 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Program Synthesis and Inductive Logic Programming to solve Bongard Problems
Oct 19, 2021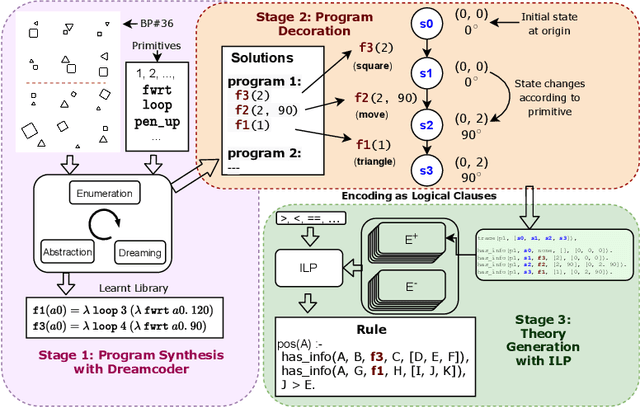

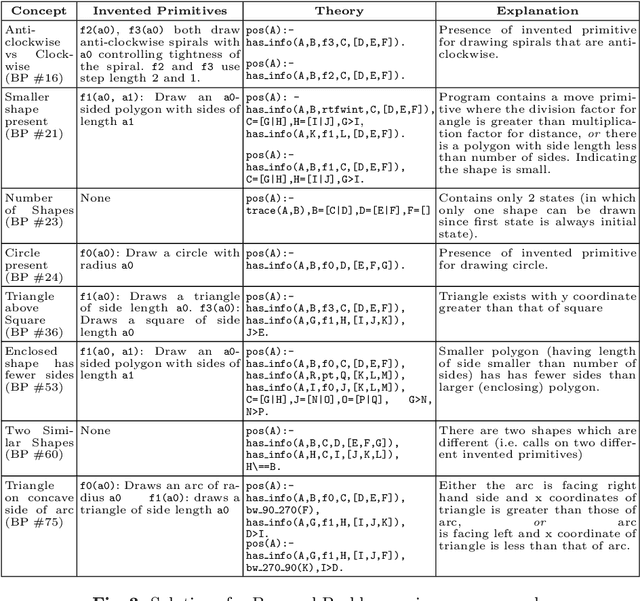
The ability to recognise and make analogies is often used as a measure or test of human intelligence. The ability to solve Bongard problems is an example of such a test. It has also been postulated that the ability to rapidly construct novel abstractions is critical to being able to solve analogical problems. Given an image, the ability to construct a program that would generate that image is one form of abstraction, as exemplified in the Dreamcoder project. In this paper, we present a preliminary examination of whether programs constructed by Dreamcoder can be used for analogical reasoning to solve certain Bongard problems. We use Dreamcoder to discover programs that generate the images in a Bongard problem and represent each of these as a sequence of state transitions. We decorate the states using positional information in an automated manner and then encode the resulting sequence into logical facts in Prolog. We use inductive logic programming (ILP), to learn an (interpretable) theory for the abstract concept involved in an instance of a Bongard problem. Experiments on synthetically created Bongard problems for concepts such as 'above/below' and 'clockwise/counterclockwise' demonstrate that our end-to-end system can solve such problems. We study the importance and completeness of each component of our approach, highlighting its current limitations and pointing to directions for improvement in our formulation as well as in elements of any Dreamcoder-like program synthesis system used for such an approach.
