 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
Dec 24, 2024



Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini's accuracy on English datasets by +6% and matches Gemini's performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.
Enhancing LLMs for Physics Problem-Solving using Reinforcement Learning with Human-AI Feedback
Dec 06, 2024
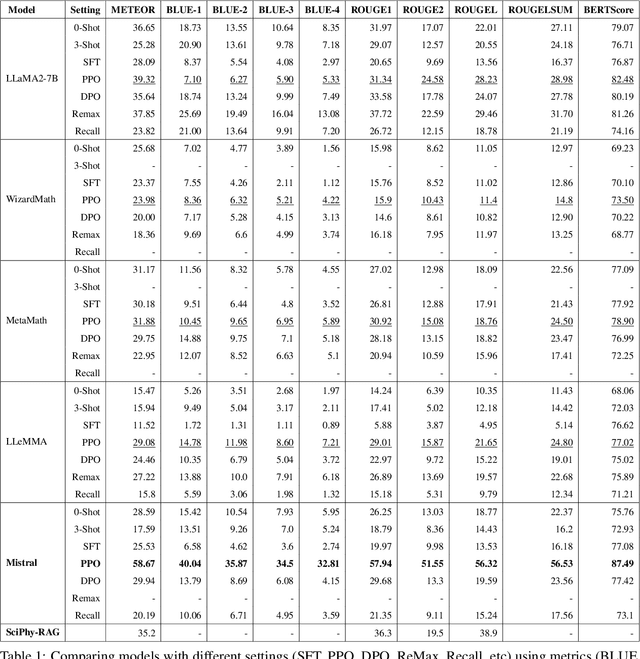
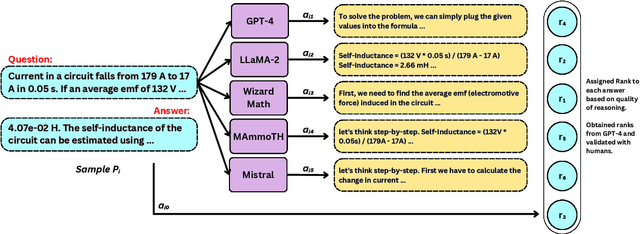
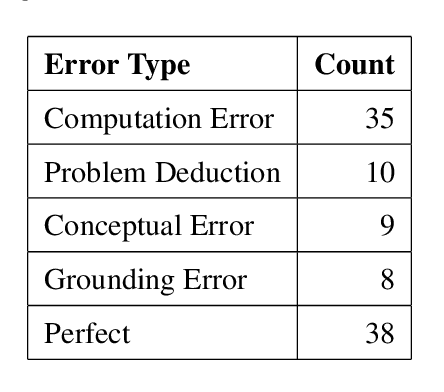
Large Language Models (LLMs) have demonstrated strong capabilities in text-based tasks but struggle with the complex reasoning required for physics problems, particularly in advanced arithmetic and conceptual understanding. While some research has explored ways to enhance LLMs in physics education using techniques such as prompt engineering and Retrieval Augmentation Generation (RAG), not enough effort has been made in addressing their limitations in physics reasoning. This paper presents a novel approach to improving LLM performance on physics questions using Reinforcement Learning with Human and Artificial Intelligence Feedback (RLHAIF). We evaluate several reinforcement learning methods, including Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), and Remax optimization. These methods are chosen to investigate RL policy performance with different settings on the PhyQA dataset, which includes challenging physics problems from high school textbooks. Our RLHAIF model, tested on leading LLMs like LLaMA2 and Mistral, achieved superior results, notably with the MISTRAL-PPO model, demonstrating marked improvements in reasoning and accuracy. It achieved high scores, with a 58.67 METEOR score and a 0.74 Reasoning score, making it a strong example for future physics reasoning research in this area.