 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychologically-Grounded Graph Modeling for Interpretable Depression Detection
Apr 27, 2026Automatic depression detection from conversational interactions holds significant promise for scalable screening but remains hindered by severe data scarcity and a lack of clinical interpretability. Existing approaches typically rely on black-box deep learning architectures that struggle to model the subtle, temporal evolution of depressive symptoms or account for participant-specific heterogeneity. In this work, we propose PsyGAT (Psychological Graph Attention Network), a psychologically grounded framework that models conversational sessions as dynamic temporal graphs. We introduce Psychological Expression Units (PEUs) to explicitly encode utterance-level clinical evidence, structuring the session graph to capture transitions in psychological states rather than mere semantic dependencies. To address the critical class imbalance in depression datasets, we employ clinically approved persona-based data augmentation, enable robust model learning. Additionally, we integrate session-level personality context directly into the graph structure to disentangle trait-based behavior from acute depressive symptoms. PsyGAT achieves state-of-the-art performance, surpassing both strong graph-based baselines and closed-source LLMs like GPT-5, achieving 89.99 and 71.37 Macro F1 scores in DAIC-WoZ and E-DAIC, respectively. We further introduce Causal-PsyGAT, an interpretability module that identifies symptom triggers. Experiments show a 20% improvement in MRR for identifying causal indicators, effectively bridging the gap between depression monitoring and clinical explainability. The full augmented dataset is publicly available at https://doi.org/10.6084/m9.figshare.31801921.
Graph-Assisted Culturally Adaptable Idiomatic Translation for Indic Languages
May 28, 2025Translating multi-word expressions (MWEs) and idioms requires a deep understanding of the cultural nuances of both the source and target languages. This challenge is further amplified by the one-to-many nature of idiomatic translations, where a single source idiom can have multiple target-language equivalents depending on cultural references and contextual variations. Traditional static knowledge graphs (KGs) and prompt-based approaches struggle to capture these complex relationships, often leading to suboptimal translations. To address this, we propose IdiomCE, an adaptive graph neural network (GNN) based methodology that learns intricate mappings between idiomatic expressions, effectively generalizing to both seen and unseen nodes during training. Our proposed method enhances translation quality even in resource-constrained settings, facilitating improved idiomatic translation in smaller models. We evaluate our approach on multiple idiomatic translation datasets using reference-less metrics, demonstrating significant improvements in translating idioms from English to various Indian languages.
In-Domain African Languages Translation Using LLMs and Multi-armed Bandits
May 21, 2025Neural Machine Translation (NMT) systems face significant challenges when working with low-resource languages, particularly in domain adaptation tasks. These difficulties arise due to limited training data and suboptimal model generalization, As a result, selecting an optimal model for translation is crucial for achieving strong performance on in-domain data, particularly in scenarios where fine-tuning is not feasible or practical. In this paper, we investigate strategies for selecting the most suitable NMT model for a given domain using bandit-based algorithms, including Upper Confidence Bound, Linear UCB, Neural Linear Bandit, and Thompson Sampling. Our method effectively addresses the resource constraints by facilitating optimal model selection with high confidence. We evaluate the approach across three African languages and domains, demonstrating its robustness and effectiveness in both scenarios where target data is available and where it is absent.
Faster Machine Translation Ensembling with Reinforcement Learning and Competitive Correction
Jan 25, 2025



Ensembling neural machine translation (NMT) models to produce higher-quality translations than the $L$ individual models has been extensively studied. Recent methods typically employ a candidate selection block (CSB) and an encoder-decoder fusion block (FB), requiring inference across \textit{all} candidate models, leading to significant computational overhead, generally $\Omega(L)$. This paper introduces \textbf{SmartGen}, a reinforcement learning (RL)-based strategy that improves the CSB by selecting a small, fixed number of candidates and identifying optimal groups to pass to the fusion block for each input sentence. Furthermore, previously, the CSB and FB were trained independently, leading to suboptimal NMT performance. Our DQN-based \textbf{SmartGen} addresses this by using feedback from the FB block as a reward during training. We also resolve a key issue in earlier methods, where candidates were passed to the FB without modification, by introducing a Competitive Correction Block (CCB). Finally, we validate our approach with extensive experiments on English-Hindi translation tasks in both directions.
Multilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
Dec 24, 2024



Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini's accuracy on English datasets by +6% and matches Gemini's performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.
