 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasheets for Machine Learning Sensors
Jun 15, 2023Machine learning (ML) sensors offer a new paradigm for sensing that enables intelligence at the edge while empowering end-users with greater control of their data. As these ML sensors play a crucial role in the development of intelligent devices, clear documentation of their specifications, functionalities, and limitations is pivotal. This paper introduces a standard datasheet template for ML sensors and discusses its essential components including: the system's hardware, ML model and dataset attributes, end-to-end performance metrics, and environmental impact. We provide an example datasheet for our own ML sensor and discuss each section in detail. We highlight how these datasheets can facilitate better understanding and utilization of sensor data in ML applications, and we provide objective measures upon which system performance can be evaluated and compared. Together, ML sensors and their datasheets provide greater privacy, security, transparency, explainability, auditability, and user-friendliness for ML-enabled embedded systems. We conclude by emphasizing the need for standardization of datasheets across the broader ML community to ensure the responsible and effective use of sensor data.
BELIEF in Dependence: Leveraging Atomic Linearity in Data Bits for Rethinking Generalized Linear Models
Oct 19, 2022
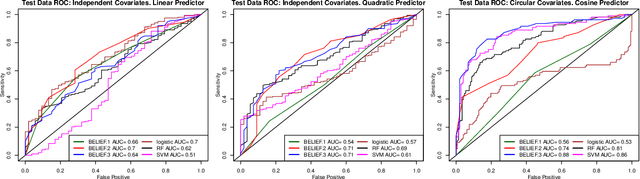
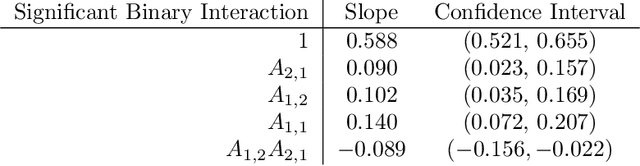
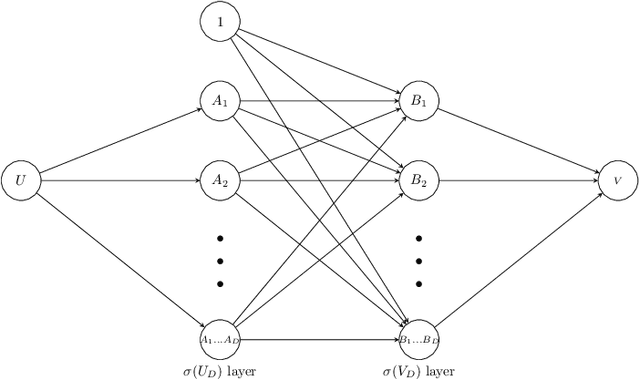
Two linearly uncorrelated binary variables must be also independent because non-linear dependence cannot manifest with only two possible states. This inherent linearity is the atom of dependency constituting any complex form of relationship. Inspired by this observation, we develop a framework called binary expansion linear effect (BELIEF) for assessing and understanding arbitrary relationships with a binary outcome. Models from the BELIEF framework are easily interpretable because they describe the association of binary variables in the language of linear models, yielding convenient theoretical insight and