBERTa on suicide risk prediction task that utilized both the labeled and unlabeled Reddit data and tackled class imbalance by data augmentation using GPT-2 model. Our Su-RoBERTa model attained a 69.84% weighted F1 score during the Final evaluation. This paper demonstrates the effectiveness of Base language models for the analysis of the risk factors related to mental health with an efficient computation pipeline