 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Encoded Observation Spaces for Perceptive Reinforcement Learning
Oct 03, 2023


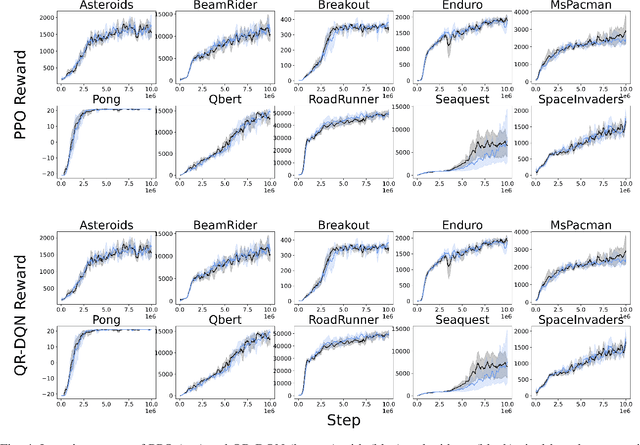
Perceptive deep reinforcement learning (DRL) has lead to many recent breakthroughs for complex AI systems leveraging image-based input data. Applications of these results range from super-human level video game agents to dexterous, physically intelligent robots. However, training these perceptive DRL-enabled systems remains incredibly compute and memory intensive, often requiring huge training datasets and large experience replay buffers. This poses a challenge for the next generation of field robots that will need to be able to learn on the edge in order to adapt to their environments. In this paper, we begin to address this issue through differentially encoded observation spaces. By reinterpreting stored image-based observations as a video, we leverage lossless differential video encoding schemes to compress the replay buffer without impacting training performance. We evaluate our approach with three state-of-the-art DRL algorithms and find that differential image encoding reduces the memory footprint by as much as 14.2x and 16.7x across tasks from the Atari 2600 benchmark and the DeepMind Control Suite (DMC) respectively. These savings also enable large-scale perceptive DRL that previously required paging between flash and RAM to be run entirely in RAM, improving the latency of DMC tasks by as much as 32%.
Just Round: Quantized Observation Spaces Enable Memory Efficient Learning of Dynamic Locomotion
Oct 14, 2022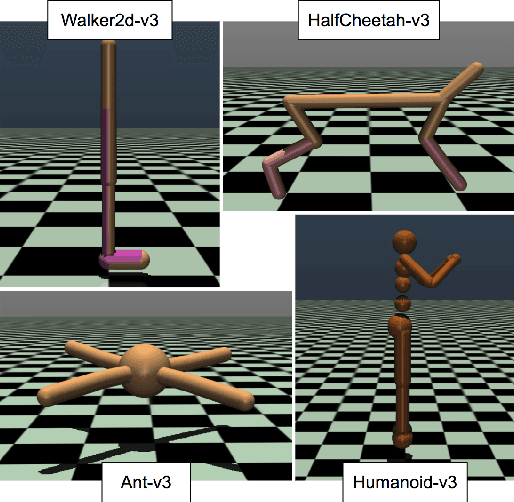
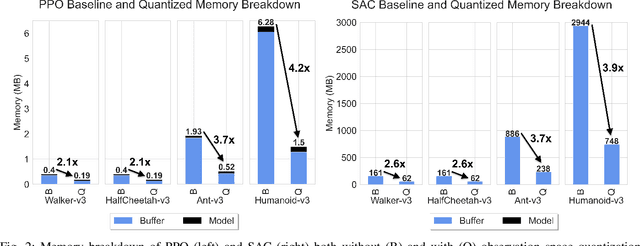
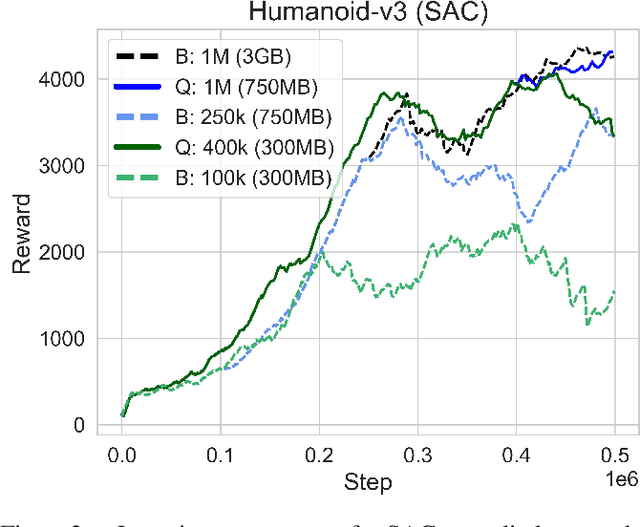
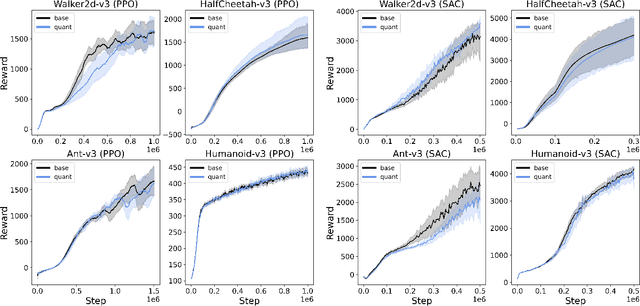
Deep reinforcement learning (DRL) is one of the most powerful tools for synthesizing complex robotic behaviors. But training DRL models is incredibly compute and memory intensive, requiring large training datasets and replay buffers to achieve performant results. This poses a challenge for the next generation of field robots that will need to learn on the edge to adapt to their environment. In this paper, we begin to address this issue through observation space quantization. We evaluate our approach using four simulated robot locomotion tasks and two state-of-the-art DRL algorithms, the on-policy Proximal Policy Optimization (PPO) and off-policy Soft Actor-Critic (SAC) and find that observation space quantization reduces overall memory costs by as much as 4.2x without impacting learning performance.
A Comparison of Action Spaces for Learning Manipulation Tasks
Aug 23, 2019



Designing reinforcement learning (RL) problems that can produce delicate and precise manipulation policies requires careful choice of the reward function, state, and action spaces. Much prior work on applying RL to manipulation tasks has defined the action space in terms of direct joint torques or reference positions for a joint-space proportional derivative (PD) controller. In practice, it is often possible to add additional structure by taking advantage of model-based controllers that support both accurate positioning and control of the dynamic response of the manipulator. In this paper, we evaluate how the choice of action space for dynamic manipulation tasks affects the sample complexity as well as the final quality of learned policies. We compare learning performance across three tasks (peg insertion, hammering, and pushing), four action spaces (torque, joint PD, inverse dynamics, and impedance control), and using two modern reinforcement learning algorithms (Proximal Policy Optimization and Soft Actor-Critic). Our results lend support to the hypothesis that learning references for a task-space impedance controller significantly reduces the number of samples needed to achieve good performance across all tasks and algorithms.