 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time, Energy-Efficient, Sampling-Based Optimal Control via FPGA Acceleration
Jan 23, 2026Autonomous mobile robots (AMRs), used for search-and-rescue and remote exploration, require fast and robust planning and control schemes. Sampling-based approaches for Model Predictive Control, especially approaches based on the Model Predictive Path Integral Control (MPPI) algorithm, have recently proven both to be highly effective for such applications and to map naturally to GPUs for hardware acceleration. However, both GPU and CPU implementations of such algorithms can struggle to meet tight energy and latency budgets on battery-constrained AMR platforms that leverage embedded compute. To address this issue, we present an FPGA-optimized MPPI design that exposes fine-grained parallelism and eliminates synchronization bottlenecks via deep pipelining and parallelism across algorithmic stages. This results in an average 3.1x to 7.5x speedup over optimized implementations on an embedded GPU and CPU, respectively, while simultaneously achieving a 2.5x to 5.4x reduction in energy usage. These results demonstrate that FPGA architectures are a promising direction for energy-efficient and high-performance edge robotics.
TAG-K: Tail-Averaged Greedy Kaczmarz for Computationally Efficient and Performant Online Inertial Parameter Estimation
Oct 06, 2025



Accurate online inertial parameter estimation is essential for adaptive robotic control, enabling real-time adjustment to payload changes, environmental interactions, and system wear. Traditional methods such as Recursive Least Squares (RLS) and the Kalman Filter (KF) often struggle to track abrupt parameter shifts or incur high computational costs, limiting their effectiveness in dynamic environments and for computationally constrained robotic systems. As such, we introduce TAG-K, a lightweight extension of the Kaczmarz method that combines greedy randomized row selection for rapid convergence with tail averaging for robustness under noise and inconsistency. This design enables fast, stable parameter adaptation while retaining the low per-iteration complexity inherent to the Kaczmarz framework. We evaluate TAG-K in synthetic benchmarks and quadrotor tracking tasks against RLS, KF, and other Kaczmarz variants. TAG-K achieves 1.5x-1.9x faster solve times on laptop-class CPUs and 4.8x-20.7x faster solve times on embedded microcontrollers. More importantly, these speedups are paired with improved resilience to measurement noise and a 25% reduction in estimation error, leading to nearly 2x better end-to-end tracking performance.
Set Phasers to Stun: Beaming Power and Control to Mobile Robots with Laser Light
Apr 24, 2025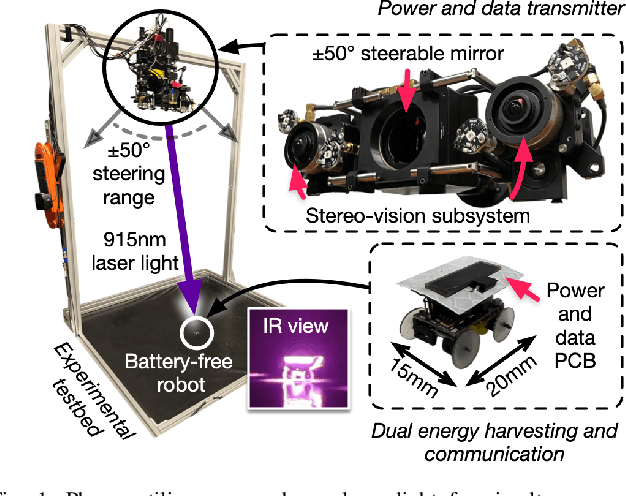
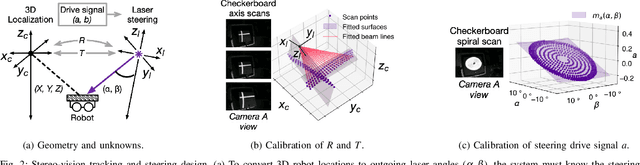
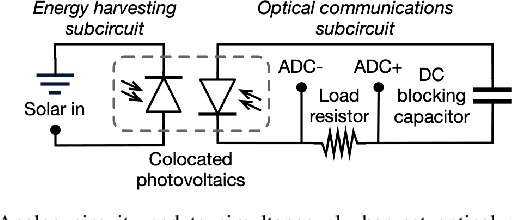
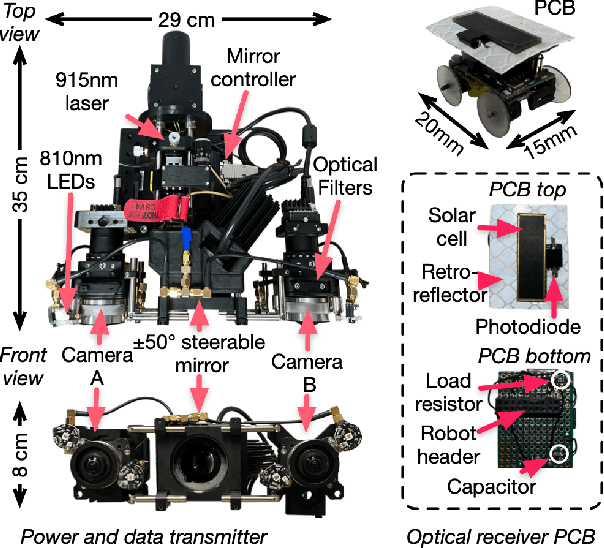