How to Tell Deep Neural Networks What We Know
Jul 21, 2021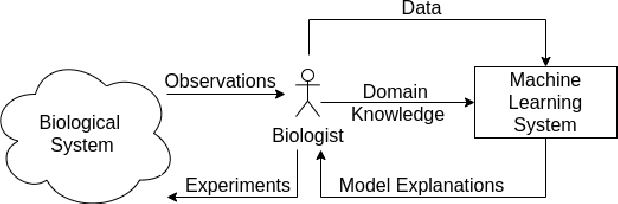
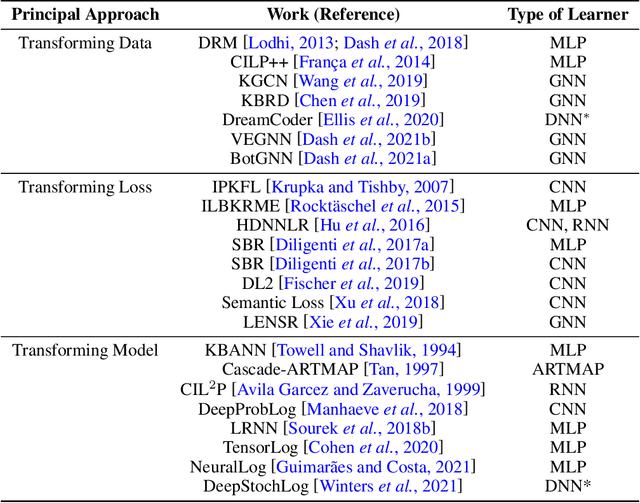
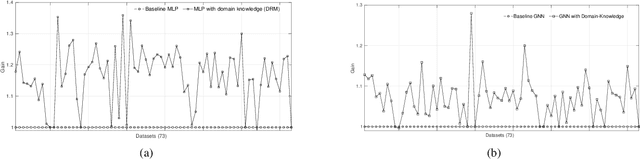
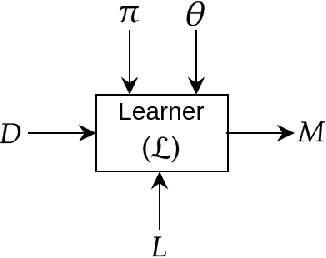
We present a short survey of ways in which existing scientific knowledge are included when constructing models with neural networks. The inclusion of domain-knowledge is of special interest not just to constructing scientific assistants, but also, many other areas that involve understanding data using human-machine collaboration. In many such instances, machine-based model construction may benefit significantly from being provided with human-knowledge of the domain encoded in a sufficiently precise form. This paper examines the inclusion of domain-knowledge by means of changes to: the input, the loss-function, and the architecture of deep networks. The categorisation is for ease of exposition: in practice we expect a combination of such changes will be employed. In each category, we describe techniques that have been shown to yield significant changes in network performance.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021
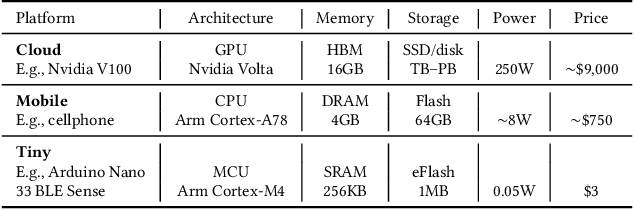

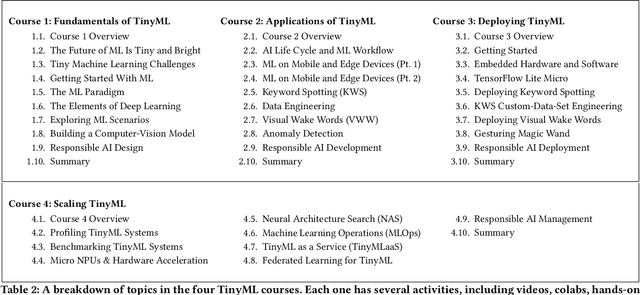
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
Improving Perception via Sensor Placement: Designing Multi-LiDAR Systems for Autonomous Vehicles
May 02, 2021
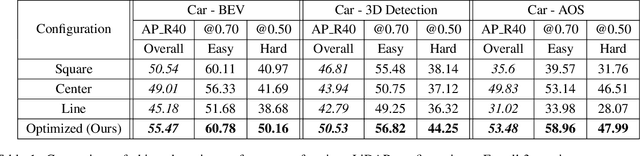
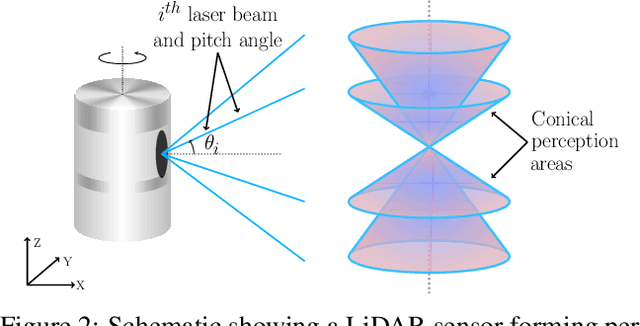
Recent years have witnessed an increasing interest in improving the perception performance of LiDARs on autonomous vehicles. While most of the existing works focus on developing novel model architectures to process point cloud data, we study the problem from an optimal sensing perspective. To this end, together with a fast evaluation function based on ray tracing within the perception region of a LiDAR configuration, we propose an easy-to-compute information-theoretic surrogate cost metric based on Probabilistic Occupancy Grids (POG) to optimize LiDAR placement for maximal sensing. We show a correlation between our surrogate function and common object detection performance metrics. We demonstrate the efficacy of our approach by verifying our results in a robust and reproducible data collection and extraction framework based on the CARLA simulator. Our results confirm that sensor placement is an important factor in 3D point cloud-based object detection and could lead to a variation of performance by 10% ~ 20% on the state-of-the-art perception algorithms. We believe that this is one of the first studies to use LiDAR placement to improve the performance of perception.