Enhancing LLMs for Physics Problem-Solving using Reinforcement Learning with Human-AI Feedback
Dec 06, 2024
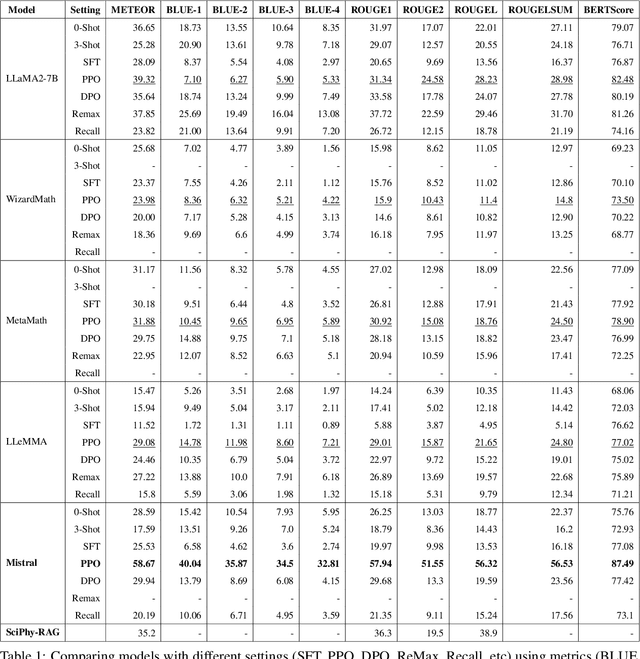
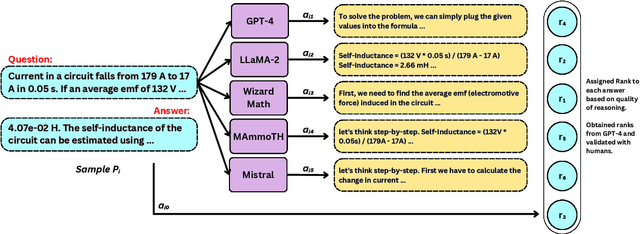
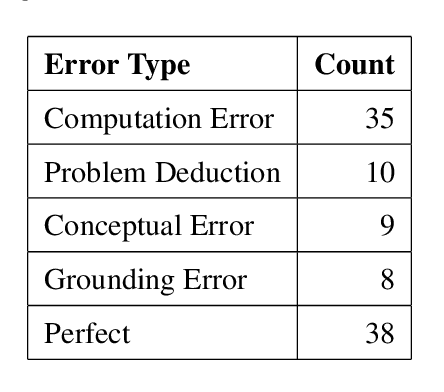
Large Language Models (LLMs) have demonstrated strong capabilities in text-based tasks but struggle with the complex reasoning required for physics problems, particularly in advanced arithmetic and conceptual understanding. While some research has explored ways to enhance LLMs in physics education using techniques such as prompt engineering and Retrieval Augmentation Generation (RAG), not enough effort has been made in addressing their limitations in physics reasoning. This paper presents a novel approach to improving LLM performance on physics questions using Reinforcement Learning with Human and Artificial Intelligence Feedback (RLHAIF). We evaluate several reinforcement learning methods, including Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), and Remax optimization. These methods are chosen to investigate RL policy performance with different settings on the PhyQA dataset, which includes challenging physics problems from high school textbooks. Our RLHAIF model, tested on leading LLMs like LLaMA2 and Mistral, achieved superior results, notably with the MISTRAL-PPO model, demonstrating marked improvements in reasoning and accuracy. It achieved high scores, with a 58.67 METEOR score and a 0.74 Reasoning score, making it a strong example for future physics reasoning research in this area.