We present Phaser, a flexible system that directs narrow-beam laser light to moving robots for concurrent wireless power delivery and communication. We design a semi-automatic calibration procedure to enable fusion of stereo-vision-based 3D robot tracking with high-power beam steering, and a low-power optical communication scheme that reuses the laser light as a data channel. We fabricate a Phaser prototype using off-the-shelf hardware and evaluate its performance with battery-free autonomous robots. Phaser delivers optical power densities of over 110 mW/cm$^2$ and error-free data to mobile robots at multi-meter ranges, with on-board decoding drawing 0.3 mA (97\% less current than Bluetooth Low Energy). We demonstrate Phaser fully powering gram-scale battery-free robots to nearly 2x higher speeds than prior work while simultaneously controlling them to navigate around obstacles and along paths. Code, an open-source design guide, and a demonstration video of Phaser is available at https://mobilex.cs.columbia.edu/phaser.
pRRTC: GPU-Parallel RRT-Connect for Fast, Consistent, and Low-Cost Motion Planning
Mar 09, 2025



Sampling-based motion planning algorithms, like the Rapidly-Exploring Random Tree (RRT) and its widely used variant, RRT-Connect, provide efficient solutions for high-dimensional planning problems faced by real-world robots. However, these methods remain computationally intensive, particularly in complex environments that require many collision checks. As such, to improve performance, recent efforts have explored parallelizing specific components of RRT, such as collision checking or running multiple planners independently, but no prior work has integrated parallelism at multiple levels of the algorithm for robotic manipulation. In this work, we present pRRTC, a GPU-accelerated implementation of RRT-Connect that achieves parallelism across the entire algorithm through multithreaded expansion and connection, SIMT-optimized collision checking, and hierarchical parallelism optimization, improving efficiency, consistency, and initial solution cost. We evaluate the effectiveness of pRRTC on the MotionBenchMaker dataset using robots with 7, 8, and 14 degrees-of-freedom, demonstrating up to 6x average speedup on constrained reaching tasks at high collision checking resolution compared to state-of-the-art. pRRTC also demonstrates a 5x reduction in solution time variance and 1.5x improvement in initial path costs compared to state-of-the-art motion planners in complex environments across all robots.
The Magnificent Seven Challenges and Opportunities in Domain-Specific Accelerator Design for Autonomous Systems
Jul 24, 2024
The end of Moore's Law and Dennard Scaling has combined with advances in agile hardware design to foster a golden age of domain-specific acceleration. However, this new frontier of computing opportunities is not without pitfalls. As computer architects approach unfamiliar domains, we have seen common themes emerge in the challenges that can hinder progress in the development of useful acceleration. In this work, we present the Magnificent Seven Challenges in domain-specific accelerator design that can guide adventurous architects to contribute meaningfully to novel application domains. Although these challenges appear across domains ranging from ML to genomics, we examine them through the lens of autonomous systems as a motivating example in this work. To that end, we identify opportunities for the path forward in a successful domain-specific accelerator design from these challenges.