Incorporating Domain Knowledge into Deep Neural Networks
Mar 15, 2021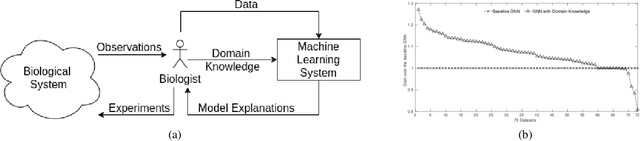
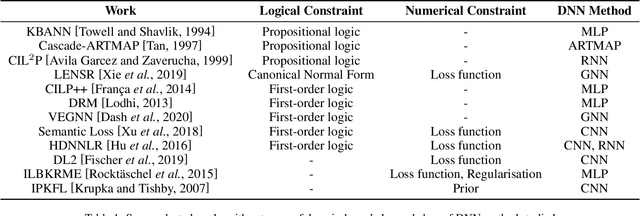
We present a survey of ways in which domain-knowledge has been included when constructing models with neural networks. The inclusion of domain-knowledge is of special interest not just to constructing scientific assistants, but also, many other areas that involve understanding data using human-machine collaboration. In many such instances, machine-based model construction may benefit significantly from being provided with human-knowledge of the domain encoded in a sufficiently precise form. This paper examines two broad approaches to encode such knowledge--as logical and numerical constraints--and describes techniques and results obtained in several sub-categories under each of these approaches.
Psychological and Neural Evidence for Reinforcement Learning: A Survey
Jun 25, 2020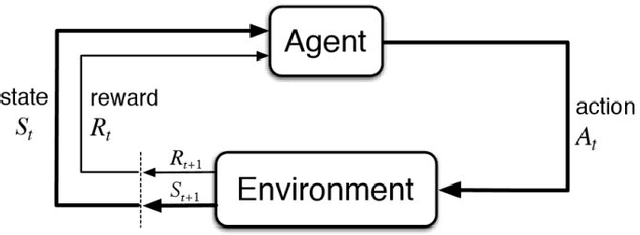
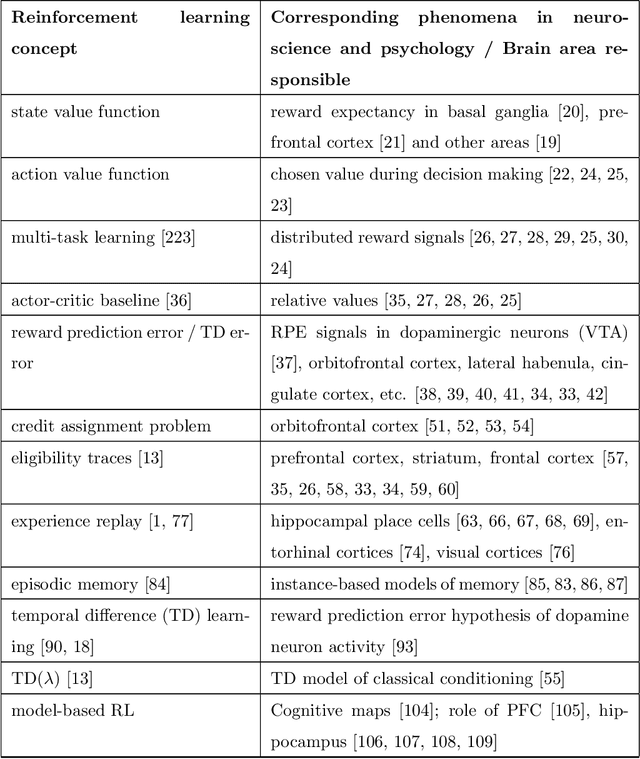
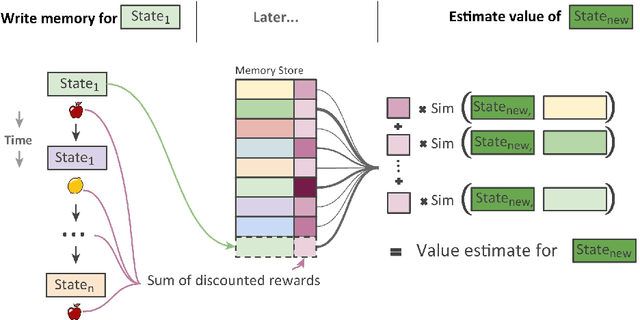
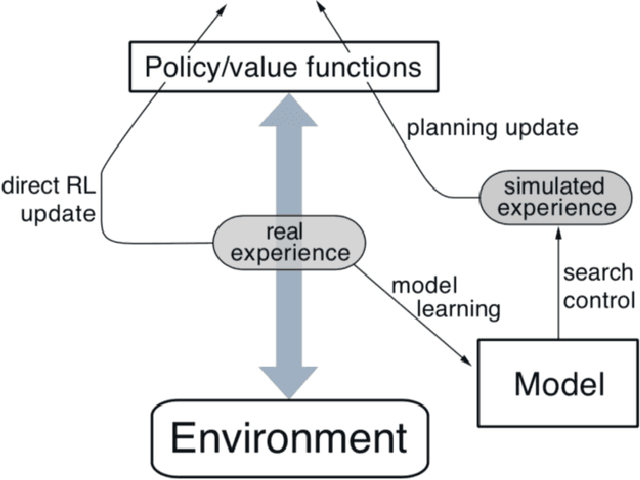
Reinforcement learning methods have been recently been very successful in complex sequential tasks like playing Atari games, Go and Poker. Through minimal input from humans, these algorithms are able to learn to perform complex tasks from scratch, just through interaction with their environment. While there certainly has been considerable independent innovation in the area, many core ideas in RL are inspired by animal learning and psychology. Moreover, these algorithms are now helping advance neuroscience research by serving as a computational model for many characteristic features of brain functioning. In this context, we review a number of findings that establish evidence of key elements of the RL problem and solution being represented in regions of the brain.