Improving Multimodal LLMs Ability In Geometry Problem Solving, Reasoning, And Multistep Scoring
Dec 01, 2024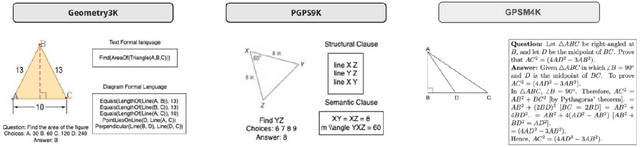
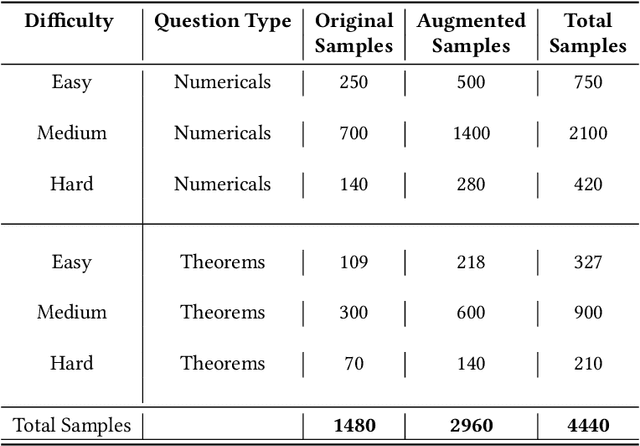
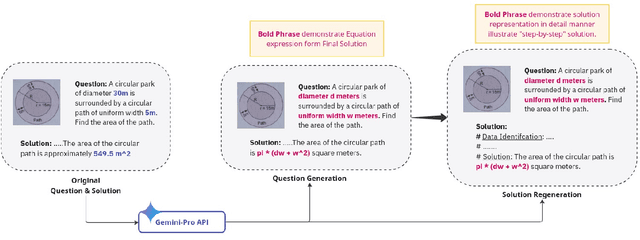
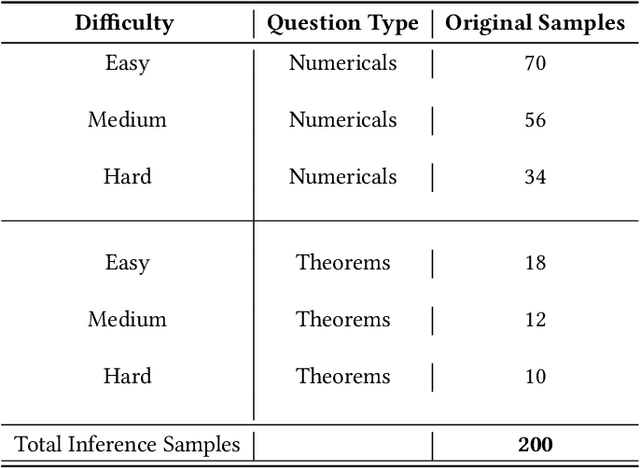
This paper presents GPSM4K, a comprehensive geometry multimodal dataset tailored to augment the problem-solving capabilities of Large Vision Language Models (LVLMs). GPSM4K encompasses 2157 multimodal question-answer pairs manually extracted from mathematics textbooks spanning grades 7-12 and is further augmented to 5340 problems, consisting of both numerical and theorem-proving questions. In contrast to PGPS9k, Geometry3K, and Geo170K which feature only objective-type questions, GPSM4K offers detailed step-by-step solutions in a consistent format, facilitating a comprehensive evaluation of problem-solving approaches. This dataset serves as an excellent benchmark for assessing the geometric reasoning capabilities of LVLMs. Evaluation of our test set shows that there is scope for improvement needed in open-source language models in geometry problem-solving. Finetuning on our training set increases the geometry problem-solving capabilities of models. Further, We also evaluate the effectiveness of techniques such as image captioning and Retrieval Augmentation generation (RAG) on model performance. We leveraged LLM to automate the task of final answer evaluation by providing ground truth and predicted solutions. This research will help to assess and improve the geometric reasoning capabilities of LVLMs.
Context-Enhanced Language Models for Generating Multi-Paper Citations
Apr 22, 2024Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
* 14 pages, 7 figures, 11th International Conference, BDA 2023, Delhi, India
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Apr 19, 2024The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called "MathQuest" sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
* 10 pages, 3 figures, NeurIPS 2023 Workshop on Generative AI for Education (GAIED)
KG-CTG: Citation Generation through Knowledge Graph-guided Large Language Models
Apr 15, 2024Citation Text Generation (CTG) is a task in natural language processing (NLP) that aims to produce text that accurately cites or references a cited document within a source document. In CTG, the generated text draws upon contextual cues from both the source document and the cited paper, ensuring accurate and relevant citation information is provided. Previous work in the field of citation generation is mainly based on the text summarization of documents. Following this, this paper presents a framework, and a comparative study to demonstrate the use of Large Language Models (LLMs) for the task of citation generation. Also, we have shown the improvement in the results of citation generation by incorporating the knowledge graph relations of the papers in the prompt for the LLM to better learn the relationship between the papers. To assess how well our model is performing, we have used a subset of standard S2ORC dataset, which only consists of computer science academic research papers in the English Language. Vicuna performs best for this task with 14.15 Meteor, 12.88 Rouge-1, 1.52 Rouge-2, and 10.94 Rouge-L. Also, Alpaca performs best, and improves the performance by 36.98% in Rouge-1, and 33.14% in Meteor by including knowledge graphs.