Code Generation for Conic Model-Predictive Control on Microcontrollers with TinyMPC
Mar 26, 2024



Conic constraints appear in many important control applications like legged locomotion, robotic manipulation, and autonomous rocket landing. However, current solvers for conic optimization problems have relatively heavy computational demands in terms of both floating-point operations and memory footprint, making them impractical for use on small embedded devices. We extend TinyMPC, an open-source, high-speed solver targeting low-power embedded control applications, to handle second-order cone constraints. We also present code-generation software to enable deployment of TinyMPC on a variety of microcontrollers. We benchmark our generated code against state-of-the-art embedded QP and SOCP solvers, demonstrating a two-order-of-magnitude speed increase over ECOS while consuming less memory. Finally, we demonstrate TinyMPC's efficacy on the Crazyflie, a lightweight, resource-constrained quadrotor with fast dynamics. TinyMPC and its code-generation tools are publicly available at https://tinympc.org.
TinyMPC: Model-Predictive Control on Resource-Constrained Microcontrollers
Oct 25, 2023Model-predictive control (MPC) is a powerful tool for controlling highly dynamic robotic systems subject to complex constraints. However, MPC is computationally demanding, and is often impractical to implement on small, resource-constrained robotic platforms. We present TinyMPC, a high-speed MPC solver with a low memory footprint targeting the microcontrollers common on small robots. Our approach is based on the alternating direction method of multipliers (ADMM) and leverages the structure of the MPC problem for efficiency. We demonstrate TinyMPC both by benchmarking against the state-of-the-art solver OSQP, achieving nearly an order of magnitude speed increase, as well as through hardware experiments on a 27 g quadrotor, demonstrating high-speed trajectory tracking and dynamic obstacle avoidance.
Differentially Encoded Observation Spaces for Perceptive Reinforcement Learning
Oct 03, 2023


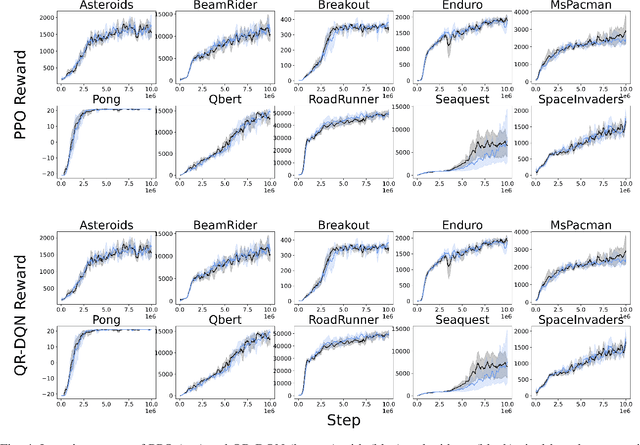
Perceptive deep reinforcement learning (DRL) has lead to many recent breakthroughs for complex AI systems leveraging image-based input data. Applications of these results range from super-human level video game agents to dexterous, physically intelligent robots. However, training these perceptive DRL-enabled systems remains incredibly compute and memory intensive, often requiring huge training datasets and large experience replay buffers. This poses a challenge for the next generation of field robots that will need to be able to learn on the edge in order to adapt to their environments. In this paper, we begin to address this issue through differentially encoded observation spaces. By reinterpreting stored image-based observations as a video, we leverage lossless differential video encoding schemes to compress the replay buffer without impacting training performance. We evaluate our approach with three state-of-the-art DRL algorithms and find that differential image encoding reduces the memory footprint by as much as 14.2x and 16.7x across tasks from the Atari 2600 benchmark and the DeepMind Control Suite (DMC) respectively. These savings also enable large-scale perceptive DRL that previously required paging between flash and RAM to be run entirely in RAM, improving the latency of DMC tasks by as much as 32%.