Quantized Reinforcement Learning (QUARL)
Oct 04, 2019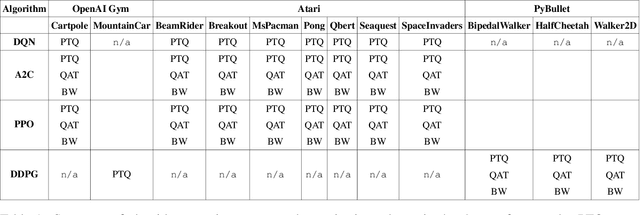
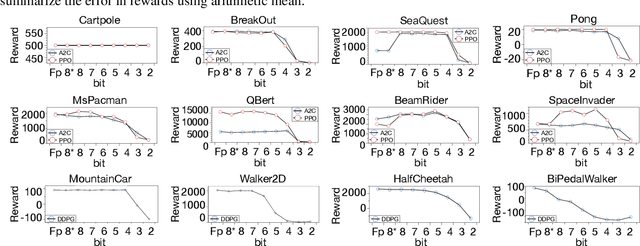


Recent work has shown that quantization can help reduce the memory, compute, and energy demands of deep neural networks without significantly harming their quality. However, whether these prior techniques, applied traditionally to image-based models, work with the same efficacy to the sequential decision making process in reinforcement learning remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the effects of quantization on various deep reinforcement learning policies with the intent to reduce their computational resource demands. We apply techniques such as post-training quantization and quantization aware training to a spectrum of reinforcement learning tasks (such as Pong, Breakout, BeamRider and more) and training algorithms (such as PPO, A2C, DDPG, and DQN). Across this spectrum of tasks and learning algorithms, we show that policies can be quantized to 6-8 bits of precision without loss of accuracy. We also show that certain tasks and reinforcement learning algorithms yield policies that are more difficult to quantize due to their effect of widening the models' distribution of weights and that quantization aware training consistently improves results over post-training quantization and oftentimes even over the full precision baseline. Finally, we demonstrate real-world applications of quantization for reinforcement learning. We use half-precision training to train a Pong model 50% faster, and we deploy a quantized reinforcement learning based navigation policy to an embedded system, achieving an 18$\times$ speedup and a 4$\times$ reduction in memory usage over an unquantized policy.