striking parallels with the Gaussian world. In particular, an algebraic structure on the predictors with nonzero slopes governs conditional independence properties. With BELIEF, one may study generalized linear models (GLM) through transparent linear models, providing insight into how modeling is affected by the choice of link. For example, setting a GLM interaction coefficient to zero does not necessarily lead to the kind of no-interaction model assumption as understood under their linear model counterparts. Furthermore, for a binary response, maximum likelihood estimation for GLMs paradoxically fails under complete separation, when the data are most discriminative, whereas BELIEF estimation automatically reveals the perfect predictor in the data that is responsible for complete separation. We explore these phenomena and provide a host of related theoretical results. We also provide preliminary empirical demonstration and verification of some theoretical results.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021
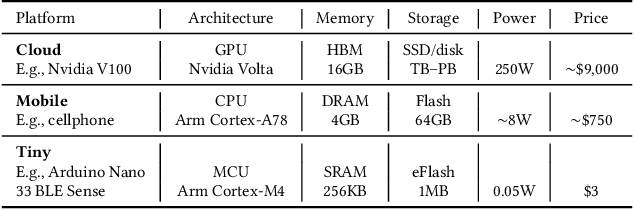

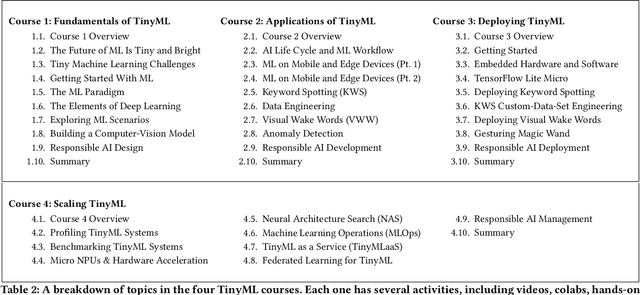
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
MEBoost: Variable Selection in the Presence of Measurement Error
Oct 25, 2017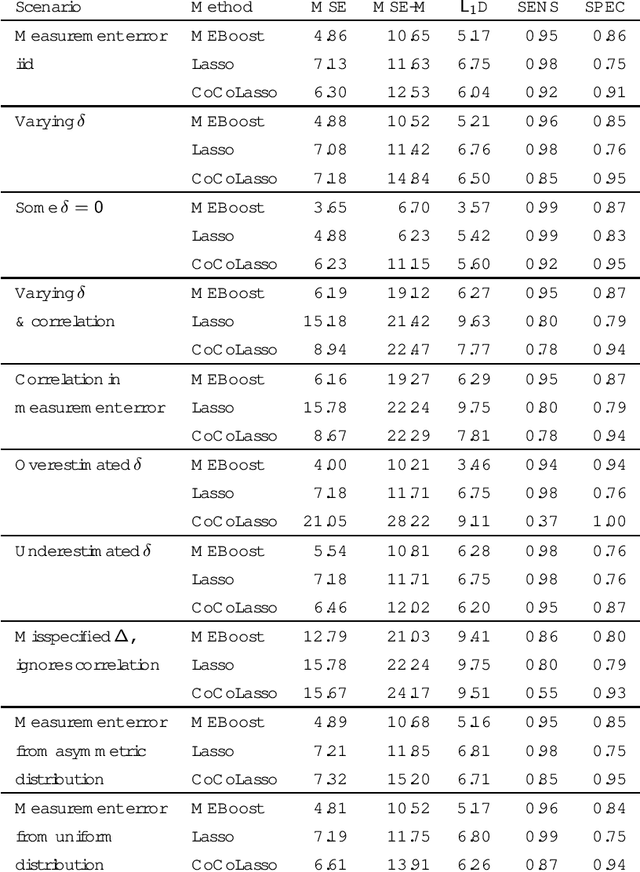
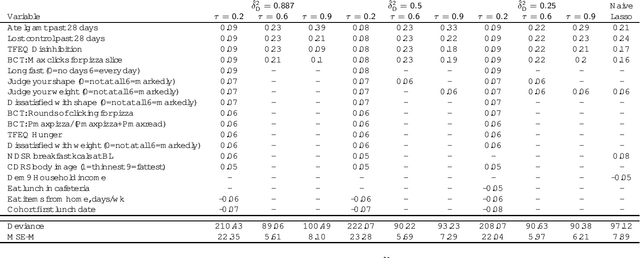
We present a novel method for variable selection in regression models when covariates are measured with error. The iterative algorithm we propose, MEBoost, follows a path defined by estimating equations that correct for covariate measurement error. Via simulation, we evaluated our method and compare its performance to the recently-proposed Convex Conditioned Lasso (CoCoLasso) and to the "naive" Lasso which does not correct for measurement error. Increasing the degree of measurement error increased prediction error and decreased the probability of accurate covariate selection, but this loss of accuracy was least pronounced when using MEBoost. We illustrate the use of MEBoost in practice by analyzing data from the Box Lunch Study, a clinical trial in nutrition where several variables are based on self-report and hence measured with error.