RobotPerf: An Open-Source, Vendor-Agnostic, Benchmarking Suite for Evaluating Robotics Computing System Performance
Sep 17, 2023
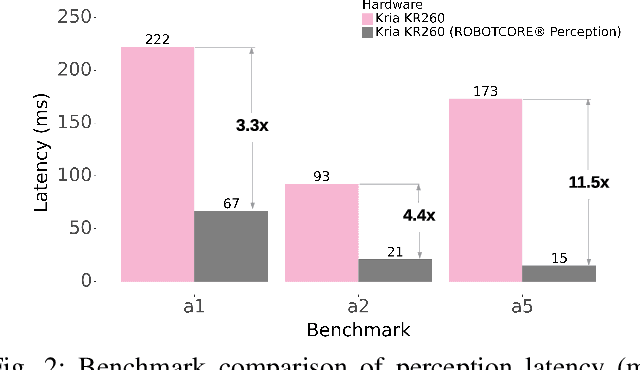

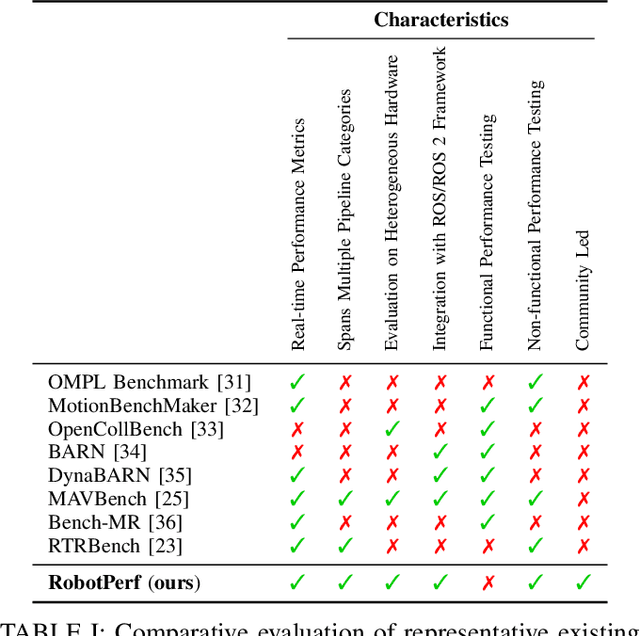
We introduce RobotPerf, a vendor-agnostic benchmarking suite designed to evaluate robotics computing performance across a diverse range of hardware platforms using ROS 2 as its common baseline. The suite encompasses ROS 2 packages covering the full robotics pipeline and integrates two distinct benchmarking approaches: black-box testing, which measures performance by eliminating upper layers and replacing them with a test application, and grey-box testing, an application-specific measure that observes internal system states with minimal interference. Our benchmarking framework provides ready-to-use tools and is easily adaptable for the assessment of custom ROS 2 computational graphs. Drawing from the knowledge of leading robot architects and system architecture experts, RobotPerf establishes a standardized approach to robotics benchmarking. As an open-source initiative, RobotPerf remains committed to evolving with community input to advance the future of hardware-accelerated robotics.
MPCGPU: Real-Time Nonlinear Model Predictive Control through Preconditioned Conjugate Gradient on the GPU
Sep 15, 2023Nonlinear Model Predictive Control (NMPC) is a state-of-the-art approach for locomotion and manipulation which leverages trajectory optimization at each control step. While the performance of this approach is computationally bounded, implementations of direct trajectory optimization that use iterative methods to solve the underlying moderately-large and sparse linear systems, are a natural fit for parallel hardware acceleration. In this work, we introduce MPCGPU, a GPU-accelerated, real-time NMPC solver that leverages an accelerated preconditioned conjugate gradient (PCG) linear system solver at its core. We show that MPCGPU increases the scalability and real-time performance of NMPC, solving larger problems, at faster rates. In particular, for tracking tasks using the Kuka IIWA manipulator, MPCGPU is able to scale to kilohertz control rates with trajectories as long as 512 knot points. This is driven by a custom PCG solver which outperforms state-of-the-art, CPU-based, linear system solvers by at least 10x for a majority of solves and 3.6x on average.